【机器学习笔记29】Pandas常用方法备注
【参考资料】
【1】https://www.kaggle.com/artgor/eda-feature-engineering-and-everything
【2】http://pandas.pydata.org/pandas-docs/stable/index.html
构筑测试数据
纯粹是编出来的测试数据,不考虑其设计合理性:)
创建商品数据表
包括(product_id 商品ID,time 商品创建时间、name 商品名称、 price 价格、address 产地)
data_product = pd.DataFrame([(1001, '2012-05-01', '产品A', 210, '杭州|上海'),
(1002, '2012-06-01', '产品B', 20, '杭州'),
(1003, '2012-07-01', '产品C', 110, '杭州|北京|上海|广东')], columns=['product_id', 'time', 'name', 'price', 'address'])
创建订单数据表
包括(order_id 订单ID, order_time 订单时间, product_id 商品ID关联商品表 user_id 用户ID, count 该订单里购买的商品数量)
data_order = pd.DataFrame([(1, '2018-09-01 08:00:00', 1001, 12, 1),
(2, '2018-09-01 09:00:00', 1001, 13, 2),
(3, '2018-11-01 07:30:00', 1002, 12, 1),
(4, '2018-09-02 08:00:00', 1002, 14, 4),
(5, '2018-09-03 08:00:00', 1003, 12, 1),
(6, '2017-09-03 08:00:00', 1003, 12, 1)], columns=['order_id', 'order_time', 'product_id', 'user_id', 'count'])
一 基本信息查看
print("data_product columns {} \n and data_order columns {} ".format(data_product.columns, data_order.columns))
print("data_product {} samples and {} features".format(data_product.shape[0], data_product.shape[1]))
print("data_order {} samples and {} features".format(data_order.shape[0], data_order.shape[1]))

二 用merge进行JOIN操作
merge_data = data_order.merge(data_product, on = ['product_id'], how = 'left')

三 利用既有列得到一个新的数据列
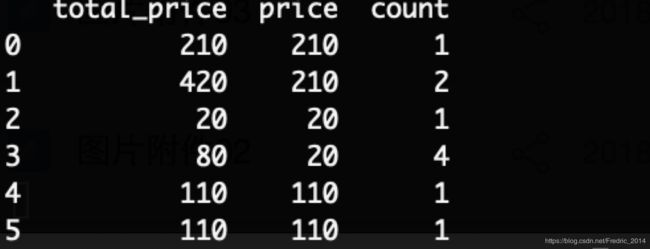
利用单价和商品购买数量,生成该订单金额
merge_data['total_price'] = merge_data['price'] * merge_data['count']
print(merge_data[['total_price', 'price', 'count']])
四 COUNT\SUM等简单聚合方法
#获取总价前两个
total_price = merge_data['total_price'].value_counts()
#统计消费金额大于200的订单数量
sum_price_higher = (merge_data['total_price'] >= 200).sum()
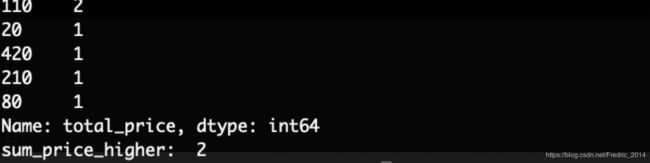
上图表示订单总额为110的有两笔,20的有一笔,同理类推。
五 GROUPBY 聚合方法
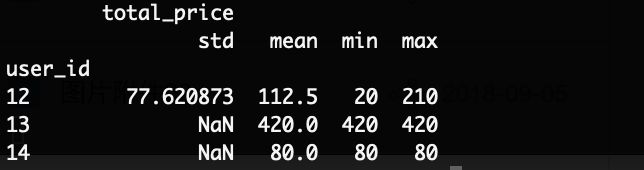
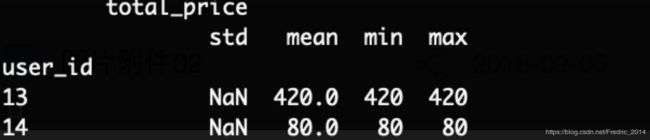
#用user_id字段group,计算其消费订单total_price价格的均值,最大值、最小值等
group_order_by_user = merge_data.groupby('user_id').agg({'total_price': ['std','mean', 'min', 'max']})
#对输出数据进行排序
g_2 = group_order_by_user.sort_values(('total_price', 'min'), ascending=False)[:2]
六 字符串的分拆和拼接
#把产品表中的生产地分拆
address_split = data_product['address'].str.split('|',expand=True)
#把产品表中所有的商品名称输出一个列表
product_text_list = "|".join(data_product['name'].str.lower().values[-1000000:])

七 时间操作
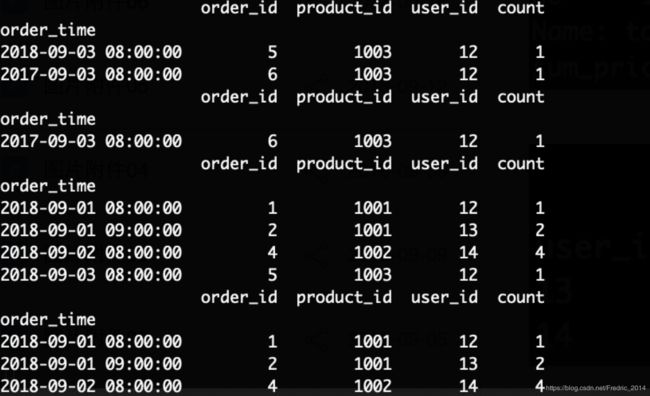
data_order['order_time'] = pd.to_datetime(data_order['order_time'])
data_order = data_order.set_index('order_time')
print(data_order.tail(2)) #根据时间排序取最早的两个
print(data_order['2017']) #取2017年数据
print(data_order['2018-09']) #取2018年9月数据
print(data_order['2018-09-01':'2018-09-02']) #取2018年9月1日~2日的数据