多线程-ConcurrentHashMap源码详解
目录:
概述
ConcurrentHashMap实现原理
成员变量
构造函数
原子方法
HashEntry源码
Segment源码
scanAndLockForPut源码
put源码
rehash源码
scanAndLock源码
remove源码
replace操作源码
get操作源码
isEmpty源码
size源码
containsValue源码
弱一致性问题
返回目录
概述:
HashMap是集合中最常用的数据结构之一,由于HashMap非线程安全,因此不能用于并发访问场景。在jdk1.5之前,通常使用HashTable作为HashMap的线程安全版本。HashMap对读写操作进行全局加锁,在高并发的条件下会造成严重的锁竞争和等待,极大地降低了系统的吞吐量。
优点:
相比于HashTable以及Collections.synchronizedMap(),ConcurrentHashMap在线程安全的的基础上提供了更好的写并发能力,并且读操作(get)通常不会阻塞,使得读写操作可并发执行,支持客户端修改ConcurrenHashMap的并发访问度,迭代期间也不会抛出ConcurrentModificationException等等。
缺点:
一致性问题:这是当前所有分布式系统都面临的问题。
注意:
- ConcurrentHashMap中key和value值都不能为null,HashMap中key可以为null,HashTable中key不能为null。
- ConcurrentHashMap是线程安全的类并不能保证使用ConcurrentHashMap的操作都是线程安全的。
返回目录
ConcurrentHashMap实现原理:
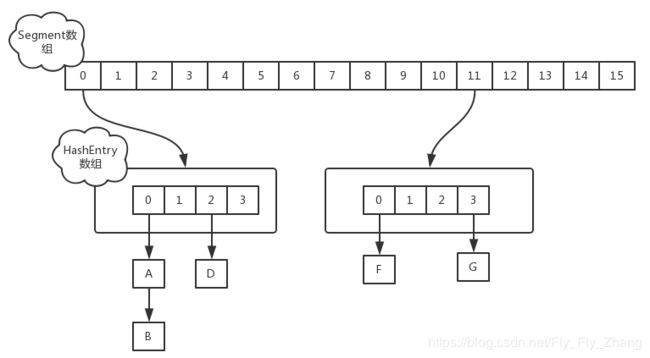
ConcurrentHashMap的基本策略是将table细分为多个Segment保存在数组segments中,每个Segment本身又是一个可并发的哈希表,同时每个Segment都是一把ReentrantLock锁,只有在同一个Segment内才存在竞争关系,不同的Segment之间没有锁竞争,这就是分段锁机制。Segment内部拥有一个HashEntry数组,数组中的每个元素又是一个链表。
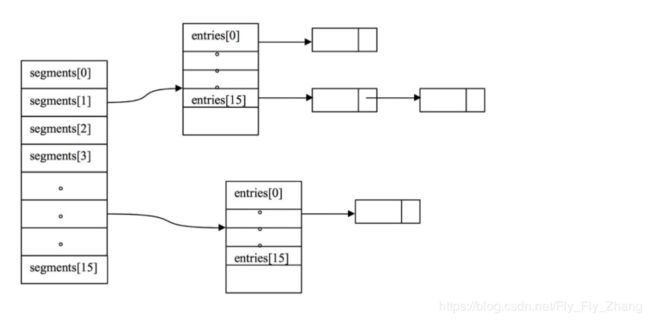
为了减少占用空间,除了第一个Segment之外,剩余的Segment采用的是延迟初始化的机制,仅在第一次需要时才会创建(ensureSegment实现) 为了保证延迟初始化存在的可见性,访问segments数组以及table数组的元素,均通过volatile访问,主要借助于Unsafe中原子操作getObjectVolatile来实现,此外,segments中segment的写入以及table中元素和next域的写入均使用UNSAFE.putOrderedObject来完成。这些操作提供了AtomicReferenceArrays的功能。
源码解析:
继承关系:
public class ConcurrentHashMap<K, V>
extends AbstractMap<K, V> //集合一些基本功能的实现
implements ConcurrentMap<K, V>, //需要实现几个删除添加操作
Serializable { //序列化
返回目录
成员变量:
static final int DEFAULT_INITIAL_CAPACITY = 16; //默认容量,作用于segment的table属性
static final float DEFAULT_LOAD_FACTOR = 0.75f; //加载因子
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
//默认并发度,该参数影响segments数组的长度
static final int MAXIMUM_CAPACITY = 1 << 30; //最大容量
//作用于segment中table数组的最大值, table.length
//table的大小必须是2的幂,且小于等于1<<30 ,以确保不超过int的范围来索引条目
static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
//table数组的最小长度,必须是2的幂,至少为2以免延迟构造后立即调整大小
static final int MAX_SEGMENTS = 1 << 16; // slightly conservative
//允许的最大segment数量,用于限定构造函数参数concurrent_level的边界
//也就是最大允许的线程数量。
static final int RETRIES_BEFORE_LOCK = 2;
//非锁定情况下调用size和containsValue方法的重试次数,
//避免由于table连续修改导致无限重试,次数超过则对全局加锁。
private transient final int hashSeed = randomHashSeed(this);
//和当前相关联,用于keyhash的随机值,用来减少hash冲突
private static int randomHashSeed(ConcurrentHashMap instance) {
if (sun.misc.VM.isBooted() && Holder.ALTERNATIVE_HASHING) {
return sun.misc.Hashing.randomHashSeed(instance);
}
return 0;
}
final int segmentMask;
//用于索引segment的掩码值(只留下高位),key高位hash码用来选择segment
final int segmentShift; //用来索引segment偏移值
final Segment<K,V>[] segments; //数组+数组+链表 //segments创建后其容量不可变
transient Set<K> keySet;
transient Set<Map.Entry<K,V>> entrySet;
transient Collection<V> values;
返回目录
构造函数:
- initialCapacity: 创建ConcurrentHashMap对象的初始容量,即HashEntity的总数量,创建时未指定initialCapacity默认16 ,最大容量为MAXIMUM_CAPACITY.
- LoadFactor: 负载因子,用于计算Segment的threshlod域
- concurrencyLevel: 即ConcurrentHashMap的并发度,支持同时更新ConccurentHashMap且不发生锁竞争的最大线程数。 但是其并不代表实际并发度,因为会使用大于等于该值的2的幂指数的最小值作为实际并发度,实际并发度即为segments数组的长度。如未指定则默认为16 ;
注意:并发度对ConcurrentHashMap性能具有举足轻重的作用,如果并发度设置过小,会带来严重的锁竞争问题;如果并发度设置过大,原本位于同一个Segment内的访问会扩散到不同的Segment中,CPU cache命中率会下降,从而引起程序性能下降。
@SuppressWarnings("unchecked")
//有参构造
public ConcurrentHashMap(int initialCapacity, //指定容量
float loadFactor, int concurrencyLevel) {
//加载因子和最大线程容量
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
//给定线程容量大于默认最大容量,采用默认最大容量
concurrencyLevel = MAX_SEGMENTS;
/*
* 寻找与给定参数concurrencylevel匹配的最佳数组ssize,
* 必须是2的幂,如果concurrencylevel是2的幂,那么ssize就是
* concurrencyevel,否则concurrencylevel为ssize大于concurrency最小2的幂
*例 : concurrencyLevel为7,则ssize为2^3=8;
*/
// Find power-of-two sizes best matching arguments
int sshift = 0; //记录左移次数,用来计算segment最大偏移值
int ssize = 1; //segment数组长度,也是最大线程数量
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1; //采用位运算而不是直接使用concurrenylevel,
//因为此值可能不一定是2的幂
}
this.segmentShift = 32 - sshift; //索引偏移量
this.segmentMask = ssize - 1; //-1是为了将低位二进制全部变1,达到掩码目的
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//给定容量大于默认最大容量,采用默认最大容量
// 防止索引条目超出int值范围
int c = initialCapacity / ssize; //每个table数组的最大容量
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY; //table数组最小长度
while (cap < c) //因为必须是2的幂,所以采用此方式,保证cap最终是比c的2的幂函数
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 = //创建segments和第一个segment
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize]; //segments
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
//指定最大容量和加载因子
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap(int initialCapacity) { //指定最大容量
this(initialCapacity, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
public ConcurrentHashMap() { //默认构造
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
//由一个集合构建
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
//集合元素数量处以加载因子就是当前集合容量
DEFAULT_INITIAL_CAPACITY), //默认容量,两个去最大值
DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL); //默认加载因子,默认并发度
putAll(m); //将集合中元素添加到当前集合中
}
返回目录
原子方法:
ConcurrentHashMap主要使用下面几个方法对segments数组和table数组进行读写,并且保证线程安全性。
其主要使用了UNSAFE.getObjectVolatile提供的volatile读语义,UNSAFE.putObjectVolatile提供了Volatile写语义。
使用其好处为:
- UNSAFE.getObjectVolatile使得非volatile声明的对象具有volatile读的语义
- 要使非volatile声明的对象具有volatile写语义则需要借助操作UNSAFE.putObjectvolatile
UNSAFE.putOrderedObject操作的含义和作用是什么:
为了控制特定条件下的指令重排序和内存可见性问题,java编辑器使用了内存屏障的CPU指令来禁止指令重排序。java中volatile写入使用了内存的屏障中的LoadStore屏障规则,对于 Load1->LoadStore->Store2, 在Store2以及后续写入操作被刷出之前,要保证Load1要读取的数据被读取完毕。
volatile的写所插入的storeLoad是一个耗时的操作,因此出现了一个对volatile写的升级版本,利用lazySet方法对性能进行优化,在实现上对volatile的写只会在之前插入storestore屏障,对于这样的Store1 ;StoreStore;Store2,在store2及后续写入操作执行前,保证store1的写入对其它处理器是可见,也就是按顺序写入。 UNSAFE.putOrderedObject正是提供了这样的语义,避免了写写指定重排序,但是不保证内存可见性,因此需要借助volatile读来保证可见性。
ConcurrentHashMap正是利用了这些高性能的原子读写来避免加锁带来的开销。
// 获取给定table的第i个元素,使用volatile读语义。
@SuppressWarnings("unchecked")
static final <K,V> HashEntry<K,V> entryAt(HashEntry<K,V>[] tab, int i) {
return (tab == null) ? null :
(HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)i << TSHIFT) + TBASE);
}
/**
* Sets the ith element of given table, with volatile write
* semantics. (See above about use of putOrderedObject.)
*/
//设置给定table的第i个元素,使用volatile写入语义
static final <K,V> void setEntryAt(HashEntry<K,V>[] tab, int i,
HashEntry<K,V> e) {
UNSAFE.putOrderedObject(tab, ((long)i << TSHIFT) + TBASE, e);
}
/*
* 通过Unsafe提供的具有volatile元素访问语义的操作获取Segment数组的第j个元素(如果ss为空)
* 注意:因为Segment数组的每个元素只能设置一次(使用完全有序的写入)
* 所以,一些性能敏感的方法只能依靠此方法作为对空读取的重新检查。
*/
@SuppressWarnings("unchecked")
static final <K,V> Segment<K,V> segmentAt(Segment<K,V>[] ss, int j) {
long u = (j << SSHIFT) + SBASE;
return ss == null ? null :
(Segment<K,V>) UNSAFE.getObjectVolatile(ss, u);
}
/*
* 根据给定的Hash获取segment
*/
@SuppressWarnings("unchecked")
private Segment<K,V> segmentForHash(int h) {
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
return (Segment<K,V>) UNSAFE.getObjectVolatile(segments, u);
}
/*
* 根据给定的segment和hash获取table entry 一条链表
*/
@SuppressWarnings("unchecked")
static final <K,V> HashEntry<K,V> entryForHash(Segment<K,V> seg, int h) {
HashEntry<K,V>[] tab;
return (seg == null || (tab = seg.table) == null) ? null :
(HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
}
返回目录
HashEntry:内部类,用来存储key-value的数据结构
注意:value和next声明为volatile,是为了保证内存的可见性,也就是保证读取的值都是最新的值,而不会从缓存读取。 写入next域使用volatile写入是为了保证原子性。写入使用原子性操作,读取使用volatile,保证多线程访问的安全性。
//存储key-value的数据结构,
static final class HashEntry<K,V> {
final int hash; //hash值
final K key;
volatile V value; //全局可见,用来实现containsValue方法
volatile HashEntry<K,V> next; //全局可见,netxt节点
//初始化一个节点
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
设置下一节点
final void setNext(HashEntry<K,V> n) { //原子性设置下next节点
UNSAFE.putOrderedObject(this, nextOffset, n);
}
static final sun.misc.Unsafe UNSAFE;
static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class k = HashEntry.class;
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
返回目录
Segment:内部类,用来实行并发操作
segment为ConcurrentHashMap的专用数据结构,同时扩展了ReentrantLock,使得Segment本身就是一把重入锁,方便执行锁定。Segment内部持有一个始终处于一致状态的entry列表,使得读取状态无需加锁(通过volatile读table数组)。调整table大小期间通过复制节点实现,使旧版本的table仍然可以进行遍历。
Segment仅定义需要加锁的可变方法,针对ConcurrentHashMap中相应方法的调用都会被代理到Segment中的方法。这些可变方法使用scanAndLock和scanAndLockForPut在竞争中使用受控旋转(自旋次数受限制的自旋锁) 由于线程的阻塞与唤醒通常伴随着上下文切换,CPU抢占等,都是开销比较大的操作。使用自旋次数受限制的自旋锁,可以提高获取锁的概率,降低线程阻塞的概率,这样可极大提升性能。为什么受限自旋呢?(自旋会不断消耗CPU的时间片,无限制自旋会导致开销增加)所以自旋锁适合多核CPU下,同时线程等待所的时间非常短,若等待时间较长,应该尽早进入阻塞。
成员变量和继承关系:
static final class Segment<K,V>
extends ReentrantLock //继承了重入锁
implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
//对segment加锁时,在阻塞之前进行的最大自旋次数,
//在多处理器上,使用有限数量的重试来维护在定位节点时获取的高速缓存
//最多自旋64
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
//每个segment的table数组,访问数组中元素通过entryAt/setEntryAt提供的
//volatile语义来完成。
transient volatile HashEntry<K,V>[] table;
//元素数量,只能在锁中或其它volatile读保证可见性之间进行访问。
transient int count;
//当前segment中可变操作发生的次数,put,remove等,可能会溢出32位,
//它为isEmpry()和size()方法中的稳定性检查提供了足够的准确性。
//只能在锁中或者其它volatile读保证可见性之间进行访问。
transient int modCount;
//table大小超过阈值对table进行扩容
transient int threshold; //阈值
final float loadFactor; //负载因子
//构造函数
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
返回目录
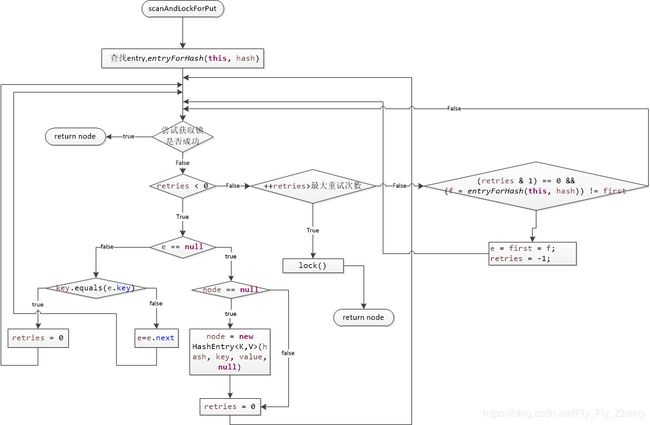
scanAndLockForPut:
while每循环一次,都会尝试获取锁,成功则返回, retries初始值设为-1是为了遍历当前hash对应的桶的链表,找到则停止遍历,未找到则会预创建一个节点;同时,如果头节点发生变化,则会重新进行遍历,直到自旋次数大于MAX_SCAN_RETRIES,使用lock进行加锁,如果失败则会进入等待队列。
为何要遍历一次链表:
scanAndLockForPut使用自旋次数受限制的自旋锁进行优化加锁的方式,此外遍历链表也是一种优化方法,主要是尽可能使当前链表中的节点进入CPU高速缓存,提高缓存命中率,以便获取锁定后的遍历速度更快。 实际上加锁后并没有使用已经找到的节点,因为它们必须在锁定下重新获取,以确保更新的顺序一致性,但是遍历一次后可以更快的进行定位 ,这是一种预热优化方法。 scanAndLock中也使用了该优化方式。
scanAndLock内部实现方式与scanAndLockForPut更简单,scanAndLock不需要预创建节点。因此主要用于remove和replace操作。
//自旋获取锁
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash); //根据key的hash值找到头节点
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
while (!tryLock()) { //尝试获取锁,成功返回,不成功开始自旋
HashEntry<K,V> f; // 用于后续重新检查头结点
if (retries < 0) { //第一次自旋
if (e == null) { //结束遍历节点
if (node == null) //创建节点
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key)) //找到节点,结束遍历
retries = 0;
else
e = e.next; //下一节点
//如果链表有节点,那么如果没有找到,
//那么就会一致遍历(retries=-1)的状态下
//直到节点到达末尾
}
else if (++retries > MAX_SCAN_RETRIES) { //达到最大尝试次数,
lock(); //进入加锁方法,失败则会进入排队,阻塞当前线程
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
//头节点发生变化需要重新遍历,说明油新结点加入或者被移除
e = first = f; // re-traverse if entry changed
retries = -1; //自旋次数归0,重新自旋
}
}
return node;
}
返回目录
put操作:
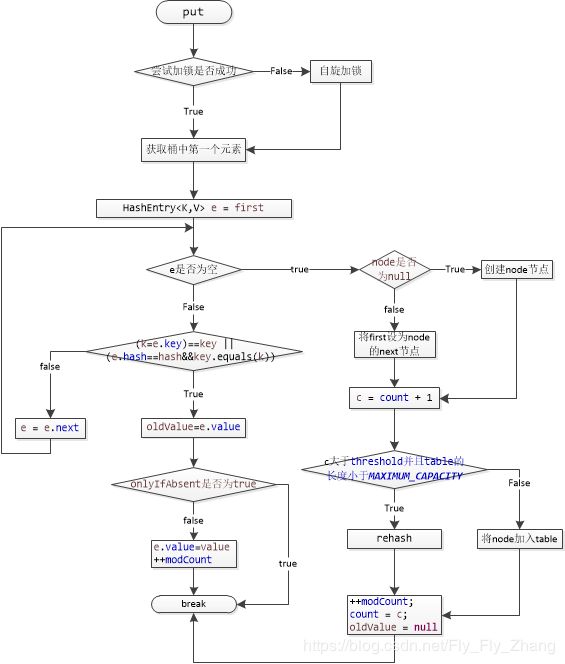
流程:
- 先对Segment加锁,然后根据(tab.length-1)&hash找到对应的slot
- 然后根据slot遍历对应的链表,
- 如果key对应的entry存在(根据onlyIfAbsent)决定是否替换新值
- 如果key对应的entry不存在,创建新节点头插法插入
- 若容量超出限制,则判断是否进行rehash;
几个优化:
在 scanAndLockForPut()中:
- 如果锁能够很快的获取到,有限次数的自旋可防止线程进入阻塞,有助于提升性能。
- 在自旋期间会遍历链表,希望遍历后的链表被 cache缓存,为实际put操作过程中的链表遍历操作提供性能(预热优化:遍历一次后可以更快进行定位)
- 并且还会预创建节点;
HashTable[] tab =table 好处:为什么不直接用table操作
table被声明为volatile,为了保证内存的可见性,table上的修改都必须立即更新到主内存,
volatile写实际是具有一定开销的。 由于put是中代码是加锁执行的,锁是既能保证可见性,也能保证原子性的,因此不需要在对table进行volatile写,将其赋给一个局部变量实现编译,运行时优化。
node.setNext(first)也是同样的道理,next同样是被声明为volatile,因此也是使用优化的方式UNSAFE.putOrderedObject进行volatile写入操作。
put已经加锁,为何访问tab元素不直接通过数组索引,而用entryAt(tab,index):
加锁保证了volatile同步语义,但是对table数组中元素的写入使用UNSAFE.putOrderedObject进行顺序写,该操作只是禁止写写重排序指令,不能保证写入后内存的可见性 所以必须使用使用entryAt(tab,index)提供的volatile读获取最新的数据
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null : //获得锁成功,
scanAndLockForPut(key, hash, value); //未成功获取锁,则自旋获取锁,
//如果超过自旋次数,则阻塞
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash; // 得到桶位置
HashEntry<K,V> first = entryAt(tab, index);
//volatile读语义获取index的头节点
for (HashEntry<K,V> e = first;;) { //遍历链表
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) { //找到节点
oldValue = e.value;
if (!onlyIfAbsent) { //是否替换旧值
e.value = value;
++modCount;//被修改次数
}
break;
}
e = e.next; //不是,继续遍历
}
else { //e==null //没有找到key值
if (node != null) //scanAndLockForPut只有找不到节点才会不返回null
node.setNext(first);
//将node设置为头节点,此处可以看出其为头插法链表插入元素
else //处理tryLock成功返回null值,没有找到节点的情况
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY) //当前table中元素数量大于阈值,
//需要重新进行rehash
rehash(node); //重新hash
else //没有大于阈值
setEntryAt(tab, index, node);//将node头节点插入table中
++modCount; //被修改次数
count = c; //元素个数
oldValue = null; //旧址=null
break;
}
}
} finally {
unlock();
}
return oldValue;
}
返回目录
rehash操作:
rehash主要的作用是扩容,将扩容前table中的节点重新分配到新table中。由于table的capacity都是2的幂,按照2的幂扩容为原来的一倍,扩容前在slot i 中的元素,扩容后要么在slot i中或者 i+扩容前table的capacity的solt中,这样使得只需要移动原来桶中的部分元素即可将所有节点分配到新table中。
为了提高效率,rehash首先找到第一个后续所有节点在扩容后index都保持不变的结点,将这个结点加入扩容后的table的index对应的slot中,然后将节点之前的所有节点重排即可。

//重新进行扩容hash,这个操作是已经在put加锁的
@SuppressWarnings("unchecked")
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table; //旧的table数组
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1; //二倍扩容
threshold = (int)(newCapacity * loadFactor); //新阈值
HashEntry<K,V>[] newTable = //新数组长度
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
//将旧数组中所有节点复制到新数组中,对旧数组中链表最后同index的进行复用(提高效率)
for (int i = 0; i < oldCapacity ; i++) {//遍历旧数组
HashEntry<K,V> e = oldTable[i];
if (e != null) { //当前数组节点不为空
HashEntry<K,V> next = e.next; //当前节点next节点
int idx = e.hash & sizeMask;//新数组角标
if (next == null) // Single node on list
newTable[idx] = e; //旧table数组此角标只有一个节点
else { //当前角标链表不止一个节点
// Reuse consecutive sequence at same slot
HashEntry<K,V> lastRun = e; //链表头节点
int lastIdx = idx;
for (HashEntry<K,V> last = next; //对链表进行遍历
//找到后续节点新index不变的节点
last != null;
last = last.next) {
int k = last.hash & sizeMask; //当前节点重新hash后的角标
if (k != lastIdx) { //当前节点k与lastIdx不同则进行替换
//目的是找到该链表最后相同新角标的节点,这样就可以
//最后一段链表一次性加入到新index
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
//这里为什么直接插入,不怕里面有数据嘛?
//sizeMask为掩码,新掩码在从二进制上来说,是多了一位,
//例如 1111 为旧掩码 11111为新掩码
// 0000 1010 0001 1010 为hash值,
//last.hash & sizeMask 后分别得到得角标为:
//旧: 1010 1010
//新:0 1010 1 1010 :也就是说,rehash之后
//旧链表的节点要么在原节点,要么在加新数组长度的1 1010 角标。
//而别的角标旧角标链表是不会hash到此节点的。
// Clone remaining nodes
//后续节点新index不变节点前的所有节点均需要重新创建分配
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k]; //当前角标头节点
newTable[k] = new HashEntry<K,V>(h, p.key, v, n); //头插法
}
}
}
}
//找到当前要插入节点对应的角标
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]); //头插法插入
newTable[nodeIndex] = node; //设置为新的头节点
table = newTable;
}
返回目录
scanAndLock操作:自旋并获取锁
private void scanAndLock(Object key, int hash) {
// similar to but simpler than scanAndLockForPut
HashEntry<K,V> first = entryForHash(this, hash);
//通过volatile读获取指定坐标的链表
HashEntry<K,V> e = first;
int retries = -1;
while (!tryLock()) { //自旋尝试获取锁
HashEntry<K,V> f;
if (retries < 0) {
if (e == null || key.equals(e.key)) //链表为空||找到key对应节点
retries = 0;
else
e = e.next; //遍历链表
}
else if (++retries > MAX_SCAN_RETRIES) { //大于最大自旋次数,阻塞线程
lock();
break;
}
else if ((retries & 1) == 0 && //头结点发生变化,重新自旋并且遍历链表
(f = entryForHash(this, hash)) != first) {
e = first = f;
retries = -1;
}
}
}
返回目录
remove操作:
final V remove(Object key, int hash, Object value) {
if (!tryLock()) //未成功获取锁,自旋获取
scanAndLock(key, hash);
V oldValue = null;
try {
HashEntry<K,V>[] tab = table; //已经加锁,不需要volatile写
int index = (tab.length - 1) & hash;
HashEntry<K,V> e = entryAt(tab, index);
//volatile读,获取index角标的链表
HashEntry<K,V> pred = null; //前驱
while (e != null) {
K k;
HashEntry<K,V> next = e.next;
if ((k = e.key) == key || //找到要删除节点
(e.hash == hash && key.equals(k))) {
V v = e.value;
//
if (value == null || value == v || value.equals(v)) {
if (pred == null) //要删除的是头节点
setEntryAt(tab, index, next);
else //非头节点
pred.setNext(next);
++modCount; //修改次数+1
--count; //元素数量--
oldValue = v; //旧值
}
break;
}
pred = e;
e = next;
}
} finally {
unlock();
}
return oldValue;
}
返回目录
replace操作:
boolean replace(K key, int hash, V oldValue, V newValue):根据旧值替换新值,若旧值发生变化,则返回false
final boolean replace(K key, int hash, V oldValue, V newValue) {
if (!tryLock()) //尝试获取锁,不成功则自旋获取
scanAndLock(key, hash);
boolean replaced = false;
try {
HashEntry<K,V> e;
//遍历给定角标链表
for (e = entryForHash(this, hash); e != null; e = e.next) {
K k;
if ((k = e.key) == key || //找到key值
(e.hash == hash && key.equals(k))) {
//典型CAS操作
if (oldValue.equals(e.value)) { //旧址相同则替换为新值
e.value = newValue;
++modCount;
replaced = true;
}
break; //说明oldvValue已经被别的线程修改
}
}
} finally {
unlock();
}
return replaced;
}
final V replace(K key, int hash, V value) :直接进行替换,并返回旧值
final V replace(K key, int hash, V value) {
if (!tryLock())
scanAndLock(key, hash);
V oldValue = null;
try {
HashEntry<K,V> e;
//遍历链表
for (e = entryForHash(this, hash); e != null; e = e.next) {
K k;
//找到直接进行替换
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
e.value = value;
++modCount;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
几个常用操作源码解析:
返回目录
get操作: 不需要进行加锁,只关心一个segment;非线程安全,得到的数据可能是过时数据。
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key); //对key进行hash
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; //得到对应segment
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) { //table数据存在
//遍历数组
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
//找到指定key
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value; //返回对应value值
}
}
return null;
}
返回目录
boolean isEmpty():判断集合是否为空
public boolean isEmpty() {
long sum = 0L;
final Segment<K,V>[] segments = this.segments;
for (int j = 0; j < segments.length; ++j) { //遍历sgment数组
Segment<K,V> seg = segmentAt(segments, j); //得到对应table
if (seg != null) {
if (seg.count != 0)
return false;
sum += seg.modCount; //可变操作次数相加
}
}
//有过修改痕迹,再次遍历
if (sum != 0L) { // recheck unless no modifications
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
if (seg.count != 0)
return false;
sum -= seg.modCount;
}
}
if (sum != 0L) //一加一减不为0 说明这期间有被修改过,所以不为null
return false;
}
return true;
返回目录
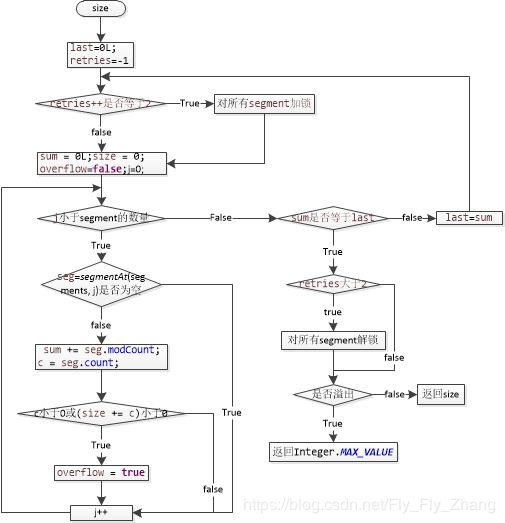
int size() 得到集合元素个数:
size和containsValue与put和get最大的区别在于,都需要遍历所有的Segment才能得到结果。
这两个源码实现都是先给三次机会。不lock所有的segment,比较相邻两次的modCount和,如果相同则说明在这之间整个集合是没有进行更新操作的。得到的size是正确的。如果三次循环之后仍然没有得到正确答案。那么就对所有的segment进行加锁。计算完毕后在进行解锁。
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
//为true表示size溢出32
long sum; // sum of modCounts //modCount和
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
//第一次迭代不计入重试,所以会重试三次
try {
for (;;) {
//前三次(-1,0,1) 进行不加锁统计size,如果得不到准确值则第四次加锁统计
if (retries++ == RETRIES_BEFORE_LOCK) { //默认table大小为2
//sgments全部加锁
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
//遍历segment
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) { //当前table不为空
sum += seg.modCount;
int c = seg.count; //当前segment元素个数
if (c < 0 || (size += c) < 0)
overflow = true; //size溢出
}
}
if (sum == last) //两次统计的可变操作修改次数相同,说明全部加锁成功
//并且获得准确size
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
// 三次以后才进行加锁,因此此时需要解锁
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size; //溢出返回最大值,否则返回size
}
返回目录
boolean containsValue(Object value) /boolean contains(Object value) :集合中是否包含此值
public boolean containsValue(Object value) {
// Same idea as size()
if (value == null) //hashMap不允许value为null
throw new NullPointerException();
final Segment<K,V>[] segments = this.segments;
boolean found = false; //是否包含
long last = 0;
int retries = -1;
try {
outer: for (;;) {
//三次不加锁尝试寻找,如果未成功则进行加锁寻找
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
long hashSum = 0L;
int sum = 0;
//遍历segments
for (int j = 0; j < segments.length; ++j) {
HashEntry<K,V>[] tab;
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null && (tab = seg.table) != null) {
//遍历table
for (int i = 0 ; i < tab.length; i++) {
HashEntry<K,V> e;
//遍历链表
for (e = entryAt(tab, i); e != null; e = e.next) {
V v = e.value;
if (v != null && value.equals(v)) { //找到value
found = true;
break outer; //跳出死循环
}
}
}
sum += seg.modCount; //可变操作次数相加
}
}
if (retries > 0 && sum == last) //两次操作中间没有发生可变操作次数变化
//说明value值不存在
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) { //大于2 需要解锁
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return found;
}
返回目录
弱一致性:
ConcurrentHashMap是弱一致性的,它的get/containsKey/clear/iterator都是弱一致性的。
get和containsKey都是无锁操作,均通过getObjectVolatile()提供的原子读来获得Segment以及对应的链表,然后遍历链表。由于遍历期间其它线程可能对链表结构做了调整 ,所以返回的可能是过时数据。
ConcurrentHashMap的高并发性主要来自三个方面:
- 用分离锁(segment锁)实现多个线程间的更深层次的共享访问;
- 用HashEntry 对象的不变性来降低执行读操作的线程在遍历链表期间对加锁的需求;
- 通过对同一个Volatile变量的写/读访问,协调不同线程间读/写操作的内存可见性;
1.7和1.8的区别
数据结构:
- 1.7数据结构为segement+HashEntry+链表
- 1.8数据结构为table+Node链表/Node红黑树

使用的锁:
- 1.7 为 ReentrantLock+Unsafe
- 1.8 为 Synchronized+CAS
如put操作时,若当前table数组对应的角标为空,则用CAS循环进行设置,除非此位置已有节点。
改变:
- 取消segments,直接采用transient volatile HashEntry
- 将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。对于hash表来说,最核心的能力在于将key hash之后能均匀的分布在数组中。如果hash之后散列的很均匀,那么table数组中的每个队列长度主要为0或者1。但实际情况并非总是如此理想,虽然ConcurrentHashMap类默认的加载因子为0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为O(n);因此,对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
扩容方式:
- 1.7 sagement的大小确定后,就不能在进行扩容,因此,其并发度是一定的。内部的table也是在单线程模式下扩容
- 1.8 锁的粒度在每个角标节点。因此扩容一次,其并发度也会增长一倍,并且其扩容方式为多线程参与的并发扩容。
1.8扩容:
这里主要涉及到多线程并发扩容,ForwardingNode的作用就是支持扩容操作,将已处理的节点和空节点置为ForwardingNode,并发处理时多个线程经过ForwardingNode就表示已经遍历了,就往后遍历,下图是多线程合作扩容的过程:

1.8链表如何转红黑树:
需要注意的是,其和1.8的HashMap是一样的。在满足链表个数大于等于8并且table数组长度大于64时才会进行链表转红黑树。否则在链表长度大于等于8时,只会引起一次扩容。
因此,进行数组扩容的情况有两种,一种是到达阈值进行扩容,一种是单个角标链表长度大于8进行扩容 。