Scrapy爬取数据案例
Scrapy爬取数据
昨天练习了一个简单例子,今天进行进一步的学习——爬取同域下的多个网页。
对 Tencent 的招聘信息进行爬取:
腾讯招聘
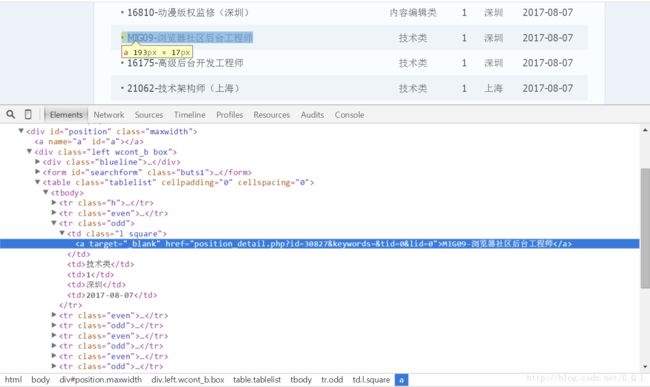
可以看到需要的信息都在< tbody >下的class为even和odd< tr > 标签中。
< tr > 中的需求的数据为职位名、职位链接、职位人数、职位类别、工作地点和发布日期。
使用xpath可以很容易得到这些数据的获取方式:
数据集:xpath(“//tr[@class=’even’] | //tr[@class=’odd’]”)
职位名:xpath(“./td[1]/a/text()”)
职位链接:xpath(“./td[1]/a/@href”)
职位人数:xpath(“./td[3]/text()”)
职位类别:xpath(“./td[2]/text()”)
工作地点:xpath(“./td[4]/text()”)
发布日期:xpath(“./td[5]/text()”)
1.爬取方式一
新建工程Tencent
scrapy startproject Tencent
cd myproject创建spider
scrapy genspider Tenspider “tencent.com”
修改setting
# Obey robots.txt rules ROBOTSTXT_OBEY = FalseITEM_PIPELINES = { 'Tencent.pipelines.TencentPipeline': 300, }编写管道
import json class TencentPipeline(object): def __init__(self): self.f = open("Tencent.json","wb+") def process_item(self, item, spider): content = json.dumps(dict(item),ensure_ascii = False) + ",\n" self.f.write(content.encode("utf-8")) return item def colse_spider(self,spider): self.f.close()编写item
import scrapy class TencentItem(scrapy.Item): #职位名 positio_name = scrapy.Field() #职位链接 position_link = scrapy.Field() #职位类型 poistion_type = scrapy.Field() #招聘的人数 people_num = scrapy.Field() #工作地点 work_location = scrapy.Field() #发布的时间 publish_time = scrapy.Field() pass编写spider
import scrapy from Tencent.items import TencentItem class TenspiderSpider(scrapy.Spider): #爬虫名 name = 'TenSpider' #爬虫的爬取域 allowed_domains = ['tencent.com'] #处理翻页请求 baseURL="http://hr.tencent.com/position.php?&start=" #页面的偏移量,即baseUrl中的start的值 offset = 0 #起始的URL列表 start_urls = [baseURL + str(offset)] def parse(self, response): item = TencentItem() #数据集 node_list = response.xpath("//tr[@class='even'] | //tr[@class='odd']") #提取数据,并将其转换为utf-8编码,然后传入item中 for node in node_list: item["positio_name"] =node.xpath("./td[1]/a/text()").extract() item["position_link"] =node.xpath("./td[1]/a/@href").extract() item["people_num"] =node.xpath("./td[3]/text()").extract() item["work_location"] =node.xpath("./td[4]/text()").extract() item["publish_time"] =node.xpath("./td[5]/text()").extract() #有类别为空的情况 if len(node.xpath("./td[2]/text()")): item["poistion_type"] =node.xpath("./td[2]/text()").extract() else: item["poistion_type"] = "" yield item if self.offset < 2100: self.offset +=10 url = self.baseURL + str(self.offset) yield scrapy.Request(url,callback = self.parse) pass执行spider
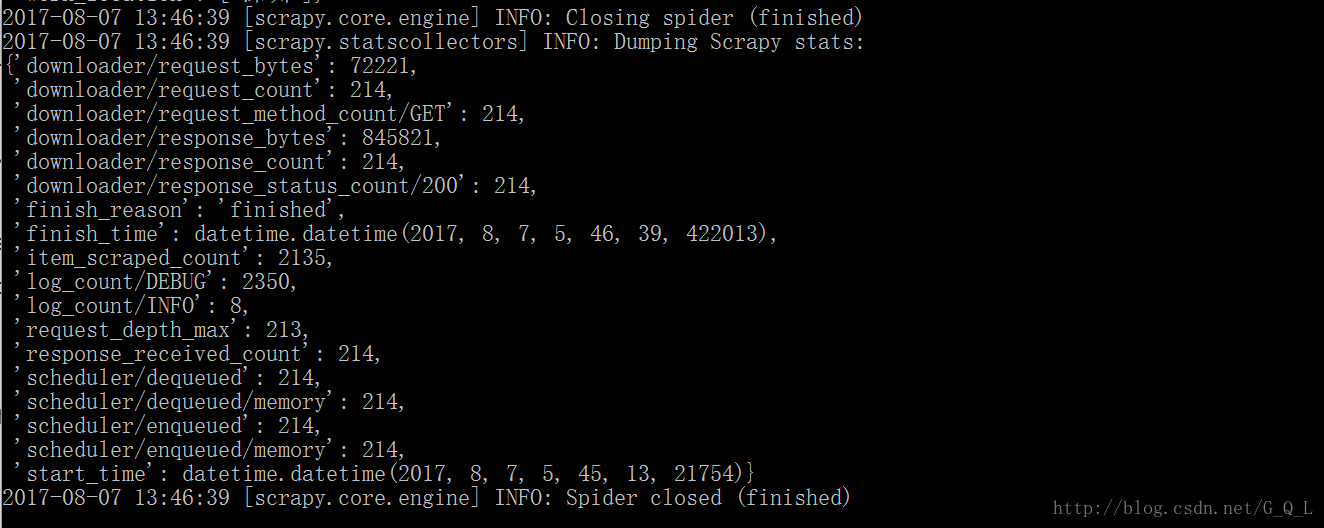
scrapy genspider Tenspider爬取时间花了1分半。。
2.爬取方式二
上面的爬取需要事先确定页数,一旦页数发生变换,代码就得改动,很不方便。这主要是用于无法提取下一页链接的情况。第二种方式是自动提取下一页链接,事先无需知道页数。
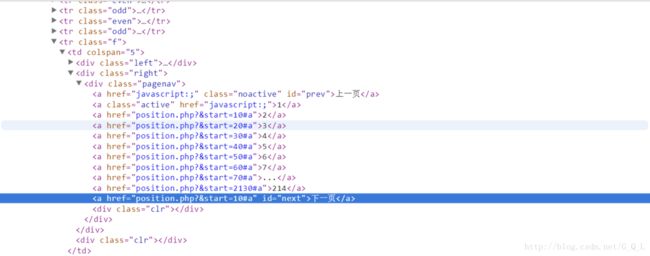
从网页element中可以看到,下一页的导航规律:
第一页的element:
最后一页的element:
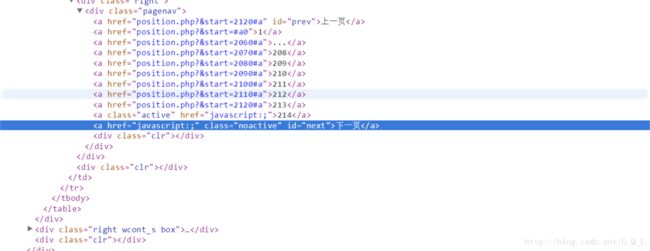
可以看出:终止条件为达到最后一页,即检索到id为next且class为noactive的< a />标签。
所以 xpath(“//a[@id=’next’ and @class=’noactive’]”),只要有匹配项就说明符合终止条件了。
如果没到终止条件,那么就提取出下一页的链接:
xpath(“//a[@id=’next’]/@href”)
方式二爬取数据
找到将方式一的spider文件中的以下代码:
if self.offset < 2100:
self.offset +=10
url = self.baseURL + str(self.offset)
yield scrapy.Request(url,callback = self.parse)替换成:
if len(response.xpath("//a[@id='next' and @class='noactive']")) ==0:
url = response.xpath("//a[@id='next']/@href").extract()[0]
yield scrapy.Request("http://hr.tencent.com/" + url,callback = self.parse)执行spider
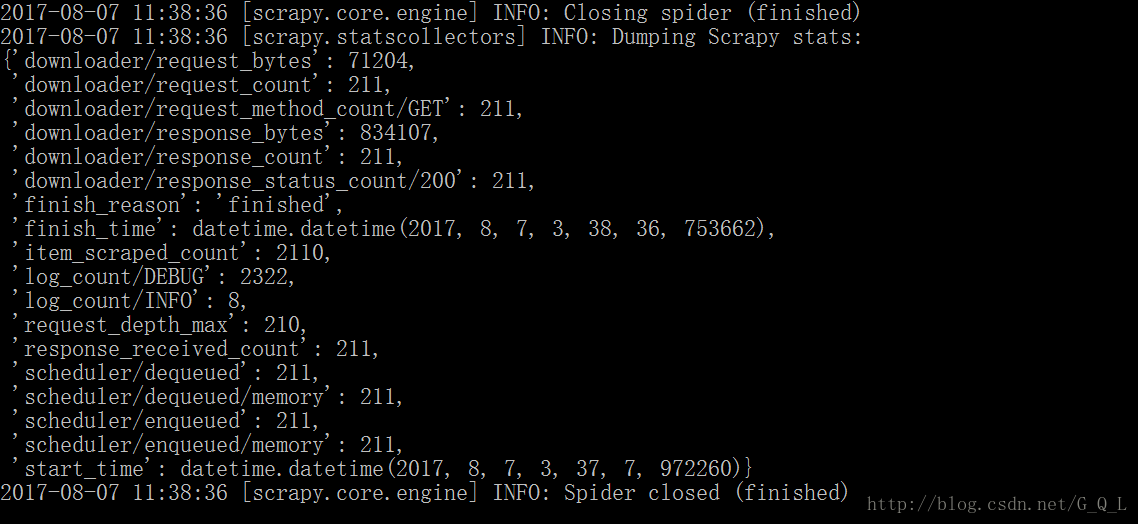
爬取完成: