推荐算法(CF)--协同过滤
系统框架
推荐系统常用来解决TopN问题和用户行为预测问题

– 充分利用群体智慧(要么是根据相似用户推荐,要么是根据历史物品推荐)
– 推荐精度高于CB(user-item即CF)
– 利于挖掘隐含的相关性
• 缺点
– 推荐结果解释性较差
– 对时效性强的Item不适用---比如促销大甩卖,只是临时上架的物品,没有user表达,所以关联不了,通常用CB来解决
– 冷启动问题
协同算法
• User-Based CF
• Item-Based CF
比如一个商品item(程序员看做商品的元数据),用户A只点击了1次打一分,用户B都没点击打0分,用户C不但点击了还加入了购物车打3分,由此得到正排表 item=userA:1 userB:0 userC:2,这是CF。而推荐算法CB,是通过中文分词对item的元数据得到的正排表 item=token1:score token2:score token:score,由此可见,CB和CF的区别并不是很大他们都能得到item-item矩阵和user-user矩阵,只不过是CB的基于内容到CF基于行为的变化而已。
CB可以更新user-item(CF)矩阵
比如user历史上看过itemA、itemB、itemC,我们可以通过item-item矩阵,给用户推荐新的商品itemM、itemN
User-BasedCF
• 假设– 用户喜欢那些跟他有相似爱好的用户喜欢的东西
– 具有相似兴趣的用户在未来也具有相似兴趣
• 方法--UU矩阵=UI矩阵*IU矩阵
– 给定用户u,找到一个用户的集合N(u),他们和u具有相似的兴趣
– 将N(u)喜欢的物品推荐给用户.


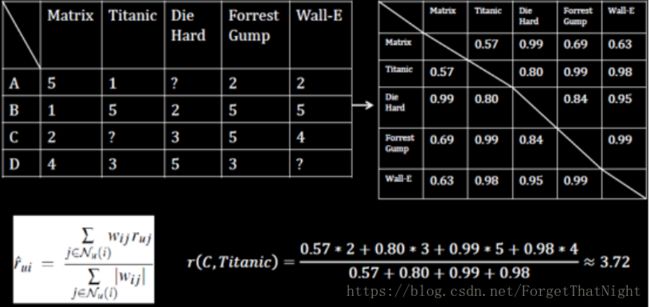
通过UI矩阵做任一两个user的相似度计算得到UU矩阵(如图对两个向量先做归一化、去模,然后计算余弦相似度)

通过UU矩阵找到看过titannic且相似度最大的用户B、D,预测出用户C可能会对titannic打分4.05
Item-BasedCF• 假设
– 用户喜欢跟他过去喜欢的物品相似的物品
– 历史上相似的物品在未来也相似
• 方法
– 给定用户u,找到他过去喜欢的物品的集合R(u).
– 把和R(u)相似的物品推荐给u.
User vs.Item

user based和item based得到的分数不能直接相比较,没有可比性,因为得到分数的机制不同,所以不能因为谁高而选谁,只能根据上图的场景来具体选择合适的方式。
user based之所以令人难以解释,是因为用户不知道是通过哪个用户的相似度来推荐。
冷启动
• 分为三类– 用户冷启动
• 提供热门排行榜,等用户数据收集到一定程度再切换到个性化推荐
• 利用用户注册时提供的年龄、性别等数据做粗粒度的个性化
• 利用用户社交网络账号,导入用户在社交网站上的好友信息,然后给用户推荐其好友喜欢的物品
• 在用户新登录时要求其对一些物品进行反馈,收集这些兴趣信息,然后给用户推荐相似的物品--类似简书、微博
– 物品冷启动
• 给新物品推荐给可能对它感兴趣的用户,利用内容信息,将他们推荐给喜欢过和它们相似的物品的用户
• 物品必须能够在第一时间展现给用户,否则经过一段事件后,物品的价值就大大降低了
• UserCF和ItemCF都行不通,只能利用Content based解决该问题,频繁更新相关性数据
– 系统冷启动
• 引入专家知识,通过一定高效方式迅速建立起物品的相关性矩阵
实现方案
• 倒排式
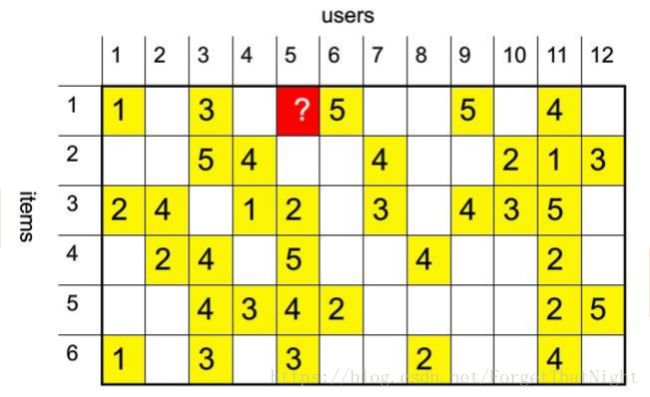
• 输入数据--user-item的稀疏矩阵 输出数据--user-item的密集矩阵
• 相似度计算公式

rui、ruj为用户U分别对物品i、j两个item的打分,是归一化后的分数向量,如上图A(5,1,2,2)->A(0.857,0.171,0.343,0.343)
输入数据:user-item的稀疏矩阵,然后针对每一行user-item任取两个item(因为这些item都被同一个user消费,所以之间有相似度)有 C32 种取法,得到的是一个item-item的结果,每一行item-item都是被一个用户共享所以才有一定的相似性,至于是哪个用户,我们不关心,所以我们直接把用户舍弃。----这里会存在一个性能瓶颈问题,因为数据是指数级增长,折中的方案就是数据截取,虽然有这种缺点,但时工作仍然是倒排式比较多
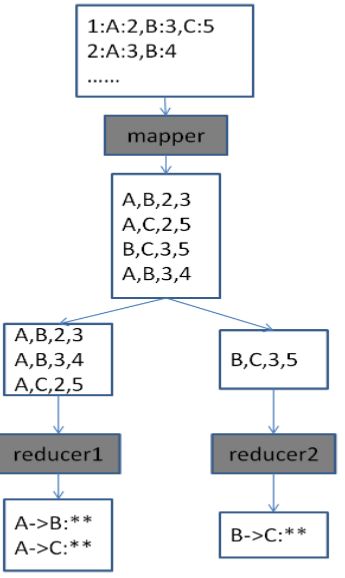
– 在MR的map阶段将每个用户的评分item组合成pair
- 按left作为分发键进行分桶,同一个Key的用户越多,对相似度的计算越可靠
– 在reduce阶段,将map中过来的数据按照相似度计算公式扫一遍即可求得所有item的相似度。
• 分块式
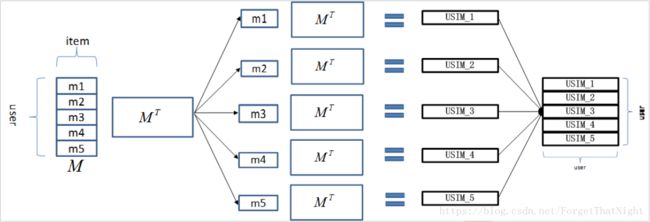
为了得到UU矩阵->我们需要提前准备UI矩阵和IU矩阵
为了得到II矩阵->我们需要提前准备IU矩阵和UI矩阵
缺点:如果M的转置矩阵特别大,那么每个节点可能导致数据存不下