基于用户的协同过滤算法原理分析及代码实现
我所采用的数据集:MovieLens数据集ml-100k。
先进行原理分析,再讲代码实现。
基于用户的协同过滤算法主要包括两个步骤:
(1)找到和目标用户兴趣相似的用户集合;
(2)找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
步骤(1)的关键就是计算两个用户的兴趣相似度。给定用户u和用户v,令N(u)表示用户u曾经有过行为的物品集合,令N(v)表示用户v曾经有过行为的物品集合。我们可以通过Jaccard公式简单地计算u和v的兴趣相似度:
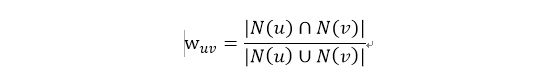
按我的理解,分子表示用户u与用户v同时喜欢的电影个数,分母表示用户u与用户v评论过的电影乘积。
在我的试验中,我采用的是Pearson相关系数计算相似距离:
采用Pearson相关系数用户x和y的相似度:

得到用户之间的兴趣相似度后,userCF算法会给用户推荐和他兴趣最相似的K个用户喜欢的物品。以下的公式度量了userCF算法中用户u对物品i的感兴趣程度:
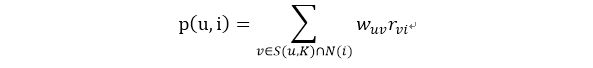
其中,S(u,K)包含和用户u兴趣最接近的K个用户,N(i)是对物品i有过行为的用户集合,w是用户u和用户v的兴趣相似度,r是用户v对物品i的兴趣,这里令所有的r=1.
以上过程就是基于用户的协同过滤算法的简单流程,对算法有了大致了解后,再来看一下具体代码。
我写代码时候的思路:
(1)拿到数据后,按行读取;
(2)转换成两个字典,一个关于用户id,一个关于电影id;
(3)找出与特定用户评论过相同电影的所有用户;
(4)将特定用户与上一步得到的所有用户计算相似度,并排序;
(5)取出前K个用户,计算这K个用户所评论过的所有电影的加权和,并排序;
(6)取出若干个电影在列表中显示。
#主程序
if __name__=='__main__':
itemTemp=getMovieList("E:/learning/python/ml-100k/u.item") #获取电影列表
fileTemp=readFile("E:/learning/python/ml-100k/u.data") #读取文件
user_dic,movie_dic=createDict(fileTemp) #创建字典
movieTemp=userCF(188,user_dic,movie_dic,80) #对电影排序
rows=[]
table=Texttable() #创建表格并显示
table.set_deco(Texttable.HEADER)
table.set_cols_dtype(['t','f','a'])
table.set_cols_align(["l","l","l"])
rows.append(["movie name","release","from userid"])
for i in movieTemp[:20]:
rows.append([itemTemp[i[1]][0],itemTemp[i[1]][1],""])
table.add_rows(rows)
print(table.draw())参考:
《推荐系统实践》作者: 项亮
[推荐算法]基于用户的协同过滤算法