规范进行一个爬虫项目【经验分享:参考教学书籍,爬取books.toscrape.com上的书籍信息】
如何规范开始一个python爬虫?传送门:https://blog.csdn.net/GBA_Eagle/article/details/81611348
教学书籍:《精通Scrapy网络爬虫》
项目需求:
爬取http://books.toscrape.com网站中的书籍信息。
(1)信息包括:
书名、价格、评价等级、产品编码、库存量、评价数量。
(2)将爬取结果保存到csv文件中。
具体页面分析:
首先在命令提示符中使用scrapy shell
C:\Users\yi>scrapy shell http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
2018-08-12 23:30:41 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: scrapybot)
... ...
[s] view(response) View response in a browser
>>>
运行这条命令后,scrapy shell会使用url参数构造一个Request对象,并提交给Scrapy引擎,页面下载完成后,程序进入一个python shell(在计算机科学中,Shell俗称壳(用来区别于核),是指“提供使用者使用界面”的软件(命令解析器))中,在此环境中已经创建好了一些变量(对象和函数)。
接下来,在scrapy shell中调用view函数,在浏览器中显示response所包含的页面:
>>> view(response)
可能很多时候view出的页面和浏览器打开的是一样的,但是前者是Scrapy爬虫下载的页面,后者是由浏览器下载的页面,有时它们是不同的。在进行页面分析时,使用view函数更加可靠。

如图所示,我们成功打开了Scrapy下载的页面
接下来我们可以使用谷歌浏览器插件SelectorGadget以及Xpath Helper来帮助我们快捷得到所需内容的Xpath或CSS路径(这只是一种方法,经测试只能在浏览器下载显示的页面使用。若追求可靠性,也可在view中使用传统的“检查”定位元素,总结规律,再在命令提示符中检验;使用插件更方便~)
(谷歌浏览器插件的安装方法:进入Chrome网上应用店https://chrome.google.com/webstore/category/extensions,搜索添加至Chrome即可)
打开谷歌浏览器,输入地址http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
点击右上角的“放大镜”,即SelectorGadget插件,鼠标移动到书籍标题“A Light in the Attic”(翻译:阁楼上的一盏灯)上单击,出现标题的CSS路径,
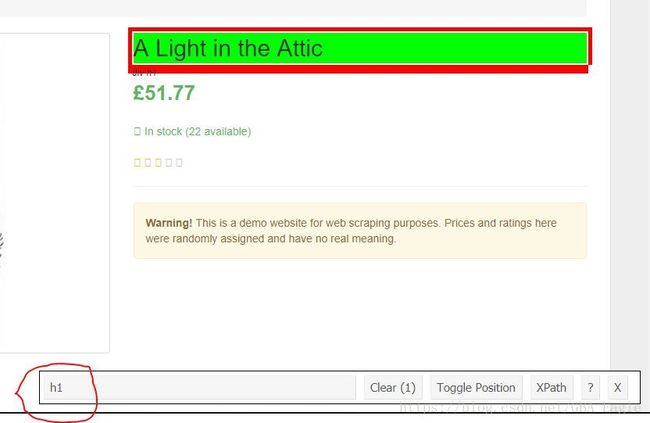
点击右边的“XPath”可以查看标题的Xpath路径
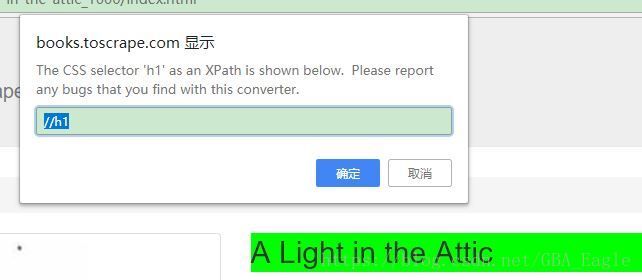
然后因为这个Xpath可能匹配到多个标签,我们在Xpath Helper中测试一下,复制该路径“//h1”,点击Xpath Helper图标(如果是刚安装完可能要刷新页面才能用),页面顶部出现调试框,在左边粘贴我们刚才复制的Xpath路径,右边可出现即时结果:

如图,搜索结果只有“A Light in the Attic”,表明我们成功获取到了标题的Xpath,在命令提示符中测试一下:

接下来如法炮制,获取书籍的其他信息(注意在用SelectorGadget时,每次定位都要清除掉之前的搜索,点击“Clear”按钮完成)
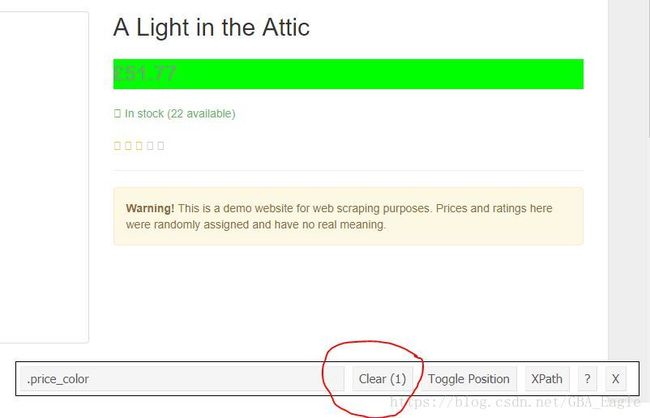
上图是Clear掉“标题”后点击的“价格”,点击Xpath, 我们获取到的“价格”Xpath太长了,如下图
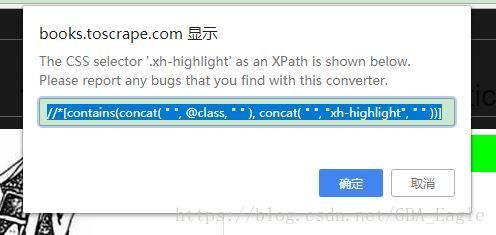
我又去源代码中找了下路径,自己写了一个并测试:

成功获取
接下来获取其他信息:

到此我们成功分析了一个具体的页面(但这只是对当前页面有效,扩展到其他书籍页面可能有问题,这时我们需回到页面分析这一步作更全面的考虑再编写Xpath路径。)。
一级页面分析:
接下来我们考虑如何获取所有书籍的链接,在该部分我们应解决两个问题:
1. 获取页面所有书籍url
2. 获取下一页的url
使用fetch

观察后可以估计,所有书籍的url都在下图标签中:

使用Xpath Helper测试一下:

在右边滚动中查看,成功获取到当前页面所有书籍的url
接下来要获取到下一页的url,我们右键检查页面的“next”按钮:

得到该Xpath路径,同样在Xpah Helper中测试:

成功得到,我们使用LinkExtractor提取这些链接(因为href中的链接跟该站点有联系,直接获取出来的不是绝对url,需要拼接计算,如catalogue/page-2.html是标签中的内容,而正确地址为http://books.toscrape.com/catalogue/page-2.html):
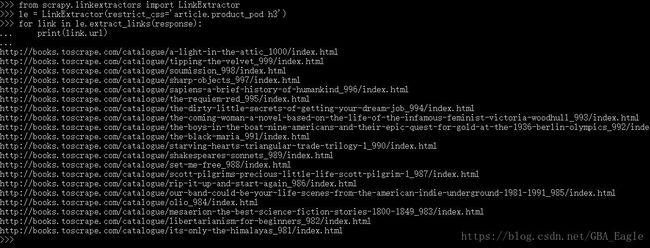
接下来我们提取“next”的链接(每一步都输出下结果,作者对这里也是刚学,帮助理解):
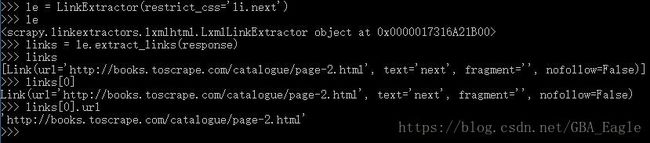
le 是LinkExtractor对象,起到选择器作用,定义选取规则
links 是 le调用extract_links方法,传入当前页面response,在当前页面中根据le规则寻找links,返回Link对象组成的列表
links[0] 是一个Link对象
links[0].url 是对象的一个属性,即我们要的绝对url地址(无需再拼接计算)
到此,我们完成了一级页面解析。
编码实现
接上文:https://blog.csdn.net/GBA_Eagle/article/details/81611348, 我们已经创建了一个爬虫项目,可以开始实现我们自己的爬虫类了
在实现Spider之前,先定义封装书籍信息的Item类,在F:\py_project\example\example\items.py中添加如下代码:
# 书籍项目
class BooksItem(scrapy.Item):
name = scrapy.Field() # 书名
price = scrapy.Field() # 价格
review_rating = scrapy.Field() # 评价等级
review_num = scrapy.Field() # 评价数量
upc = scrapy.Field() # 产品编码
stock = scrapy.Field() # 库存量
接下来我们在爬虫类中要实现两个页面解析函数,一个是书籍列表的解析函数,一个是具体书籍页面的解析函数,打开books.py, 添加代码如下:
class BooksSpider(scrapy.Spider):
name = 'books'
allowed_domains = ['books.toscrapy.com']
start_urls = ['http://books.toscrapy.com/']
# 书籍列表的解析函数
def parse(self, response):
pass
# 具体书籍页面的解析函数
def parse_book(self, response):
pass首先完成列表解析,前面我们已经作了充分准备,代码如下:
def parse(self, response):
# 提取当前页面所有书籍的url
le = LinkExtractor(restrict_css='article.product_pod h3')
for link in le.extract_links(response):
yield scrapy.Request(url=link.url, callback=self.parse_book)
# 如果有下一页,提取下一页的url
le = LinkExtractor(restrict_css='li.next')
links = le.extract_links(response)
if links:
next_url = links[0].url
yield scrapy.Request(url=next_url, callback=self.parse)最后完成页面解析,将信息存入BookItem即可
def parse_book(self, response):
book = BooksItem()
book['name'] = response.xpath('//h1/text()').extract_first()
book['price'] = response.xpath('//p[@class="price_color"]/text()').extract_first()
book['review_rating'] = response.xpath('//div[@class="col-sm-6 product_main"]/p[3]/@class')\
.re_first('star-rating ([A-Za-z]+)')
sel = response.xpath('//table[@class="table table-striped"]')
book['review_num'] = sel.xpath('./tr[last()]/td/text()').extract_first()
book['upc'] = sel.xpath('./tr[1]/td/text()').extract_first()
book['stock'] = sel.xpath('./tr[last()-1]/td/text()').re_first('\((\d+) available\)')
yield book最后整合的books.py代码如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from example.items import BooksItem
class BooksSpider(scrapy.Spider):
name = 'books'
allowed_domains = ['books.toscrape.com']
start_urls = ['http://books.toscrape.com/']
# 书籍列表的解析函数
def parse(self, response):
# 提取当前页面所有书籍的url
le = LinkExtractor(restrict_css='article.product_pod h3')
for link in le.extract_links(response):
yield scrapy.Request(url=link.url, callback=self.parse_book)
# 如果有下一页,提取下一页的url
le = LinkExtractor(restrict_css='li.next')
links = le.extract_links(response)
if links:
next_url = links[0].url
yield scrapy.Request(url=next_url, callback=self.parse)
# 具体书籍页面的解析函数
def parse_book(self, response):
book = BooksItem()
book['name'] = response.xpath('//h1/text()').extract_first()
book['price'] = response.xpath('//p[@class="price_color"]/text()').extract_first()
book['review_rating'] = response.xpath('//div[@class="col-sm-6 product_main"]/p[3]/@class')\
.re_first('star-rating ([A-Za-z]+)')
sel = response.xpath('//table[@class="table table-striped"]')
book['review_num'] = sel.xpath('./tr[last()]/td/text()').extract_first()
book['upc'] = sel.xpath('./tr[1]/td/text()').extract_first()
book['stock'] = sel.xpath('./tr[last()-1]/td/text()').re_first('\((\d+) available\)')
yield book
然后我们可以使用pycharm打开项目,进入settings.py中,设置一下要查看的列的顺序:
# 规定次序
FEED_EXPORT_FIELDS = ['upc', 'name', 'price', 'stock', 'review_rating', 'review_num']在books.py中右键打开控制台,输入scrapy crawl books -o books.csv --nolog保存爬取结果到books.csv文件中,时间可能较长,请耐心等待。完成后,可以到磁盘中查看结果:

打开看看:

如图,获取成功!
到此,完成规范进行一个爬虫项目的操作。
参考书籍:《精通Scrapy网络爬虫》,刘硕编著,清华大学出版社,好看好用的入门书籍,推荐大家阅读~