MASK in NLG
ICML 2019 《MASS:Masked Sequence to Sequence Pre-training for Language Generation》
MASS github
BERT等在大型语料库上进行预训练的语言模型在NLP的语言理解任务(例如:情感分类、自然语言推理和 SQuAD 阅读理解)上取得了不错的效果,用户可以根据具体下游任务的数据集进行fine-tune来使得模型更加适合具体任务的需求。但是由于BERT是基于双向的Transformer实现的,它和自然语言生成任务的机制不同,因此无法在生成任务(例如机器翻译、文本摘要生成、对话生成、问答、文本风格转换等)上取得较好的效果,而基于单向训练的GPT由于训练机制的不同,目前已经可以较好的生成较长且流畅的文本。
本文借鉴BERT中MASK的思想,提出了一种结合MASK机制和Sequence-to-Sequence的预训练生成模型(MASS)。MASS通过在Encoder的输入端mask掉一段词,然后使用Decoder对其mask掉的部分进行预测,通过联合训练的方式来提升模型的特征抽取和语言建模能力。最后在机器翻译、文本摘要和对话生成三个生成任务上进行实验,从而证明了模型的有效性。
首先来回顾一下《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》中所使用的MASK策略。BERT使用MASK LM来做预训练,在模型的输入端mask掉15%的词,然后只让模型预测mask的部分,通过这样的方式来获取上下文相关的双向特征表示,从而增强模型的语言建模型能力。在15%被mask的部分,其中80%使用[MASK]进行替换;10%用随机的token进行替换;10%并不进行改变。但是[MASK]并不会出现在fine-tune阶段,因此造成了预训练和fine-tune两阶段的不一致性。

后续针对BERT改进的模型中有一部分就是试图改进MASK策略来提升效果的,例如:
-
BERT-WWM:按照whole Word维度进行mask,然后进行预测
-
ERNIE系列:引入外部知识,按照entity维度进行mask,然后进行预测
-
SpanBERT:不需要按照先验的词、实体、短语等边界信息进行mask,而是采取随机mask策略
- 采用Span Masking:根据几何分布,随机选择一段空间长度,之后再根据均匀分布随机选择起始位置,最后按照长度mask;通过采样,平均被遮盖长度是3.8 个词的长度
- 引入Span Boundary Objective:新的预训练目标旨在使被mask的Span 边界的词向量能学习到 Span中被mask的部分;新的预训练目标和MLM一起使用
ERT WWM、ERNIE等系列、SpanBERT旨在隐式地学习预测词(mask部分本身的强相关性)之间的关系
相比于上面提到的多个模型,MASS以另一种方式将MASK机制结合到了模型之中。假设输入为 ( x , y ) ∈ ( X , Y ) (x,y) \in (X,Y) (x,y)∈(X,Y),其中 x = ( x 1 , . . . , x m ) , y = ( y 1 , . . . , y n ) x = (x_{1},...,x_{m}),y=(y_{1},...,y_{n}) x=(x1,...,xm),y=(y1,...,yn),对于Seq2Seq的语言模型来说,建模的过程相当于计算 P ( y ∣ x ; θ ) = ∏ t = 1 n P ( y t ∣ y < t , x , θ ) P(y|x;\theta)=\prod_{t=1}^n P(y_{t}|y_{<t},x,\theta) P(y∣x;θ)=∏t=1nP(yt∣y<t,x,θ)。这里将使用mask的输入记为 x ∖ u : v x^{\setminus u:v} x∖u:v,它表示 u u u到 v v v这部分的序列被mask掉,且 0 < u < v < m 0<u<v<m 0<u<v<m, m m m表示输入序列的长度。 x u : v x^{u:v} xu:v表示被mask掉的序列片段, k = v − u + 1 k=v-u+1 k=v−u+1表示mask掉的序列长度。
MASS接收 x ∖ u : v x^{\setminus u:v} x∖u:v为输入,通过预测 x u : v x^{u:v} xu:v进行建模,这里使用的依然是MLE:
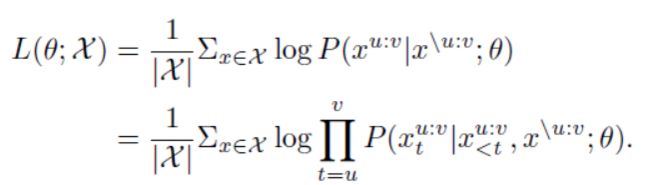
MASS的MASK策略如下所示,假设此时在Encoder端被mask掉的为 x 3 − > 6 x_{3->6} x3−>6,Deocder需要预测出被mask掉的部分是什么。这里不同于以往的是Decoder的输入并不是完整的序列,而是只有对应mask的前 k − 1 k-1 k−1个token保留。另外为了迫使Enocder更好的捕获输入端的信息,Decoder将输入中没有被mask掉的部分也全部mask掉,这样使得Decoder可以从Encoder中抽取更有用信息,而不只是依赖于先前已存在的部分。
总体来说,MASS 预训练具有以下优势:
- 解码器端的其他标记(在编码器端未被掩蔽的标记)被掩蔽,从而推动解码器提取更多信息以帮助预测连续句子片段,促进编码器-注意力-解码器结构的联合训练;
- 为了给解码器提供更多有用的信息,编码器被强制提取未被掩蔽的标记的含义,这可以提高编码器理解源序列文本的能力;
- 解码器被设计用以预测连续的标记(句子片段),这可以提升解码器的语言建模能力。
模型中一个很重要的参数就是 k k k,作者指出BERT和GPT都可以看做是MASS在 k k k值选取不同时的特例。

当 k = 1 时,根据 MASS 的设计,编码器端的一个标记被掩蔽,而解码器端则会预测出该掩蔽的标记。解码器端没有输入信息,因而 MASS 等同于 BERT 中掩蔽的语言模型。
当 k = m(m 是序列的长度)时,在 MASS 中,编码器端的所有标记都被掩蔽,而解码器端会预测所有的标记。解码器端无法从编码器端提取任何信息,MASS 等同于 GPT 中的标准语言模型。

实验
作者分别使用预训练模型在机器翻译、文本摘要和对话生成三个任务上进行了fine-tune,从而来验证模型的可行性,这里只列出感兴趣的文本摘要上的结果,其他的可见论文。
实验中所使用的语料库为Gigaword,评价指标为ROUGE,对比模型为BERT+LM和DAE,实验结果如下所示

从结果中可以看出,在不同规模的数据上,MASS的效果都优于baseline,特别是在低资源的情形下,优势更加的明显。实验一方面说明了Transformer强大的特征抽取能力,另一方面说明了MASK的确可以提升Encoder的信息抽取能力和Decoder的语言建模能力。
在关于k的实验结果中可以看出,当k在序列长度的50%附近时模型效果最好。

另外作者也设计了实验证明预测连续的mask tokens和在Decoder端采用的输入策略可以帮助提升模型的效果。
