Hadoop教程(五):Flume、Sqoop、Pig、Hive、OOZIE
在我们了解Flume和Sqoop之前,让我们研究数据加载到Hadoop的问题:
使用Hadoop分析处理数据,需要装载大量从不同来源的数据到Hadoop集群。
从不同来源大容量的数据加载到Hadoop,然后这个过程处理它,这具有一定的挑战。
维护和确保数据的一致性,并确保资源的有效利用,选择正确的方法进行数据加载前有一些因素是要考虑的。
主要问题:
1. 使用脚本加载数据
传统的使用脚本加载数据的方法,不适合于大容量数据加载到 Hadoop;这种方法效率低且非常耗时。
2. 通过 Map-Reduce 应用程序直接访问外部数据
提供了直接访问驻留在外部系统中的数据(不加载到Hadopp)到map reduce,这些应用程序复杂性。所以,这种方法是不可行的。
3.除了具有庞大的数据的工作能力,Hadoop可以在几种不同形式的数据上工作。这样,装载此类异构数据到Hadoop,不同的工具已经被开发。Sqoop和Flume 就是这样的数据加载工具。
SQOOP介绍
Apache Sqoop(SQL到Hadoop)被设计为支持批量从结构化数据存储导入数据到HDFS,如关系数据库,企业级数据仓库和NoSQL系统。Sqoop是基于一个连接器体系结构,它支持插件来提供连接到新的外部系统。
一个Sqoop 使用的例子是,一个企业运行在夜间使用 Sqoop 导入当天的生产负荷交易的RDBMS 数据到 Hive 数据仓库作进一步分析。
Sqoop 连接器
现有数据库管理系统的设计充分考虑了SQL标准。但是,每个不同的 DBMS 方言化到某种程度。因此,这种差异带来的挑战,当涉及到整个系统的数据传输。Sqoop连接器就是用来解决这些挑战的组件。
Sqoop和外部存储系统之间的数据传输在 Sqoop 连接器的帮助下使得有可能。
Sqoop 连接器与各种流行的关系型数据库,包括:MySQL, PostgreSQL, Oracle, SQL Server 和 DB2 工作。每个这些连接器知道如何与它的相关联的数据库管理系统进行交互。 还有用于连接到支持Java JDBC协议的任何数据库的通用JDBC连接器。 此外,Sqoop提供优化MySQL和PostgreSQL连接器使用数据库特定的API,以有效地执行批量传输。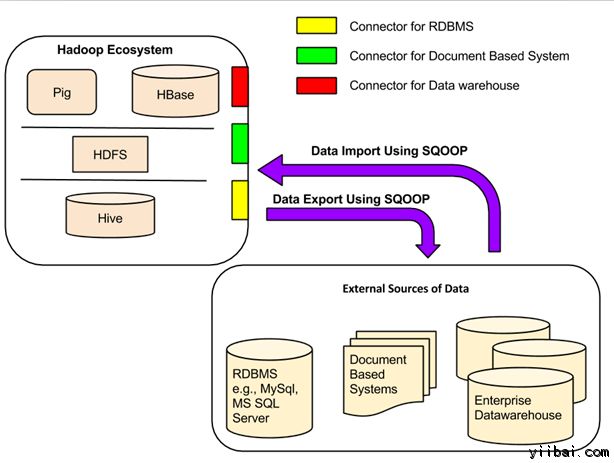
除了这一点,Sqoop具有各种第三方连接器用于数据存储,
从企业数据仓库(包括Netezza公司,Teradata和甲骨文)到 NoSQL存储(如Couchbase)。但是,这些连接器没有配备Sqoop束; 这些需要单独下载并很容易地安装添加到现有的Sqoop。
FLUME 介绍
Apache Flume 用于移动大规模批量流数据到 HDFS 系统。从Web服务器收集当前日志文件数据到HDFS聚集用于分析,一个常见的用例是Flume。
Flume 支持多种来源,如:
-
“tail”(从本地文件,该文件的管道数据和通过Flume写入 HDFS,类似于Unix命令“tail”)
-
系统日志
-
Apache log4j (允许Java应用程序通过Flume事件写入到HDFS文件)。
在 Flume 的数据流
Flume代理是JVM进程,里面有3个组成部分 - Flume Source, Flume Channel 和 Flume Sink -通过该事件传播发起在外部源之后。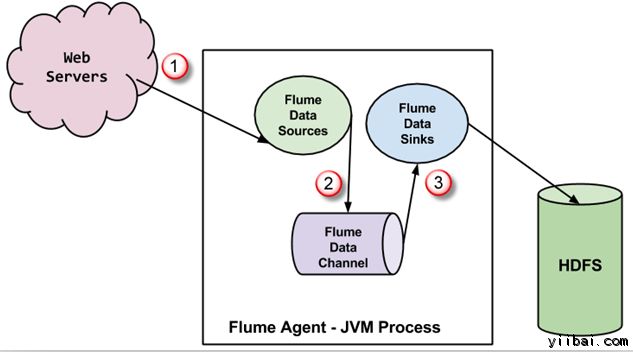
-
在上面的图中,由外部源(Web服务器)生成的事件是由Flume数据源消耗。 外部源将事件以目标源识别的格式发送给 Flume 源。
-
Flume 源接收到一个事件,并将其存储到一个或多个信道。信道充当存储事件,直到它由 flume消耗。此信道可能使用本地文件系统以便存储这些事件。
-
Flume 将删除信道,并存储事件到如HDFS外部存储库。可能会有多个 flume 代理,在这种情况下,flume将事件转发到下一个flume代理。
FLUME 一些重要特性
-
Flume 基于流媒体数据流灵活的设计。这是容错和强大的多故障切换和恢复机制。 Flume 有不同程度的可靠性,提供包括“尽力传输'和'端至端输送'。尽力而为的传输不会容忍任何 Flume 节点故障,而“终端到终端的传递”模式,保证传递在多个节点出现故障的情况。
-
Flume 承载源和接收之间的数据。这种数据收集可以被预定或是事件驱动。Flume有它自己的查询处理引擎,这使得在转化每批新数据移动之前它能够到预定接收器。
-
可能 Flume 包括HDFS和HBase。Flume 也可以用来输送事件数据,包括但不限于网络的业务数据,也可以是通过社交媒体网站和电子邮件消息所产生的数据。
自2012年7月Flume 发布了新版本 Flume NG(新一代),因为它和原来的版本有明显的不同,因为被称为 Flume OG (原代)。
在本教程中,我们将讨论 Pig & Hive
Pig简介
在Map Reduce框架,需要的程序将其转化为一系列 Map 和 Reduce阶段。 但是,这不是一种编程模型,它被数据分析所熟悉。因此,为了弥补这一差距,一个抽象概念叫 Pig 建立在 Hadoop 之上。
Pig是一种高级编程语言,分析大数据集非常有用。 Pig 是雅虎努力开发的结果
Pig 使人们能够更专注于分析大量数据集和花更少的时间来写map-reduce程序。
类似猪吃东西,Pig 编程语言的目的是可以在任何类型的数据工作。
Pig 由两部分组成:
-
Pig Latin,这是一种语言
-
运行环境,用于运行PigLatin程序
Pig Latin 程序由一系列操作或变换应用到输入数据,以产生输出。这些操作描述被翻译成可执行到数据流,由 Pig 环境执行。下面,这些转换的结果是一系列的 MapReduce 作业,程序员是不知道的。所以,在某种程度上,Pig 允许程序员关注数据,而不是执行过程。
Pig Latin 是一种相对硬挺的语言,它采用熟悉的关键字来处理数据,例如,Join, Group 和 Filter。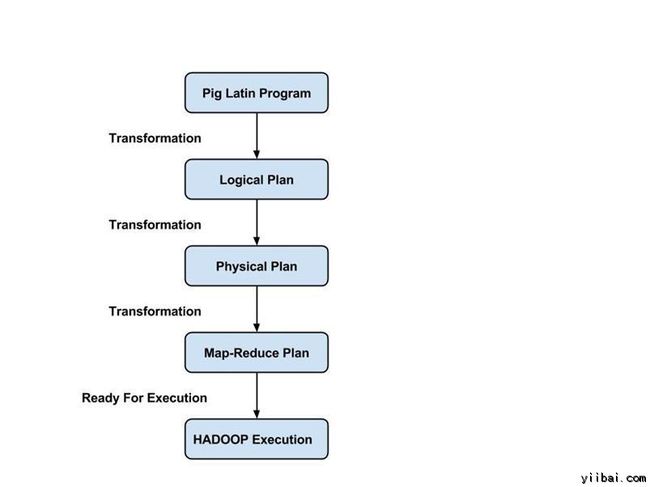
执行模式:
Pig 有两种执行模式:
-
本机模式:在此模式下,Pig 运行在单个JVM,并使用本地文件系统。这种模式只适合使用 Pig 小数据集合分析。
-
Map Reduce模式:在此模式下,写在 Pig Latin 的查询被翻译成MapReduce 作业,并 Hadoop 集群上运行(集群可能是伪或完全分布式的)。 MapReduce 模式完全分布式集群对大型数据集运行 Pig 很有用的。
HIVE 介绍
在某种程度上数据集收集的大小并在行业用于商业智能分析正在增长,它使传统的数据仓库解决方案更加昂贵。HADOOP与MapReduce框架,被用于大型数据集分析的替代解决方案。虽然,Hadoop 地庞大的数据集上工作证明是非常有用的,MapReduce框架是非常低级别并且它需要程序员编写自定义程序,这导致难以维护和重用。 Hive 就是为程序员设计的。
Hive 演变为基于Hadoop的Map-Reduce 框架之上的数据仓库解决方案。
Hive 提供了类似于SQL的声明性语言,叫作:HiveQL, 用于表达的查询。使用 Hive-SQL,用户能够非常容易地进行数据分析。
Hive 引擎编译这些查询到 map-reduce作业中并在 Hadoop 上执行。此外,自定义 map-reduce 脚本,也可以插入查询。Hive运行存储在表中,它由基本数据类型,如数组和映射集合的数据类型的数据。
配置单元带有一个命令行shell接口,可用于创建表并执行查询。
Hive 查询语言是类似于SQL,它支持子查询。通过Hive查询语言,可以使用 MapReduce 跨Hive 表连接。它有类似函数简单的SQL支持- CONCAT, SUBSTR, ROUND 等等, 聚合函数 - SUM, COUNT, MAX etc。它还支持GROUP BY和SORT BY子句。 另外,也可以在配置单元查询语言编写用户定义的功能。
MapReduce,Pig 和 Hive 的比较
| Sqoop |
Flume |
HDFS |
| Sqoop用于从结构化数据源,例如,RDBMS导入数据 |
Flume 用于移动批量流数据到HDFS |
HDFS使用 Hadoop 生态系统存储数据的分布式文件系统 |
| Sqoop具有连接器的体系结构。连接器知道如何连接到相应的数据源并获取数据 |
Flume 有一个基于代理的架构。这里写入代码(这被称为“代理”),这需要处理取出数据 |
HDFS具有分布式体系结构,数据被分布在多个数据节点 |
| HDFS 使用 Sqoop 将数据导出到目的地 |
通过零个或更多个通道将数据流给HDFS |
HDFS是用于将数据存储到最终目的地 |
| Sqoop数据负载不事件驱动 |
Flume 数据负载可通过事件驱动 |
HDFS存储通过任何方式提供给它的数据 |
| 为了从结构化数据源导入数据,人们必须只使用Sqoop,因为它的连接器知道如何与结构化数据源进行交互并从中获取数据 |
为了加载流数据,如微博产生的推文。或者登录Web服务器的文件,Flume 应都可以使用。Flume 代理是专门为获取流数据而建立的。 |
HDFS拥有自己的内置shell命令将数据存储。HDFS不能用于导入结构化或流数据 |
OOZIE 是什么鬼?
Apache Oozie是工作流调度用在Hadoop中。它是一个运行相关的作业工作流系统。这里,用户被允许创建向非循环图工作流程,其可以在并列 Hadoop 并顺序地运行。
它由两部分组成:
-
工作流引擎:一个工作流引擎的职责是存储和运行工作流程,由 Hadoop 作业组成:MapReduce, Pig, Hive.
-
协调器引擎:它运行基于预定义的时间表和数据的可用性工作流程作业。
Oozie可扩展性和可管理及时执行成千上万的工作流程(每个由几十个作业)的Hadoop集群。
Oozie 也非常灵活。人们可以很容易启动,停止,暂停和重新运行作业。Oozie 可以很容易地重新运行失败的工作流。可以很容易重做因宕机或故障错过或失败的作业。甚至有可能跳过一个特定故障节点。
Oozie 如何工作?
Oozie 运行作为集群服务,客户端提交的工作流定义:立即或以后处理。
Oozie 工作流由动作节点和控制流的节点组成。
一个操作节点代表一个工作流任务,例如,移动文件到HDFS,运行 MapReduce,Pig 或 Hive 作业,使用 Sqoop 导入数据或 运行Java 编写程序的 shell 脚本。
一个控制流节点通过允许像条件逻辑结构,不同的分支可以根据较早动作节点的结果,随后执行动作工作流程。
开始节点,终端节点和错误节点属于这一类节点。
开始节点, 指定的工作流程作业的开始。
结束节点, 作业的结束信号。
错误节点, 指定要打印错误和相应的错误信息的发生。
在执行工作流的结束, HTTP 回调用于通过 Oozie 更新客户端与工作流状态。入门或出口,从动作节点还可能会触发回调。
工作流程图示例
为什么要使用 Oozie ?
使用Oozie的主要目的是为了管理不同类型的作业在Hadoop系统中处理。
作业之间的依赖关系是由用户向无环图的形式指定。Oozie 的消费信息以及在工作流中指定负责其执行的顺序正确。这样,用户同时管理保存整个工作流程。此外 Oozie 有指定执行特定工作频率规定。
Oozie的特点
- Oozie 客户端 API 以及命令行界面可以用来启动,控制和监视Java应用程序作业
- 使用其Web服务的API可以从任何位置控制作业
- Oozie有规定执行这些计划定期来运行作业
-
Oozie 有规定作业完成后可发送电子邮件通知
from: http://www.yiibai.com/hadoop/