在scrapy源码中添加功能,对HTTP响应状态码493的url进行保存
在scrapy爬虫过程中,遇到了这样一个问题:
[scrapy.spidermiddlewares.httperror] INFO: Ignoring response <493> HTTP status code is not handled or not allowed
我们翻译一下(百度翻译):
忽略响应< 493 >不处理或不允许HTTP状态代码
经测试,该问题是源于IP代理的设置引起,目标网站可能有阻止代理IP访问的机制,只要关闭IP代理就能得到正确的响应(200)
但是在项目中又不得不使用IP代理,原因很多,例如有一些网站由于网络环境因素,直接爬取速度过慢,使用代理提高爬取速度等
于是只好把出现该问题的url全都保存下来
但是目标网址拒绝访问,连response都没有,怎么保存呢?
这时就需要研究scrapy源代码了
经过一下午的奋斗,终于找到了框架内部根据HTTP错误打印响应码的位置,是在scrapy.spidermiddlewares.httperror文件中
下面是进入该文件的方法
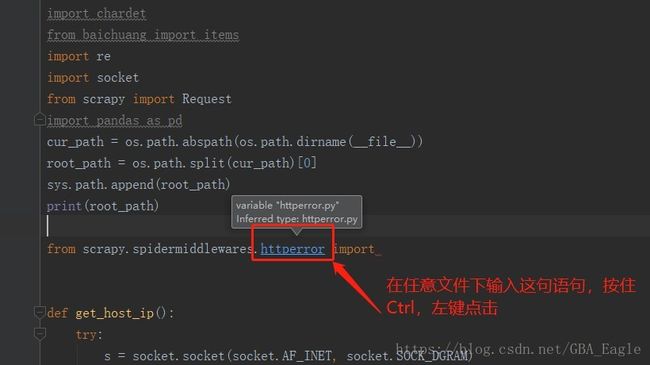
然后我们添加代码,只要是出现493的response,都把它的url取下来:
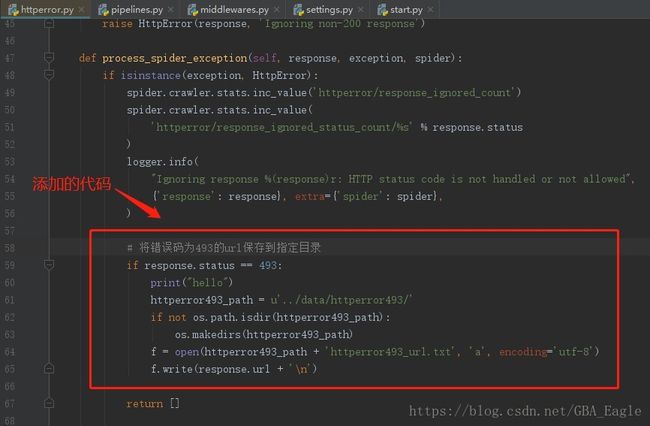
添加的代码:
# 记得在开头import os
# 将错误码为493的url保存到指定目录
if response.status == 493:
httperror493_path = u'../data/httperror493/'
if not os.path.isdir(httperror493_path):
os.makedirs(httperror493_path)
f = open(httperror493_path + 'httperror493_url.txt', 'a', encoding='utf-8')
f.write(response.url + '\n')