重拾初心——Sqoop1和Sqoop2的刨析对比

打开微信扫一扫,关注微信公众号【数据与算法联盟】
转载请注明出处: http://blog.csdn.net/gamer_gyt
博主微博: http://weibo.com/234654758
Github: https://github.com/thinkgamer
写在前面的话
或许我们经常会遇到这样一个场景,就是当我们的某种日志数据积累到一定程度的时候,我们需要大数据平台来进行存储,包括hdfs,hive等,这个时候Sqoop就发挥他的巨大价值了。
Sqoop简介
1. Sqoop简单介绍
Sqoop是一款开源的工具,主要用于在Hadoop和传统的数据库(mysql、postgresql等)进行数据的传递,可以将一个关系型数据库(例如:MySQL、Oracle、Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS。
Sqoop目前版本已经到了1.99.7,我们可以在其官网上看到所有的版本,Sqoop1.99.7是属于sqoop2,Sqoop1的最高版本为1.4.6,版本号划分区别,Apache:1.4.x,1.99.x~
2. Sqoop一代和二代对比
版本号对比
两代之间是两个完全不同的版本,不兼容
sqoop1:1.4.x
sqoop2:1.99.
sqoop2比sqoop1的改进
(1) 引入sqoop server,集中化管理connector等
(2) 多种访问方式:CLI,Web UI,REST API
(3) 引入基于角色 的安全机制
sqoop2和sqoop1的功能性对比
| 功能 | Sqoop 1 | Sqoop 2 |
| 用于所有主要 RDBMS 的连接器 | 支持 | 不支持 解决办法: 使用已在以下数据库上执行测试的通用 JDBC 连接器: Microsoft SQL Server 、 PostgreSQL 、 MySQL 和 Oracle 。 此连接器应在任何其它符合 JDBC 要求的数据库上运行。但是,性能可能无法与 Sqoop 中的专用连接器相比 |
| Kerberos 安全集成 | 支持 | 不支持 |
| 数据从 RDBMS 传输至 Hive 或 HBase | 支持 | 不支持 解决办法: 按照此两步方法操作。 将数据从 RDBMS 导入 HDFS 在 Hive 中使用相应的工具和命令(例如 LOAD DATA 语句),手动将数据载入 Hive 或 HBase |
| 数据从 Hive 或 HBase 传输至 RDBMS | 不支持 解决办法: 按照此两步方法操作。 从 Hive 或 HBase 将数据提取至 HDFS (作为文本或 Avro 文件) 使用 Sqoop 将上一步的输出导出至 RDBMS |
不支持 按照与 Sqoop 1 相同的解决方法操作 |
sqoop1和sqoop2的架构对比
(1) : sqoop1的架构图
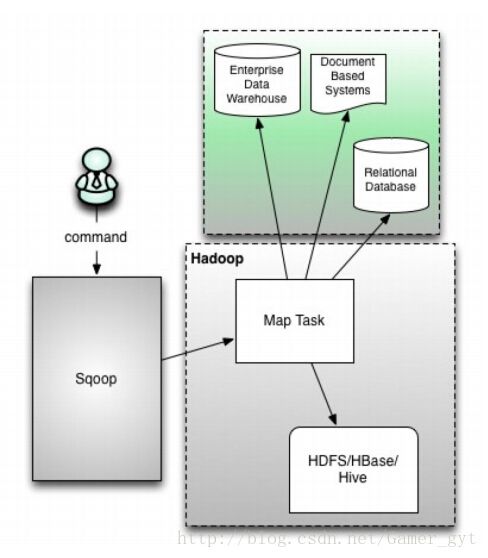
版本号为1.4.x为sqoop1
在架构上:sqoop1使用sqoop客户端直接提交的方式
访问方式:CLI控制台方式进行访问
安全性:命令或脚本中指定用户数据库名及密码
(2) : sqoop2的架构图
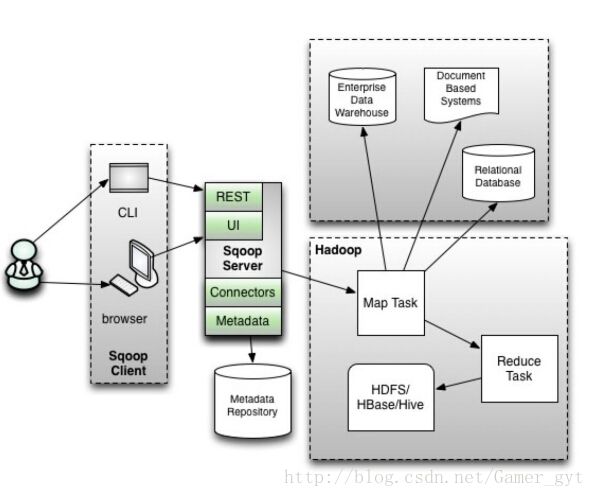
版本号为1.99x为sqoop2
在架构上:sqoop2引入了sqoop server,对connector实现了集中的管理
访问方式:REST API、 JAVA API、 WEB UI以及CLI控制台方式进行访问
CLI方式访问,会通过交互过程界面,输入的密码信息丌被看到,同时Sqoop2引入基亍角色的安全机制,Sqoop2比Sqoop多了一个Server端。
(3) : 优缺点
sqoop1与sqoop2的优缺点如下:
sqoop1的架构,仅仅使用一个sqoop客户端,sqoop2的架构,引入了sqoop server集中化管理connector,以及rest api,web,UI,并引入权限安全机制。
sqoop1与sqoop2优缺点比较 :
sqoop1优点架构部署简单
sqoop1的缺点命令行方式容易出错,格式紧耦合,无法支持所有数据类型,安全机制不够完善,例如密码暴漏,
安装需要root权限,connector必须符合JDBC模型
sqoop2的优点多种交互方式,命令行,web UI,rest API,conncetor集中化管理,所有的链接安装在sqoop server上,完善权限管理机制,connector规范化,仅仅负责数据的读写。
sqoop2的缺点,架构稍复杂,配置部署更繁琐。
Sqoop的部署
1. Sqoop1的部署
sqoop1的部署相对比较简单,以1.4.6为例
(1) 下载:点击链接到下载页
(2) 解压到指定目录
sudo tar -zxvf /home/thinkgamer/下载/sqoop-1.4.6.tar.gz -C
sudo mv sqoop-1.4.6/ sqoop(3) 配置环境变量
sudo vim ~/.bashrc添加以下两行
export SQOOP_HOME=/opt/sqoop
export PATH=$PATH:$SQOOP_HOME/bin保存即可
source ~/.bashrc(4) 复制Mysql-jdbc 包到sqoop/lib目录下
sudo cp /home/thinkgamer/下载/MySQL-connector-Java-5.1.39-bin.jar /opt/bigdata/sqoop/lib/(5) 修改bin/configure-sqoop文件
此时如果没有启用hbase,zookeeper等组件,将相应的信息注释,如果启用了,就pass,直接进入下一步
(6) 执行sqoop help查看帮助
2. Sqoop2的部署
以下部分大部分来自官方安装教程:https://sqoop.apache.org/docs/1.99.7/admin/Installation.html
sqoop的部署相对比较麻烦,因为sqoop2即包含了client端,又包含了server端,官方给出的提示是:
- 服务器您需要在集群中的单个节点上安装服务器。此节点将用作所有Sqoop客户端的入口点。
- 客户端客户端可以安装在任意数量的计算机上。
下载文件解压到指定目录:
sudo tar -zxvf /home/thinkgamer/下载/package/hadoop-family/sqoop-1.99.7.tar.gz /opt/bigdata(1) 目录说明
bin:可执行脚本,一般使用sqoop都是通过这个目录中的工具调用,是一些shell或batch脚本。
conf:存放配置文件
docs:目前不清楚具体是什么,可能是帮助文档,不过一般使用sqoop不会用到。
server:里面只有一个lib目录,存了很多jar文件,是sqoop2 的server包。
shell:同理,sqoop2的shell包。
tools:同理,sqoop2的工具包。
(2) 服务器端安装
2.1 环境变量设置
sqoop的安装依赖于hadoop的环境变量,$HADOOP_COMMON_HOME,$HADOOP_HDFS_HOME, $HADOOP_MAPRED_HOME 和 $HADOOP_YARN_HOME,请你确定这些环境变量被定义和指向了hadoop的安装目录,如果这些没有被正确配置,sqoop server端将不会被正常启动。
如果换将变量里已经配置了$HADOOP_HOME,那么sqoop将会在以下这几个路径中找寻$HADOOP_COMMON_HOME,$HADOOP_HDFS_HOME, $HADOOP_MAPRED_HOME 和 $HADOOP_YARN_HOME
$HADOOP_HOME/share/hadoop/common
$HADOOP_HOME/share/hadoop/hdfs
$HADOOP_HOME/share/hadoop/mapreduce
$HADOOP_HOME/share/hadoop/yarn
若$HADOOP_HOME已经配置了,最好不要再配置下面的变量,可能会有些莫名错误。
2.2 hadoop配置
Sqoop服务器将需要模拟用户访问集群内外的HDFS和其他资源,作为开始给定作业的用户,而不是运行服务器的用户。 您需要配置Hadoop以通过所谓的proxyuser系统显式地允许此模拟。 您需要在core-site.xml文件 - hadoop.proxyuser。$SERVER_USER.hosts和hadoop.proxyuser。$ SERVER_USER.groups中创建两个属性,其中$ SERVER_USER是将运行Sqoop 2服务器的用户。 在大多数情况下,配置*是足够的。
当服务器在sqoop2 user下运行时,需要在core-site.xml文件中配置如下:
<property>
<name>hadoop.proxyuser.sqoop2.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.sqoop2.groupsname>
<value>*value>
property>我是用thinkgamer用户运行hadoop,所以这里将sqoop2换成thinkgamer
2.3 配置第三方jar包引用路径
一般我们使用的数据库驱动包都没有随着Sqoop一起释出,多半是因版权问题,所以将这些包放置在这个第三方组件下。再在配置一个SQOOP_SERVER_EXTRA_LIB系统变量即可,本例指定路径为$SQOOP_HOME/extra
sudo vim ~/.bashrc 加入
export SQOOP_HOME=/opt/bigdata/sqoop
export SQOOP_SERVER_EXTRA_LIB=$SQOOP_HOME/extra
export PATH=$PATH:$SQOOP_HOME/bin最后把mysql的驱动jar文件复制到这个目录下。
2.4 服务器配置
主要是配置conf目录下的sqoop.properties和sqoop_bootstrap.properties两个文件
sqoop_bootstrap.properties文件配置config支持类,这里一般使用默认值即可:
sqoop.config.provider=org.apache.sqoop.core.PropertiesConfigurationProvider sqoop.properties文件配置比较多,这里按需要配置,我写下我配置的项,其他都使用默认值:
org.apache.sqoop.submission.engine.mapreduce.configuration.directory=/opt/bigdata/hadoop/etc/hadoop
org.apache.sqoop.security.authentication.type=SIMPLE
org.apache.sqoop.security.authentication.handler=org.apache.sqoop.security.authentication.SimpleAuthenticationHandler
org.apache.sqoop.security.authentication.anonymous=true 注意:官方文档上只说了配置上面第一项,mapreduce的配置文件路径,但后来运行出现authentication异常,找到sqoop文档描述security部分,发现sqoop2支持hadoop的simple和kerberos两种验证机制。所以配置了一个simple验证,这个异常才消除。
2.5 初始化
元数据存储库需要在第一次启动Sqoop 2服务器之前进行初始化。 使用升级工具初始化存储库:
➜ sqoop sqoop2-tool upgrade
Setting conf dir: /opt/bigdata/sqoop/bin/../conf
Sqoop home directory: /opt/bigdata/sqoop
Sqoop tool executor:
Version: 1.99.7
Revision: 435d5e61b922a32d7bce567fe5fb1a9c0d9b1bbb
Compiled on Tue Jul 19 16:08:27 PDT 2016 by abefine
Running tool: class org.apache.sqoop.tools.tool.UpgradeTool
0 [main] INFO org.apache.sqoop.core.PropertiesConfigurationProvider - Starting config file poller thread
Tool class org.apache.sqoop.tools.tool.UpgradeTool has finished correctly.您可以使用验证工具验证是否已正确配置一切:
sqoop2-tool verify 此时,我在运行的时候报了一个错误:Tool class org.apache.sqoop.tools.tool.VerifyTool has failed.
在LOGDIR目录下,可以从sqoop里看到错误的日志说是权限的问题,
2017-02-16 01:41:34,373 ERROR [org.apache.sqoop.core.SqoopServer.initialize(SqoopServer.java:67)] Failure in server initialization
org.apache.sqoop.common.SqoopException: MAPREDUCE_0002:Failure on submission engine initialization - Invalid Hadoop configuration directory (not a directory or permission issues): /opt/bigdata/hadoop/etc/hadoop
at org.apache.sqoop.submission.mapreduce.MapreduceSubmissionEngine.initialize(MapreduceSubmissionEngine.java:97)
at org.apache.sqoop.driver.JobManager.initialize(JobManager.java:257)
at org.apache.sqoop.core.SqoopServer.initialize(SqoopServer.java:64)
at org.apache.sqoop.tools.tool.VerifyTool.runTool(VerifyTool.java:36)
at org.apache.sqoop.tools.ToolRunner.main(ToolRunner.java:72)解决办法:
我这里是把hadoop的配置文件权限设为775,然后再测试
➜ sqoop sqoop2-tool verify
Setting conf dir: /opt/bigdata/sqoop/bin/../conf
Sqoop home directory: /opt/bigdata/sqoop
Sqoop tool executor:
Version: 1.99.7
Revision: 435d5e61b922a32d7bce567fe5fb1a9c0d9b1bbb
Compiled on Tue Jul 19 16:08:27 PDT 2016 by abefine
Running tool: class org.apache.sqoop.tools.tool.VerifyTool
0 [main] INFO org.apache.sqoop.core.SqoopServer - Initializing Sqoop server.
9 [main] INFO org.apache.sqoop.core.PropertiesConfigurationProvider - Starting config file poller thread
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/bigdata/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/bigdata/hive/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
Verification was successful.
Tool class org.apache.sqoop.tools.tool.VerifyTool has finished correctly.2.6 开启服务器
sqoop2的运行模式不再是sqoop1的一个小工具,而加入了服务器,这样只要能访问到mapreduce配置文件及其开发包,sqoop服务器部署在哪里都无所谓,而客户端shell是不需要任何配置的。直接用即可。
开启服务器:
bin/sqoop2-server start 这时可以通过JDK中的jps工具查看是否已经正确启动起来,正常情况下会有个SqoopJettyServer的进程,这也可以想象,Sqoop server是基于jetty实现的。
注意:请确保Sqoop2服务器已经启动,并确保Hadoop启动。其中Hadoop不仅要启动hdfs(NameNode、DataNode),还要启动yarn(NodeManager、ResourceManager),当然,一般还会有一个SecondaryNameNode,用于原始NameNode的备援进程。
(2) 客户端配置使用
到这里基本sqoop1.99.7已经配置完毕了,至于客户端就是启动,进行使用
sqoop2-shell会进入sqoop的交互终端,输入help或者\h可以查看帮助
For information about Sqoop, visit: http://sqoop.apache.org/
Available commands:
:exit (:x ) Exit the shell
:history (:H ) Display, manage and recall edit-line history
help (\h ) Display this help message
set (\st ) Configure various client options and settings
show (\sh ) Display various objects and configuration options
create (\cr ) Create new object in Sqoop repository
delete (\d ) Delete existing object in Sqoop repository
update (\up ) Update objects in Sqoop repository
clone (\cl ) Create new object based on existing one
start (\sta) Start job
stop (\stp) Stop job
status (\stu) Display status of a job
enable (\en ) Enable object in Sqoop repository
disable (\di ) Disable object in Sqoop repository
grant (\g ) Grant access to roles and assign privileges
revoke (\r ) Revoke access from roles and remove privileges
For help on a specific command type: help commandsqoop2的使用
1:sqoop1的使用
对于sqoop1的使用没有专门写过文章,最主要的原因还是使用的少,发现的问题也就相对少了
至于sqoop1的使用可以参考这位网友的example:http://blog.csdn.net/gdmzlhj1/article/details/50483171
2:sqoop2的使用介绍
sqoop2的启动说明
sqoop2客户端支持两种模式运行,shell终端交互模式和批处理模式
终端模式为:sqoop2-shell
批处理模式:sqoop2-shell /path/to/your/script.sqoop
Sqoop客户端脚本应包含有效的Sqoop客户端命令,空行和以#开头的表示注释行的行。 忽略注释和空行,解释所有其他行。 示例脚本:
# Specify company server
set server --host sqoop2.company.net
# Executing given job
start job --name 1sqoop2客户端具有类似于其他命令行工具加载资源文件的能力,在执行开始时,Sqoop客户端将检查当前记录的用户的主目录中是否存在文件.sqoop2rc。如果此类文件存在,sqoop2客户端启动的时候将会被加载和解释,他可以用于执行任何批处理兼容命令。例如:
# Configure our Sqoop 2 server automatically
set server --host sqoop2.company.net
# Run in verbose mode by default
set option --name verbose --value trueSqoop2的核心概念
由于sqoop2是C-S架构,Sqoop的用户都必须通过sqoop-client类来与服务器交互,sqoop-client提供给用户的有:
- 连接服务器
- 搜索connectors
- 创建Link
- 创建Job
- 提交Job
- 返回Job运行信息等功能
这些基本功能包含了用户在数据迁移的过程中所用到的所有信息。
sqoop2中将数据迁移任务中的相关概念进行细分。将数据迁移任务中的数据源, 数据传输配置, 数据传输任务进行提取抽象。经过抽象分别得到核心概念Connector, Link, Job, Driver。
(1)connector
sqoop2中预定一了各种里链接,这些链接是一些配置模板,比如最基本的generic-jdbc-connector,还有hdfs-connector,通过这些模板,可以创建出对应数据源的link,比如我们链接mysql,就是使用JDBC的方式进行链接,这时候就从这个generic-jdbc-connector模板继承出一个link,可以这么理解。
(2)link
Connector是和数据源(类型)相关的。对于Link是和具体的任务Job相关的。
针对具体的Job, 例如从MySQL->HDFS 的数据迁移Job。就需要针对该Job创建和数据源MySQL的Link1,和数据目的地MySQL的Link2.
Link是和Job相关的, 针对特定的数据源,配置信息。
Link定义了从某一个数据源读出和写入时的配置信息。
(3)job
Link定义了从某一个数据源的进行读出和写入时的配置信息。Job是从一个数据源读出, 写入到另外的一个数据源的过程。
所以Job需要由Link(From), Link(To),以及Driver的信息组成。
(4)Dirver
提供了对于Job任务运行的其他信息。比如对Map/Reduce任务的配置。
终端使用介绍
set
| 函数 | 说明 |
|---|---|
| server | 设置服务器连接 |
| option | 设置各种客户端选项 |
(1) set server
| 参数 | 默认值 | 描述 |
|---|---|---|
| -h ,–host | localhost | sqoop server 运行的服务器地址 |
| -p, –port | 12000 | TCP 端口 |
| -w, –webapp | sqoop | jetty服务器名称 |
| -u, –url | url格式的sqoop服务器 |
example:
sqoop:000> set server --host localhost --port 12000 --weapp sqoop
Invalid command invocation: Unknown option encountered: --weapp
sqoop:000> set server --host localhost --port 12000 --webapp sqoop
Server is set successfully
sqoop:000> show version --all
client version:
Sqoop 1.99.7 source revision 435d5e61b922a32d7bce567fe5fb1a9c0d9b1bbb
Compiled by abefine on Tue Jul 19 16:08:27 PDT 2016
0 [main] WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
server version:
Sqoop 1.99.7 source revision 435d5e61b922a32d7bce567fe5fb1a9c0d9b1bbb
Compiled by abefine on Tue Jul 19 16:08:27 PDT 2016
API versions:
[v1]执行show version –all 之后会正确显示server的版本信息,说明连接OK
(2) set option
配置Sqoop客户端相关选项。 此函数具有两个必需的参数名称和值。 Name表示内部属性名称,值保存应设置的新值。 可用选项名称列表如下:
| 选项名称 | 默认值 | 描述 |
|---|---|---|
| verbose | false | 如果启用详细模式,客户端将打印附加信息 |
| poll-timeout | 10000 | 服务器轮询超时(以毫秒为单位) |
example:
set option --name verbose --value true
set option --name poll-timeout --value 20000show
(1) show server
| Argument | Description |
|---|---|
| -a, –all | Show all connection related information (host, port, webapp) |
| -h, –host | Show host |
| -p, –port | Show port |
| -w, –webapp | Show web application name |
example:
sqoop:000> show server -all
Server host: localhost
Server port: 12000
Server webapp: sqoop(2) show option
| Argument | Description |
|---|---|
| -n, –name | Show client option value with given name |
example:
sqoop:000> show option --name verbose
Verbose = true
sqoop:000> show option --name poll-timeout
Poll-timeout = 20000(3) show version
| Argument | Description |
|---|---|
| -a, –all | Show all versions (server, client, api) |
| -c, –client | Show client build version |
| -s, –server | Show server build version |
| -p, –api | Show supported api versions |
example:
sqoop:000> show version -all
client version:
Sqoop 1.99.7 source revision 435d5e61b922a32d7bce567fe5fb1a9c0d9b1bbb
Compiled by abefine on Tue Jul 19 16:08:27 PDT 2016
server version:
Sqoop 1.99.7 source revision 435d5e61b922a32d7bce567fe5fb1a9c0d9b1bbb
Compiled by abefine on Tue Jul 19 16:08:27 PDT 2016
API versions:
[v1](4) show connector
| Argument | Description |
|---|---|
| -a, –all | Show information for all connectors |
| -c, –cid | Show information for connector with id |
example:
sqoop:000> show connector
+------------------------+---------+------------------------------------------------------------+----------------------+
| Name | Version | Class | Supported Directions |
+------------------------+---------+------------------------------------------------------------+----------------------+
| generic-jdbc-connector | 1.99.7 | org.apache.sqoop.connector.jdbc.GenericJdbcConnector | FROM/TO |
| kite-connector | 1.99.7 | org.apache.sqoop.connector.kite.KiteConnector | FROM/TO |
| oracle-jdbc-connector | 1.99.7 | org.apache.sqoop.connector.jdbc.oracle.OracleJdbcConnector | FROM/TO |
| ftp-connector | 1.99.7 | org.apache.sqoop.connector.ftp.FtpConnector | TO |
| hdfs-connector | 1.99.7 | org.apache.sqoop.connector.hdfs.HdfsConnector | FROM/TO |
| kafka-connector | 1.99.7 | org.apache.sqoop.connector.kafka.KafkaConnector | TO |
| sftp-connector | 1.99.7 | org.apache.sqoop.connector.sftp.SftpConnector | TO |
+------------------------+---------+------------------------------------------------------------+----------------------+show connector -all 会输出更详细的信息
(5) show driver
sqoop:000> show driver
Driver specific options:
Persistent id: 8
Job config 1:
Name: throttlingConfig
Label: Throttling resources
Help: Set throttling boundaries to not overload your systems
Input 1:
Name: throttlingConfig.numExtractors
Label: Extractors
Help: Number of extractors that Sqoop will use
Type: INTEGER
Sensitive: false
Editable By: ANY
Overrides:
Input 2:
Name: throttlingConfig.numLoaders
Label: Loaders
Help: Number of loaders that Sqoop will use
Type: INTEGER
Sensitive: false
Editable By: ANY
Overrides:
Job config 2:
Name: jarConfig
Label: Classpath configuration
Help: Classpath configuration specific to the driver
Input 1:
Name: jarConfig.extraJars
Label: Extra mapper jars
Help: A list of the FQDNs of additional jars that are needed to execute the job
Type: LIST
Sensitive: false
Editable By: ANY
Overrides: (6) show link
| Argument | Description |
|---|---|
| -a, –all | Show all available links |
| -n, –name | Show link with name |
sqoop:000> show link --all or show link --name linkName
0 link(s) to show: (7) show job function
| Argument | Description |
|---|---|
| -a, –all | Show all available jobs |
| -n, –name | Show job with name |
example:
show job --all or show job --name jobName(8) show submission function
| Argument | Description |
|---|---|
| -j, –job | Show available submissions for given job name |
| -d, –detail | Show job submissions in full details |
example:
show submission
show submission --j jobName
show submission --job jobName --detailcreate
创建新的链接和作业对象。 此命令仅在交互模式下受支持。 当分别创建链接和作业对象时,将要求用户输入来自/到的驱动程序的链接配置和作业配置。
| Function | Description |
|---|---|
| link | Create new link object |
| job | Create new job object |
(1) create link
| Argument | Description |
|---|---|
| -c, –connector | Create new link object for connector with name |
example:
create link –connector connectorName or create link -c connectorName
sqoop:000> create link --connector hdfs-connector
Creating link for connector with name hdfs-connector
Please fill following values to create new link object
Name: hdfsCN
HDFS cluster
URI: localhost:9200
Conf directory: /opt/bigdata/hadoop/
Additional configs::
There are currently 0 values in the map:
entry#
New link was successfully created with validation status OK and name hdfsCN
sqoop:000> show link
+--------+----------------+---------+
| Name | Connector Name | Enabled |
+--------+----------------+---------+
| hdfsCN | hdfs-connector | true |
+--------+----------------+---------+(2) create job
| Argument | Description |
|---|---|
| -f, –from | Create new job object with a FROM link with name |
| -t, –to | Create new job object with a TO link with name |
example:
create job –from fromLinkName –to toLinkName or create job –f fromLinkName –t toLinkName
update
更新命令允许您编辑链接和作业对象。 此命令仅在交互模式下受支持。
(1) udpate link
| Argument | Description |
|---|---|
| -n, –name | Update existing link with name |
example:
update link –name linkName
(2) update job
| Argument | Description |
|---|---|
| -n, –name | Update existing job object with name |
example:
update job –name jobName
delete
删除与Sqoop server的连接或作业
(1) delete link
| Argument | Description |
|---|---|
| -n, –name | Delete link object with name |
example:
delete link –name linkNam
(2) delete job
| Argument | Description |
|---|---|
| -n, –name | Delete job object with name |
example:
delete job –name jobName
clone
Clone命令将从Sqoop服务器加载现有链接或作业对象,并允许用户进行适当的更新,这将导致创建新的链接或作业对象。 批处理模式不支持此命令。
(1) clone link
| Argument | Description |
|---|---|
| -n, –name | Clone link object with name |
example:
clone link –name linkName
(2) clone job
| Argument | Description |
|---|---|
| -n, –name | Clone job object with name |
example:
clone job –name jobName
start
启动命令将开始执行现有的Sqoop作业。
开始作业(提交新提交)。 启动已在运行的作业被视为无效操作。
| Argument | Description |
|---|---|
| -n, –name | Start job with name |
| -s, –synchronous | Synchoronous job execution |
example:
start job –name jobName
start job –name jobName –synchronous
stop
停止命令将中断作业执行。
停止正在运行的作业
| Argument | Description |
|---|---|
| -n, –name | Interrupt running job with name |
example:
stop job –name jobName
status
状态命令将检索作业的最后状态。
检索给定作业的最后状态。
| Argument | Description |
|---|---|
| -n, –name | Retrieve status for job with name |
example:
status job –name jobName