机器学习面试知识点汇总
机器学习面试知识点汇总
最近开始找实习了,记录一下看过的知识点,方便查询,以下的知识点主要是根据同学面试问题或者网上面经题目整理。
1:字符串匹配算法
- 朴素匹配算法
- KMP (https://www.geeksforgeeks.org/kmp-algorithm-for-pattern-searching/)
- 有限自动机算法
- AC自动机(多模式匹配)
public class KMP {
public static void main(String[] args) {
String input="ABABDABACDABABCABAB";
String pattern="ABABCABAB";
int patternLength=pattern.length();
int inputSize=input.length();
int[] lps=constructLPS(pattern);
for(int i=0;i上面的代码是KMP算法的java实现,很重要的一点就是当构建lps数组(或者next数组)的时候,如果当前字符不匹配,也就是pattern.charAt(end_of_prefix)!=pattern.charAt(end_of_suffix)的时候,那么[0:end_of_prefix-1]是已知已经匹配了的,由于在[0:end_of_prefix-1]中,长度为lps[end_of_prefix-1]的前缀和后缀一定是匹配的,所以可以直接跳过这个长度,直接匹配end_of_suffix这个字符。
2:银行家算法
银行家算法是操作系统中防止死锁产生的一个算法,主要是使用一些额外的数据结构来防止死锁条件的产生:
1)可利用资源向量Available
是个含有m个元素的数组,其中的每一个元素代表一类可利用的资源数目。如果Available[j]=K,则表示系统中现有Rj类资源K个。
2)最大需求矩阵Max
这是一个n×m的矩阵,它定义了系统中n个进程中的每一个进程对m类资源的最大需求。如果Max[i,j]=K,则表示进程i需要Rj类资源的最大数目为K。
3)分配矩阵Allocation
这也是一个n×m的矩阵,它定义了系统中每一类资源当前已分配给每一进程的资源数。如果Allocation[i,j]=K,则表示进程i当前已分得Rj类资源的 数目为K。
4)需求矩阵Need
这也是一个n×m的矩阵,用以表示每一个进程尚需的各类资源数。如果Need[i,j]=K,则表示进程i还需要Rj类资源K个,方能完成其任务。
Need[i,j]=Max[i,j]-Allocation[i,j]
5)Finish矩阵
是个含有m个元素的数组,其中的每一个元素为一个布尔值,代表该进程是否结束。如果Finish[i]=True代表第i个进程尚未结束,Finish[i]=False代表第i个进程已经结束。
通过将Need矩阵和Available矩阵进行比较,从Finish[i]==False的进程中选择Need[i , :]都小于Available[:]的进程,那么就可以将资源分配给它,在它结束执行之后,再将资源回收,并且令Finish[i]=True。
参考:
https://baike.baidu.com/item/%E9%93%B6%E8%A1%8C%E5%AE%B6%E7%AE%97%E6%B3%95/1679781?fr=aladdin
https://zh.wikipedia.org/wiki/%E9%93%B6%E8%A1%8C%E5%AE%B6%E7%AE%97%E6%B3%95
3:one-shot learning(zero-shot learning)
one-shot learning的意思就是说有些类别的样本,我们只有一个甚至零张个,如何使用这些样本进行训练,使得真实数据能够被划分到这些只具有少量样本的类中。传统观点一般认为深度神经网络通常比较擅长从高维数据中学习,例如图像或者语言,但这是建立在它们有大量标记的样本来训练的情况下。然而,人类却拥有单样本学习的能力--如果你找一个从来没有见过小铲刀的人,给它们一张小铲刀的图片,他们应该就能很成功的将它从其他厨房用具里面鉴别出来。

one-shot learning解决方案:
- k-近邻
- 相似性度量(metric learning),如孪生神经网络
zero-shot learning和one-shot learning类似,对于训练集中从来没有出现过的样本,希望模型能够将其分辨出来。zero-shot learning和one-shot learning可以看做迁移学习的范畴,在一种场景下训练,然后在另一个场景下应用。ian goodfellow的第15.2章中说,“只有在训练时使用了额外信息,one-shot learning和zero-shot learning才是有可能的”,也就是说,往往需要添加一些和未知数据有关的描述,从现有模型对未知数据进行预测才是可能的。
参考:
https://zhuanlan.zhihu.com/p/29058453
https://blog.csdn.net/ice_actor/article/details/78603042(recommended)
https://www.quora.com/What-is-zero-shot-learning(quora answer)
4:最长公共子序列(LSC)
最长公共子序列是最常见的动态规划问题,根据优化子结构求最优解的递归式是:
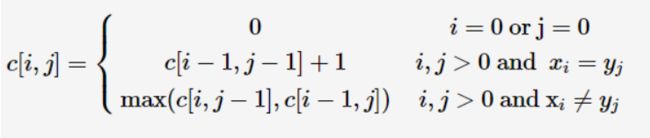
上式中c[i,j]代表str1[0:i]和str2[0:j]的最长公共子序列的长度,具体情况可查看算法导论15.4节,下面是java代码:
public class LSC {
public static void main(String[] args) {
String a="AGGTAB";
String b="GXTXAYB";
int length=lsc(a, b);
System.out.println("lenght: "+length);
}
public static int lsc(String a,String b) {
int lengthA=a.length();
int lengthB=b.length();
int[][] dp=new int[lengthA+1][lengthB+1];
int[][] path=new int[lengthA+1][lengthB+1];
for(int i=0;i<=lengthA;i++) {
for(int j=0;j<=lengthB;j++) {
if(i==0) {
dp[i][j]=0;
path[i][j]=Direction.LEFT;
} else if(j==0) {
dp[i][j]=0;
path[i][j]=Direction.TOP;
}
else {
char chA=a.charAt(i-1);
char chB=b.charAt(j-1);
if(chA==chB) {
dp[i][j]=dp[i-1][j-1]+1;
path[i][j]=Direction.CROSS;
} else {
int left=dp[i][j-1];
int top=dp[i-1][j];
dp[i][j]=Math.max(left, top);
path[i][j]=(left>top)?Direction.LEFT:Direction.TOP;
}
}
}
}
String tempA=" "+a;
String tempB=" "+b;
for(int k=0;k0 && col>0) {
if(path[row][col]==Direction.CROSS) {
outputPath.append(a.charAt(row-1));
row--;
col--;
} else if(path[row][col]==Direction.LEFT) {
col--;
} else {
row--;
}
}
System.out.println("-------------------------");
System.out.println("the lsc is:"+outputPath.reverse().toString());
return dp[lengthA][lengthB];
}
}
class Direction{
public static int LEFT=0;
public static int TOP=1;
public static int CROSS=2;//(i,j)' cross equal (i-1,j-1)
} 
参考:
https://www.geeksforgeeks.org/longest-common-subsequence-dp-4/
5:内存分类
可能不同的程序语言有不同的内存分类情况,但是通过对比可以发现,大概分为堆,栈,静态存储区:
c++内存大概划分为五种:
1.栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数,数组等。
2.堆,就是那些由new分配的内存块以及数组引用,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
3.自由存储区,就是那些由malloc等分配的内存块,他和堆是十分相似的,不过它是用free来结束自己的生命的。
4.全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量又分为初始化的和未初始化的,在C++里面没有这个区分了,他们共同占用同一块内存区。
5.常量存储区,这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改(当然,你要通过非正当手段也可以修改)
栈一般存储的是已知大小的数据,除此之外还有关于函数的数据(如局部变量,参数),堆一般存储的是运行时(动态申明)申明的数据(如对象,malloc申明的存储空间)。不同的线程有自己的栈,但是他们会共用同一个堆,该堆是线程所属进程的堆。在堆上声明的数据必须认为清空。
Function parameters and local variables are generally allocated on a stack. A stack, in computer terms, is basically a linear structure in memory where information (values for variables, for example) are stored sequentially with the most recently added value at the “top” or the end of the memory structure from which values are also read and removed. This allows a function to call itself recursively, and have separate copies of all its parameters and local variables retained separately for each call. The variable values are all “pushed” onto the stack, and then execution begins with a new set of values in the new call. When the function returns, the variable values are restored by “popping” the values from the “top” of the stack in reverse order, thus restoring the previous values of all the variables.
A heap is generally used for larger data structures or memory that the programmer wants to explicitly manage. Whenever “new” or “malloc” is used in C++ or C respectively, the memory for that request is allocated on a heap, and then it’s up to the coder to make sure that is gets freed at the appropriate time with “delete” or “free”. Whereas stack data is usually easy to manage because the compiler allocates and frees the space, heap data is easy to mess up because it often requires manually written code to determine when it gets allocated and freed.
参考:
https://www.quora.com/What-is-the-difference-between-the-stack-and-the-heap(recommended)
https://www.cnblogs.com/dolphin0520/p/3613043.html(java)
https://www.cnblogs.com/fenghuan/p/4778050.html(c,c++)
6:linux常用指令
查看所有进程:ps -aux
软链接: ln -s slink source
查找命令:locate whereis find
查看磁盘空间:df -hl
网络连接状况:netstat
参考:
https://www.cnblogs.com/hystj/p/8552757.html
7:linux调试代码
linux 调试c,c++,python等使用gdb调试工具。当我们要使用GDB进行程序的调试时,需要再在用GCC编译时需要加上-g
![]()
GDB之所以能够进行程序的调试也是在于进行编译时的-g选项,当设置了这个选项的时候,GCC会向程序中塞入一下信息,作为GDB调试时的铺垫,然后GDB才能够利用这些铺垫和信息与程序交互。
有两种方式可以进入GDB,一种就是直接在命令行上输入gdb,然后再在gdb中用file命令加载要调试的程序:
另一种就是,直接在命令行上使用:gdb 程序名

- 设置断点 :b 行号
- 删除断点:delete break_id
- 显示断点信息:info break
- 继续执行:c
- 显示变量:display 变量名
- 改变变量的值:set var=..
- 运行程序等:run
- 退出gdb:q
详细情况查看https://www.cnblogs.com/kunhu/p/3603268.html
java程序也可以在linux下面进行调试,使用的工具是jdb,该工具是jdk内置的调试工具,详细使用方法可以查看https://blog.csdn.net/djy37010/article/details/64441367,和gdb类似。
8:梯度下降算法
梯度下降算法是线性收敛的,相对于牛顿法等二阶收敛方法来说,收敛速度没那么快。而且在实际计算中,梯度下降算法在开始迭代时效果较好,能够到达最优解的附近。但当其继续迭代时,往往发生扭摆现象,迭代点沿着正交方向扭摆,而不能到达最优解。
虽然说牛顿法收敛速度为二阶的,对正定二次函数一步迭代即达到最优解,具有二次终结性,但是也存在一些缺点。(1)牛顿法是局部收敛的(2)牛顿法不是下降算法,当二阶海瑟矩阵非正定时,不能保证产生的方向是下降的(3)海瑟矩阵必须可逆,而且计算量很大。
未写完
9:大文件处理
很多面试官都会问到相关的问题,比如说10个数的文件,如果得到值最大的前1000个数;或者说100亿个字符串,怎么得到出现频率最大的前1000个字符串等等,其实这些问题的核心都是分治,也就是先将大文件划分为若干小文件,然后对每个小文件进行排序,或者其他处理,然后合并处理。
我在面试的时候犯了一个很低级的错误,面试官问了我一个问题,1000亿个字符串,大概100GB存储在外存中,运行内存只有1GB,如何找到出现频率最多的字符串。首先,肯定会用到分治,先分成小文件,但是对小文件进行处理的时候我犯了一个错,我说的是直接找到小文件里面前K个频率最高的字符串,存在两点误区:
- 直接从处理之后的小文件里面选取结果,只能够找到近似解,不能得到全局最优解;
- 不同的小文件里面可能存在重复的字符串,因此需要通过一定的方法选取不相重合的小文件;
因此,处理大文件有三点非常重要:
- 如果划分小文件
- 如何对每个小文件进行相应的处理
- 如何合并每个小文件的结果
对于上面的题来说,可以根据字符串的几位来划分到不同的文件中,意思就是说“abc”等字符串可以使用ASCII码对应的二进制表示,然后可以像ip地址一样,前多少位处于某个范围可以被划分到某个文件中,这样就可以保证不同的文件不会存在相同的数据。
参考:
https://blog.csdn.net/qq_26498709/article/details/78432054
10:BN的缺陷
BN的好处我们都知道,是加快收敛速度,防止梯度爆炸等等,那么什么问题不适合使用BN呢?
batch normalization依赖于batch的大小,当batch值很小时,计算的均值和方差不稳定。研究表明对于ResNet类模型在ImageNet数据集上,batch从16降低到8时开始有非常明显的性能下降,在训练过程中计算的均值和方差不准确,而在测试的时候使用的就是训练过程中保持下来的均值和方差。
这一个特性,导致batch normalization不适合以下的几种场景。
(1)batch非常小,比如训练资源有限无法应用较大的batch,也比如在线学习等使用单例进行模型参数更新的场景。
(2)rnn,因为它是一个动态的网络结构,同一个batch中训练实例有长有短,导致每一个时间步长必须维持各自的统计量,这使得BN并不能正确的使用。在rnn中,对bn进行改进也非常的困难。不过,困难并不意味着没人做,事实上现在仍然可以使用的,不过这超出了咱们初识境的学习范围。
# -*- coding: utf-8 -*-
"""
Created on Sun Jul 21 13:02:06 2019
@author: shen
"""
import tensorflow as tf
import numpy as np
#input_x = np.arange(9).reshape(3,3)
input_x = np.array([[0,2,1],[3,2,2],[6,2,0]])
print(input_x)
input_tensor = tf.placeholder(shape = (3,3), dtype=tf.float32)
input_BN = tf.contrib.layers.batch_norm(input_tensor, decay=0.9)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(input_BN, feed_dict = {input_tensor: input_x}))

从上面的结果可以比较清晰的看到BN的计算过程,对每一维计算均值以及方差,然后对每一维的数据进行归一化,算法如下(其中ε代表一个很小的常量,为了防止分母出现0的情况):

参考:
https://www.zhihu.com/question/38102762/answer/607815171
11:推荐系统冷启动问题
推荐系统的一大问题就是所谓的冷启动问题,在对用户一无所知的情况下,如何进行最有效的推荐。
参考:
有哪些解决推荐系统中冷启动的思路和方法? - 陈运文的回答 - 知乎 https://www.zhihu.com/question/19843390/answer/101099402