谈谈面试--哈希表系列
前言:
我以前在百度的mentor, 在面试时特喜欢考察哈希表. 那时的我满是疑惑和不解, 觉得这东西很基础, 不就的分桶理念(以空间换时间)和散列函数选择吗? 最多再考察点冲突解决方案. 为何不考察类似跳跃表, LSM树等高级数据结构呢?
随着工程实践的积累, 慢慢发现了自己当初的肤浅. 面试的切入点, 最好是大家所熟悉的, 但又能从中深度挖掘/剖析和具有区分度的.
本文结合自己的工程实践, 来谈谈对哈希表的优化和实践的一些理解.
基础篇:
哈希表由一定大小的连续桶(bucket)构成, 借助散列函数映射到具体某个桶上. 当多个key/value对聚集到同一桶时, 会演化构成一个链表.
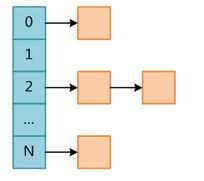
哈希表结构有两个重要的参数, 容量大小(Capacity)和负载因子(LoadFactor). 两者的乘积 Capacity * LoadFactor决定了哈希表rehash的触发条件.
以空间换时间为核心思想, 确保其数据结构的访问时间控制在O(1).
哈希表隐藏了内部细节, 而对外的使用则非常的简单. 只需定义key的hash函数和compare函数即可.
以Java为例, 其把默认的hash函数和equals函数置于顶层的Object基类中.
|
1
2
3
4
5
6
|
class
Object {
public
native
int
hashCode();
public
boolean
equals(Object obj) {
return
(
this
== obj);
}
}
|
所有的子类, 需要重载hashCode和equals就能方便的使用哈希表.
进阶篇:
hash函数的选择需保证一定散列度, 这样才能充分利用空间. 事实上哈希表的使用者, 往往关注hash函数的快速计算和高散列度, 却忽视了其潜在的风险和危机.
1). hash碰撞攻击
前段时间, php爆出hash碰撞的攻击漏洞. 其攻击原理, 简单可概括为: 特定的大量key组合, 让哈希表退化为链表访问, 进而拖慢处理速度, 请求堆积, 最终演变为拒绝服务状态.
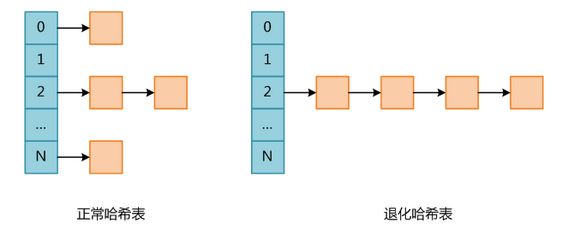
具体可参考博文: PHP哈希表碰撞攻击原理.
大致的思路是利用php哈希表大小为2的幂次, 索引位置计算由 hash(key) % size(bucket) 转变为 hash(key) & (1^n - 1).
![]()
黑客(hacker)知晓time33算法和hash函数, 可以构造/收集特定的key系列, 使得其hash(key)为同一桶索引值. 通过post请求附带, 导致php构造超长链的哈希表.
其实如果能理解hash碰撞攻击的原理, 说明其对hash的冲突处理和哈希表本身的数据结构模型有了较深的理解了.
2). 分段锁机制
如果加锁是不可避免的选择, 那能否减少锁冲突的概率呢?
答案是肯定的, 不同桶之间的key/value操作彼此互不影响. 在此前提下, 对哈希桶进行分段加锁. 这样全局锁就退化为多个分段锁, 而锁冲突的概率由于分区的原因, 降低至1/N (N为分段锁个数).
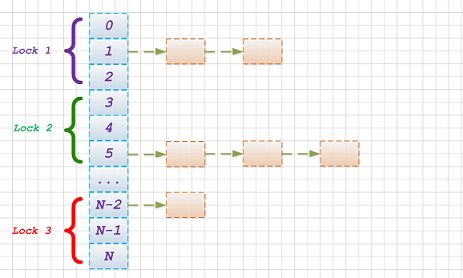
Java并发类中的ConcurrentHashMap也是采用类似的思想来实现, 不过比这复杂多了.
难度篇:
哈希表单key的操作复杂度为O(1), 性能异常优异. 但需要对哈希表进行迭代遍历其所有元素时, 其性能就非常的差. 究其原因是各个key/value对分散在各个桶中, 彼此并无关联. 元素遍历转化为对哈希桶的全扫描.
那如果存在这样的需求, 既要保证O(1)的单key操作时间复杂度, 又要让迭代遍历的复杂度为O(n) (n为哈希表的key/value对个数, 不是桶个数), 那如何去实现呢?
1). LinkedHashMap&LRU缓存
是否存在一个复合数据结构, 既有Hashmap的特性, 又具备DoubleLinkedList线性遍历的特征?
答案是肯定的, 该复合结构就是LinkedHashmap.
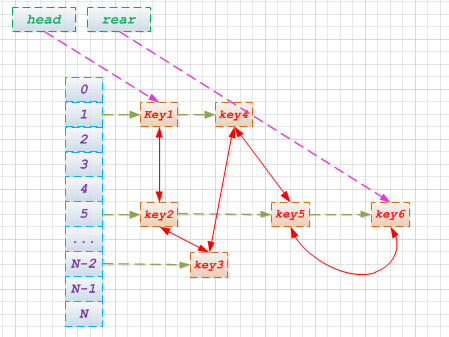
注: 依次添加key1, key2, ..., key6, 其按插入顺序构成一个双向列表.
一图胜千言, 该图很形象的描述了LinkedHashMap的构成. 可以这么认为: 每个hash entry的结构的基础上, 添加prev和next成员指针用于维护双向列表. 实现就这么简单.
在工程实践中, 往往采用LinkedHashMap的变体来实现带LRU机制的Cache.
简单描述其操作流程:
(1). 查询/添加key, 则把该key/value对搁置于LRU队列的末尾
(2). 若key/value对个数超过阈值时, 则选择把LRU队列的首元素淘汰掉.
模拟key5元素被查询访问, 成为最近的热点, 则内部的链接模型状态转变如下:
注: key5被访问后, 内部双向队列发生变动, 可以理解为删除key5, 然后再添加key5至末尾.
JAVA实现带LRU机制的Cache非常的简单, 用如下代码片段描述下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public
class
LRULinkedHashMap
extends
LinkedHashMap
private
int
capacity =
1024
;
public
LRULinkedHashMap(
int
initialCapacity,
float
loadFactor,
int
lruCapacity) {
// access order=> true:访问顺序, false:插入顺序
super
(initialCapacity, loadFactor,
true
);
this
.capacity = lruCapacity;
}
@Override
protected
boolean
removeEldestEntry(Entry
if
(size() > capacity) {
return
true
;
}
return
false
;
}
}
|
注: 需要注意access order为true, 表示按访问顺序维护. 使用Java编程的孩子真幸福.
当哈希表中的元素数量超过预定的阈值时, 就会触发rehash过程. 但是若此时的hash表已然很大, rehash的完整过程会阻塞服务很长时间. 这对高可用高响应的服务是不可想象的灾难.
面对这种情况, 要么避免大数据量的rehash出现, 预先对数据规模进行有效评估. 要么就继续优化哈希的rehash过程.
2). 0/1切换和渐进式rehash
redis的设计者给出了一个很好的解决方案, 就是0/1切换hash表+渐进式rehash.
其渐进的rehash把整个迁移过程拆分为多个细粒度的子过程, 同时0/1切换的hash表共存.
redis的rehash过程分两种方式:
• lazy rehashing: 在对dict操作的时候附带执行一个slot的rehash
• active rehashing:定时做个小时间片的rehash
原文:http://www.cnblogs.com/mumuxinfei/p/4441826.html