【论文】RecSys18-序列推荐模型 TransFM(Translation-based Factorization Machines for Sequential Recommendation)
转载请注明出处:https://thinkgamer.blog.csdn.net/article/details/100168818
博主微博:http://weibo.com/234654758
Github:https://github.com/thinkgamer
公众号:搜索与推荐Wiki
序列推荐模型 Translation-based Recommendation参考:点击阅读
概述
论文是由Rajiv Pasricha和Julian McAuley两位大佬提出的发表在RecSys18 上的,是TransRec和FM的结合版本(论文下载地址:https://cseweb.ucsd.edu/~jmcauley/pdfs/recsys18a.pdf)。在下面会简单介绍TransRec和FM。
对于电商网站(如亚马逊),媒体网站(如Netflix,Youtube)等而言,推荐系统是其中至关重要的一环。传统的推荐方法尝试对用户和物品的全局交互进行建模。例如矩阵分解和其派生模型,虽然能够有效的捕获到用户的偏好,但是未考虑到时序特征,其忽略了用户的最近交互行为,提供了一个静态的推荐列表。
序列推荐的目的是基于用户的历史行为序列去预测用户将来的行为。Julian McAuley作为主要作者的另一篇论文(Translation-based Recommendation)提出了“翻译”空间的概念,将物品作为一个点嵌入到“翻译”空间内,用户的序列行为则作为一个翻译向量存在于该空间,然后通过距离计算便根据用户u的当前行为物品i,预测其接下来可能有行为的物品,具体可参考:https://mp.weixin.qq.com/s/YovZKGd2BDqnpW5BBGLA-A。TransRec的主要思路如下图所示:

本论文中提出了TransFM,其结合了FM和TransRec的思想,将其应用在序列推荐中,这样做的好处是使用简单的模型对复杂的交互之间进行建模并能取得不错的效果。
FM能够对任意的实值特征向量进行操作,并通过参数分解对特征之间的高阶交互进行建模。他可以应用在一般的预测任务里,并可以通过特征替换,取代常见的推荐算法模型。
TransFM的主要思路如下图所示:

TransFM是对所有观察到的行为之间可能的交互进行建模,对于每一个特征i,模型学习到两部分:一个低维的embedding向量 v i → \overrightarrow{v_i} vi和一个翻译向量 v i ′ → \overrightarrow{v_i'} vi′
特征之间的交互强度使用平方欧几里德距离来进行计算,在上图中,展示了user,item,time的embedding特征和翻译向量,交互行为之间的权重由起始点和结束点之间的平方欧几里德距离进行计算。与FM一样,TransFM可以在参数和特征纬度的线性时间内进行计算,从而有效的实现大规模数据集的计算。
相关研究
序列推荐
已经存在了许多基于MC(马尔可夫链,Markov Chains)的序列推荐模型,比如FPMC(Factorized Personalized Markov Chains),使用独立分解矩阵对三阶交互行为进行分解,继而来模拟成对的相互作用。PRME使用欧几里德距离替换内积对用户-物品之间的交互行为进行建模。TransRec同样也是一个序列推荐模型,通过共享物品的embedding向量空间,将用户行为转化为翻译向量,其计算公式如下:
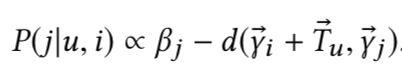
因子分解机
FM对于任意的机器学习任务来讲是一个通用的学习框架,他模型任意任意特征之间的二阶交互,并很容易扩招到更高阶,每个特征的交互通过参数之间的内积来权衡。其公式如下(这里讨论的是FM的二阶形式):
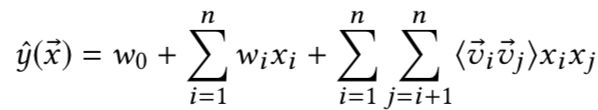
混合推荐
混合推荐结合了协同和conetnt-based,目的在于提升效果并且为行为很较少的用户提供有效的选择,在一定程度上缓解了用户冷启动。这里可以利用的潜在的信息包括:时间特征,地理特征,社交特征等。最近的一些关于混合推荐的工作结合了图像特征,或者是使用深度学习自动生成有用的内容特征。
虽然这些方法都取得了不错的表现,但依赖于专门的模型和技术。相比之间,论文里提出的TransFM是一种更广义的办法,可以对任意的特征向量和预测任务进行操作,通过适当的特征工程,TransFM模型可以结合时间,地理,人口统计和其他内容特征,而无需更改模型本身结构。
TransFM模型
问题定义

TransFM使用平方欧几里德距离替换FM中的内积计算,并用embedding 向量和翻译向量之和表示特征v_i的向量,其公式如下:
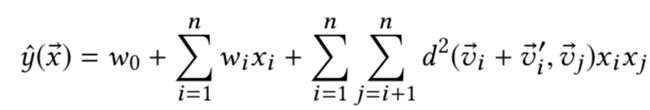
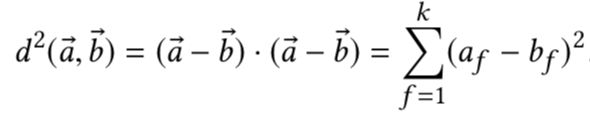
使用平方欧几里德距离替换内积的好处是:提高模型的泛化能力,更有效的捕获embedding之间的传递性。比如(a,b),(b,c)之间有很高的交互权重,那么(a,c)之间的相关性也会更强。
下图展示了TransFM和其他几种算法的预测方法,从中可以看出PRME学习的是两个用户的embedding向量之间的距离,FM学习的是任意特征与相应参数之间的内积,TransRec学习的是物品的embedding向量和用户行为的翻译序列,TransFM学习的是每个特征的embedding向量和翻译向量,使用平方欧几里德距离去度量特征之间的交互。


其次进行化简得:
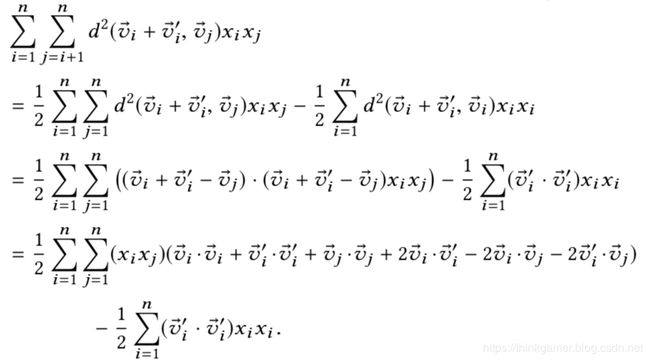
上面的第一个总和可以分成六个单独项,每一项又可以继续进行化简:
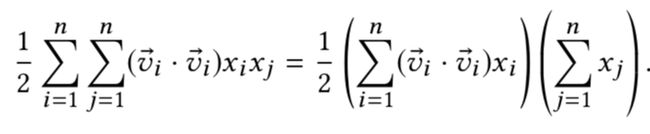
假设输入的特征是n维,隐向量长度为k,那么时间复杂度就是O(nk),而不是O(n^2k)。
参数优化
模型使用S-BPR(Sequential Bayesian Personalized Ranking)进行优化,其优化方式如下:
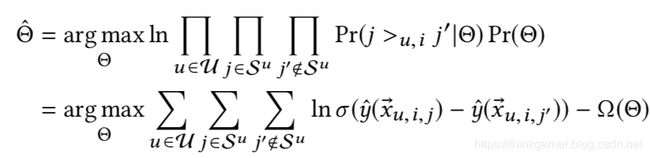
实践和推断
作者等人在TensorFlow中对TransFM进行了实现,用的是mini-batch gradient descent 和 Adam进行模型的训练(adam对于有大量参数且稀疏的数据集上表现良好)。
作者这里也罢代码进行了开源,包括数据集,已经不同算法实现实现对比,其地址为:https://github.com/rpasricha/TransFM
实验
作者结合了一些算法在亚马逊和谷歌数据集上进行测试,其中评价的指标是AUC,效果如下:
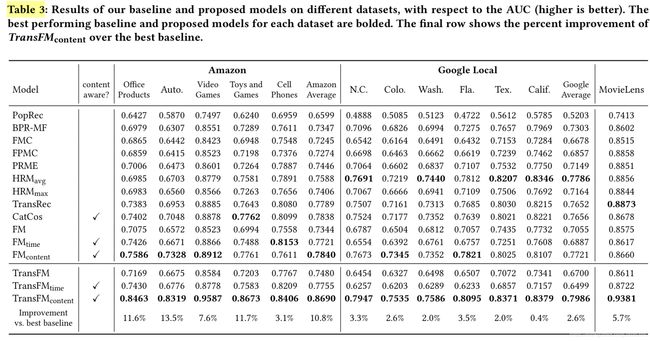
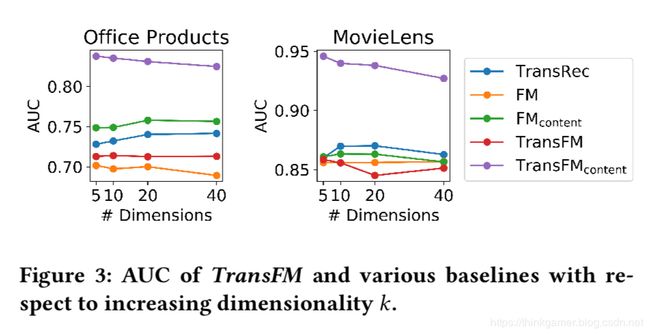
上边的Table 3是指从Amazon选取top5 品类 ,从Google Local 中选取6个城市作为实验依据。
FM模型和其他模型的融合
PRME(Personalized Ranking Metric Embedding)
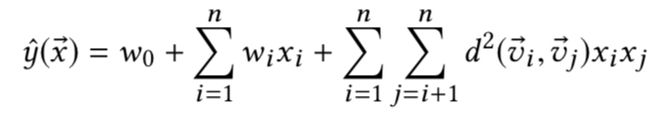
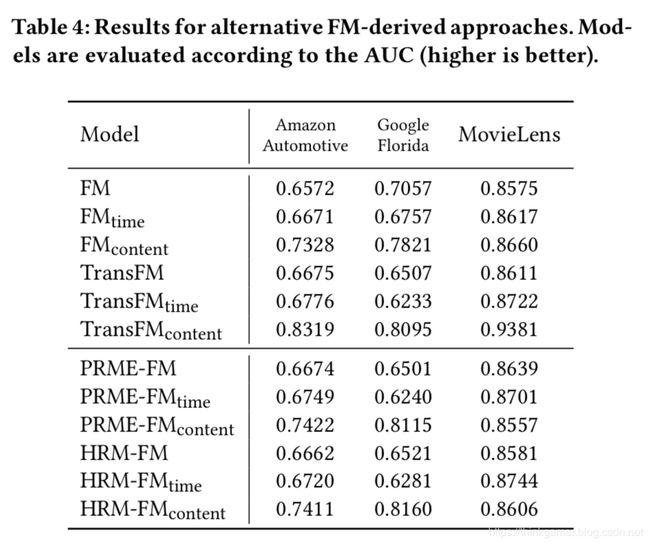
和TransFM对比的不同在于TransFM中i的向量是embedding向量和translation向量和,而这里没有translation向量。实时证明TransFM效果要好很多。
HRM(Hierarchical Representation Model )

对比的实验结果如下:
我的总结
- TransFM结合了TransRec 和 FM和优势,在大量,稀疏的数据集上取得了不错的效果。
- 在参数和特征纬度下,计算时间线性增大(nk)
- 改变FM中的内积计算方式,使用平方欧几里德距离,提高了模型的泛化能力,和样本特征之间的传递性
- 在不改变模型结构的前提下,可以轻易将时间,地域或者其他内容特征加入到模型中
- 数据集拆分时避免了从整体数据集中的随机拆分,而是按照时间先后的顺序进行拆分。保证了一定的时间连续性,很多论文中划分训练集和测试集时都是这样做的,在工业界中模型的训练和评估大部分也是这样做的。
- 根据经验将参数限定在一个范围内,根据网格搜索法寻找最佳参数
- 实验对比的丰富性,使结论更具有说服力

【搜索与推荐Wiki】专注于搜索和推荐系统,尝试使用算法去更好的服务于用户,包括但不局限于机器学习,深度学习,强化学习,自然语言理解,知识图谱,还不定时分享技术,资料,思考等文章!