Hadoop教程(一):简介、大数据解决方案、介绍快速入门
“90%的世界数据在过去的几年中产生”。
由于新技术,设备和类似的社交网站通信装置的出现,人类产生的数据量每年都在迅速增长。美国从一开始的时候到2003年产生的数据量为5十亿千兆字节。如果以堆放的数据磁盘的形式,它可以填补整个足球场。在2011年创建相同数据量只需要两天,在2013年该速率仍在每十分钟极大地增长。虽然生产的所有这些信息是有意义的,处理起来有用的,但是它被忽略了。
什么是大数据?
大数据是不能用传统的计算技术处理的大型数据集的集合。它不是一个单一的技术或工具,而是涉及的业务和技术的许多领域。
在大数据会发生什么?
大数据包括通过不同的设备和应用程序所产生的数据。下面给出的是一些在数据的框架下的领域。
-
黑匣子数据:这是直升机,飞机,喷气机的一个组成部分,它捕获飞行机组的声音,麦克风和耳机的录音,以及飞机的性能信息。
-
社会化媒体数据:社会化媒体,如Facebook和Twitter保持信息发布的数百万世界各地的人的意见观点。
-
证券交易所数据:交易所数据保存有关的“买入”和“卖出”,客户由不同的公司所占的份额决定的信息。
-
电网数据:电网数据保持相对于基站所消耗的特定节点的信息。
-
交通运输数据:交通数据包括车辆的型号,容量,距离和可用性。
-
搜索引擎数据:搜索引擎获取大量来自不同数据库中的数据。

因此,大数据包括体积庞大,高流速和可扩展的各种数据。它的数据为三种类型。
-
结构化数据:关系数据。
-
半结构化数据:XML数据。
-
非结构化数据:Word, PDF, 文本,媒体日志。
大数据的好处
-
通过保留了社交网络如Facebook的信息,市场营销机构了解可以他们的活动,促销等广告媒介的响应。
-
利用信息计划生产在社会化媒体一样喜好并让消费者对产品的认知,产品企业和零售企业。
-
使用关于患者以前的病历资料,医院提供更好的和快速的服务。
大数据技术
大数据的技术是在提供更准确的分析,这可能影响更多的具体决策导致更大的运行效率,降低成本,并减少了对业务的风险。
为了利用大数据的力量,需要管理和处理的实时结构化和非结构化的海量数据,可以保护数据隐私和安全的基础设施。
目前在市场上的各种技术,从不同的供应商,包括亚马逊,IBM,微软等来处理大数据。尽管找到了处理大数据的技术,我们研究了以下两类技术:
操作大数据
这些包括像MongoDB系统,提供业务实时的能力,这里主要是数据捕获和存储互动工作。
NoSQL大数据系统的设计充分利用已经出现在过去的十年,而让大量的计算,以廉价,高效地运行新的云计算架构的优势。这使得运营大数据工作负载更容易管理,更便宜,更快的实现。
一些NoSQL系统可以提供深入了解基于使用最少的编码无需数据科学家和额外的基础架构的实时数据模式。
分析大数据
这些包括,如大规模并行处理(MPP)数据库系统和MapReduce提供用于回顾性和复杂的分析,可能触及大部分或全部数据的分析能力的系统。
MapReduce提供分析数据的基础上,MapReduce可以按比例增加从单个服务器向成千上万的高端和低端机的互补SQL提供的功能,这是系统的一种新方法。
这两个类技术是互补的,并经常一起部署。
操作与分析系统
| 操作 | 分析 | |
|---|---|---|
| 等待时间 | 1 ms - 100 ms | 1 min - 100 min |
| 并发 | 1000 - 100,000 | 1 - 10 |
| 访问模式 | 写入和读取 | 读取 |
| 查询 | 选择 | 非选择性 |
| 数据范围 | 操作 | 回溯 |
| 最终用户 | 顾客 | 数据科学家 |
| 技术 | NoSQL | MapReduce, MPP 数据库 |
大数据的挑战
大数据相关的主要挑战如下:
- 采集数据
- 策展
- 存储
- 搜索
- 分享
- 传输
- 分析
- 展示
为了实现上述挑战,企业通常需要企业级服务器的帮助。
传统的企业方法
在这种方法中,一个企业将有一个计算机存储和处理大数据。对于存储而言,程序员会自己选择的数据库厂商,如Oracle,IBM等的帮助下完成,用户交互使用应用程序进而获取并处理数据存储和分析。
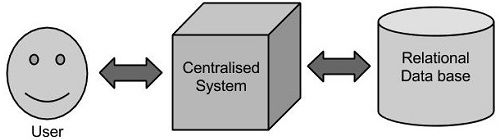
局限性
这种方式能完美地处理那些可以由标准的数据库服务器来存储,或直至处理数据的处理器的限制少的大量数据应用程序。但是,当涉及到处理大量的可伸缩数据,这是一个繁忙的任务,只能通过单一的数据库瓶颈来处理这些数据。
谷歌的解决方案
使用一种称为MapReduce的算法谷歌解决了这个问题。这个算法将任务分成小份,并将它们分配到多台计算机,并且从这些机器收集结果并综合,形成了结果数据集。

Hadoop
使用谷歌提供的解决方案,Doug Cutting和他的团队开发了一个开源项目叫做HADOOP。
Hadoop使用的MapReduce算法运行,其中数据在使用其他并行处理的应用程序。总之,Hadoop用于开发可以执行完整的统计分析大数据的应用程序。

Apache Hadoop 是用于开发在分布式计算环境中执行的数据处理应用程序的框架。类似于在个人计算机系统的本地文件系统的数据,在 Hadoop 数据保存在被称为作为Hadoop分布式文件系统的分布式文件系统。处理模型是基于“数据局部性”的概念,其中的计算逻辑被发送到包含数据的集群节点(服务器)。这个计算逻辑不过是写在编译的高级语言程序,例如 Java. 这样的程序来处理Hadoop 存储 的 HDFS 数据。
Hadoop是一个开源软件框架。使用Hadoop构建的应用程序都分布在集群计算机商业大型数据集上运行。商业电脑便宜并广泛使用。这些主要是在低成本计算上实现更大的计算能力非常有用。你造吗? 计算机集群由一组多个处理单元(存储磁盘+处理器),其被连接到彼此,并作为一个单一的系统。
Hadoop的组件
下图显示了 Hadoop 生态系统的各种组件

Apache Hadoop 由两个子项目组成 -
-
Hadoop MapReduce : MapReduce 是一种计算模型及软件架构,编写在Hadoop上运行的应用程序。这些MapReduce程序能够对大型集群计算节点并行处理大量的数据。
-
HDFS (Hadoop Distributed File System): HDFS 处理 Hadoop 应用程序的存储部分。 MapReduce应用使用来自HDFS的数据。 HDFS创建数据块的多个副本,并集群分发它们到计算节点。这种分配使得应用可靠和极其迅速的计算。
虽然 Hadoop 是因为 MapReduce 和分布式文件系统 - HDFS 而最出名的, 该术语也是在分布式计算和大规模数据处理的框架下的相关项目。 Apache Hadoop 的其他相关的项目包括有:Hive, HBase, Mahout, Sqoop , Flume 和 ZooKeeper.
Hadoop 功能
• 适用于大数据分析
作为大数据在自然界中趋于分布和非结构化,Hadoop 集群最适合于大数据的分析。因为,它处理逻辑(未实际数据)流向计算节点,更少的网络带宽消耗。这个概念被称为数据区域性概念,它可以帮助提高基于 Hadoop 应用程序的效率。
• 可扩展性
HADOOP集群通过增加附加群集节点可以容易地扩展到任何程度,并允许大数据的增长。 另外,标度不要求修改到应用程序逻辑。
• 容错
HADOOP生态系统有一个规定,来复制输入数据到其他群集节点。这样一来,在集群某一节点有故障的情况下,数据处理仍然可以继续,通过使用存储另一个群集节点上的数据。
网络拓扑中的Hadoop
网络拓扑结构(布局),当 Hadoop 集群的大小增长会影响到 Hadoop 集群的性能。除了性能,人们还需要关心故障的高可用性和处理。为了实现这个Hadoop集群构造,利用了网络拓扑。

通常情况下,网络带宽是任何网络要考虑的一个重要因素。然而,测量带宽可能是比较困难的,在 Hadoop 中,网络被表示为树,在 Hadoop 集群节点之间树(跳数)的距离是一个重要因素。在这里,两个节点之间的距离等于自己最近的公共祖先总距离。
Hadoop集群包括数据中心,机架和其实际执行作业的节点。这里,数据中心包括机架,机架是由节点组成。可用网络带宽进程的变化取决于进程的位置。 也就是说,可用带宽变得更小,因为 -
- 在同一个节点上的进程
- 同一机架上的不同节点
- 在相同的数据中心的不同的机架节点
- 在不同的数据中心节点
from: http://www.yiibai.com/hadoop/