Python-OpenCV实战二(图像的表示和处理)
图像的表示
在OpenCV的C++代码中,表示图像有个专门的结构叫做cv::Mat,不过在Python-OpenCV中,因为已经有了numpy这种强大的基础工具,所以这个矩阵就用numpy的array表示。如果是多通道情况,最常见的就是红绿蓝(RGB)三通道,则第一个维度是高度,第二个维度是高度,第三个维度是通道,比如图a是一幅3×3图像在计算机中表示的例子:
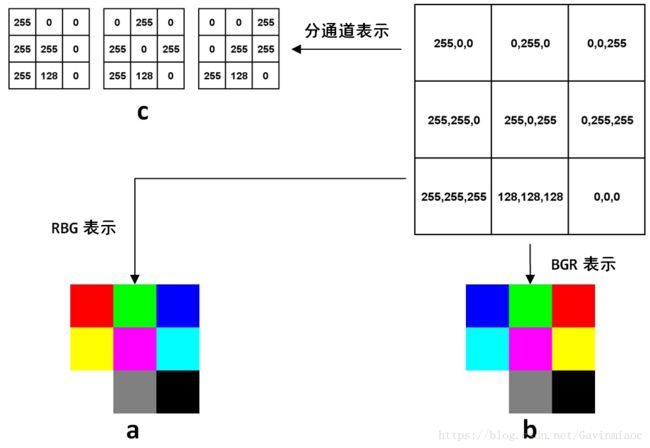
右上角的矩阵里每个元素都是一个3维数组,分别代表这个像素上的三个通道的值。最常见的RGB通道中,第一个元素就是红色(Red)的值,第二个元素是绿色(Green)的值,第三个元素是蓝色(Blue),最终得到的图像如a所示。RGB是最常见的情况,然而在OpenCV中,默认的图像的表示确实反过来的,也就是BGR,得到的图像是b。可以看到,前两行的颜色顺序都交换了,最后一行是三个通道等值的灰度图,所以没有影响。至于OpenCV为什么不是人民群众喜闻乐见的RGB,这是历史遗留问题,在OpenCV刚开始研发的年代,BGR是相机设备厂商的主流表示方法,虽然后来RGB成了主流和默认,但是这个底层的顺序却保留下来了,事实上Windows下的最常见格式之一bmp,底层字节的存储顺序还是BGR。OpenCV的这个特殊之处还是需要注意的,比如在Python中,图像都是用numpy的array表示,但是同样的array在OpenCV中的显示效果和matplotlib中的显示效果就会不一样。下面的简单代码就可以生成两种表示方式下,图中矩阵的对应的图像,生成图像后,放大看就能体会到区别:
import numpy as np
import cv2
import matplotlib.pyplot as plt
img = np.array([
[[255, 0, 0], [0, 255, 0], [0, 0, 255]],
[[255, 255, 0], [255, 0, 255], [0, 255, 255]],
[[255, 255, 255], [128, 128, 128], [0, 0, 0]],
], dtype=np.uint8)
# 用matplotlib存储
plt.imsave('img_pyplot.jpg',img)
# 用opencv存储
cv2.imwrite('img_cv2.jpg',img)不管是RGB还是BGR,都是高度×宽度×通道数,H×W×C的表达方式,而在深度学习中,因为要对不同通道应用卷积,所以用的是另一种方式:C×H×W,就是把每个通道都单独表达成一个二维矩阵,如图c所示。
基本图像处理
存取图像
读图像用cv2.imread(),可以按照不同模式读取,一般最常用到的是读取单通道灰度图,或者直接默认读取多通道。存图像用cv2.imwrite(),注意存的时候是没有单通道这一说的,根据保存文件名的后缀和当前的array维度,OpenCV自动判断存的通道,另外压缩格式还可以指定存储质量,来看代码例子:
import cv2
# 读取一张640x480分辨率的图像
color_img = cv2.imread('dog.jpg')
color_img.shape
(480, 640, 3)# 直接读取单通道
gray_img = cv2.imread('dog.jpg',cv2.IMREAD_GRAYSCALE)
gray_img.shape
(480, 640)# 把单通道图片保存后,再读取,仍然是3通道,
# 相当于把单通道值复制到3个通道保存
cv2.imwrite('test_grayscale.jpg',gray_img)
reload_grayscale = cv2.imread('test_grayscale.jpg')
print(reload_grayscale.shape) # (480, 640, 3)cv2.imwrite('test_imwrite.jpg',color_img,(cv2.IMWRITE_JPEG_QUALITY,80))# cv2.IMWRITE_PNG_COMPRESSION指定png质量,范围0到9,默认3,越高文件越小,画质越差
cv2.imwrite('test_imwrite.png', color_img, (cv2.IMWRITE_PNG_COMPRESSION, 5))缩放,裁剪和补边
缩放通过cv2.resize()实现,裁剪则是利用array自身的下标截取实现,此外OpenCV还可以给图像补边,这样能对一幅图像的形状和感兴趣区域实现各种操作。下面的例子中读取一幅400×600分辨率的图片,并执行一些基础的操作:
import cv2
img = cv2.imread('data/moon.jpg')
# img.shape # (576, 1024, 3)# 缩放成500x250的方形图像
img_500x250 = cv2.resize(img, (500, 250))cv2.imwrite('resized_500x250.jpg', img_500x250)
img_200x300 = cv2.resize(img, (0, 0), fx=0.5, fy=0.5,
interpolation=cv2.INTER_NEAREST) # (288, 512, 3)cv2.imwrite('resized_200x300.jpg', img_200x300)
# 在上张图片的基础上,上下各贴50像素的黑边,生成300x300的图像
img_300x300 = cv2.copyMakeBorder(img_200x300, 50, 50, 0, 0,
cv2.BORDER_CONSTANT,
value=(0, 0, 0))
print(img_300x300.shape) # (388, 512, 3)cv2.imwrite('bordered_300x300.jpg', img_300x300)
对照片中树的部分进行剪裁
patch_tree = img[371:660,335:575]cv2.imwrite('cropped_tree.jpg', patch_tree)
色调,明暗,直方图和Gamma曲线
除了区域,图像本身的属性操作也非常多,比如可以通过HSV空间对色调和明暗进行调节。HSV空间是由美国的图形学专家A. R. Smith提出的一种颜色空间,HSV分别是色调(Hue),饱和度(Saturation)和明度(Value)。在HSV空间中进行调节就避免了直接在RGB空间中调节是还需要考虑三个通道的相关性。OpenCV中H的取值是[0, 180),其他两个通道的取值都是[0, 256),下面例子接着上面例子代码,通过HSV空间对图像进行调整:
通过cv2.cvtColor把图像从BGR转换到HSV
img_hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
# H空间中,绿色比黄色的值高一点,所以给每个像素+15,黄色的树叶就会变绿
turn_green_hsv = img_hsv.copy()
turn_green_hsv[:,:,0] = (turn_green_hsv[:,:,0] + 15) % 180
turn_green_img = cv2.cvtColor(turn_green_hsv,cv2.COLOR_HSV2BGR)
cv2.imwrite('turn_green.jpg',turn_green_img)
# 减小饱和度会让图像损失鲜艳,变得更灰
colorless_hsv = img_hsv.copy()
colorless_hsv[:,:,1] = 0.5 * colorless_hsv[:,:,1]
colorless_img = cv2.cvtColor(colorless_hsv,cv2.COLOR_HSV2BGR)
cv2.imwrite('colorless.jpg',colorless_img)
# 减小明度为原来一半
darker_hsv = img_hsv.copy()
darker_hsv[:,:,2] = 0.5 * darker_hsv[:,:,2]
darker_img = cv2.cvtColor(darker_hsv,cv2.COLOR_HSV2BGR)
cv2.imwrite('darker.jpg',darker_img)
无论是HSV还是RGB,我们都较难一眼就对像素中值的分布有细致的了解,这时候就需要直方图。如果直方图中的成分过于靠近0或者255,可能就出现了暗部细节不足或者亮部细节丢失的情况。比如图6-2中,背景里的暗部细节是非常弱的。这个时候,一个常用方法是考虑用Gamma变换来提升暗部细节。Gamma变换是矫正相机直接成像和人眼感受图像差别的一种常用手段,简单来说就是通过非线性变换让图像从对曝光强度的线性响应变得更接近人眼感受到的响应。具体的定义和实现,还是接着上面代码中读取的图片,执行计算直方图和Gamma变换的代码如下:
import numpy as np
# 分通道计算每个通道的直方图
hist_b = cv2.calcHist([img],[0],None,[256],[0,256])
hist_g = cv2.calcHist([img],[1],None,[256],[0,256])
hist_r = cv2.calcHist([img],[2],None,[256],[0,256])
# 定义Gamma矫正的函数
def gamma_trans(img,gamma):
# 具体做法是先归一化到1,然后gamma作为指数值求出新的像素值再还原
gamma_table = [np.power(x/255.0,gamma)*255.0 for x in range(256)]
gamma_table = np.round(np.array(gamma_table)).astype(np.uint8)
# 实现这个映射用的是OpenCV的查表函数
return cv2.LUT(img,gamma_table)
# 执行Gamma矫正,小于1的值让暗部细节大量提升,同时亮部细节少量提升
img_corrected = gamma_trans(img,0.5)
cv2.imwrite('gamma_corrected.jpg',img_corrected)
图像的仿射变换
图像的仿射变换涉及到图像的形状位置角度的变化,是深度学习预处理中常到的功能, 在此简单回顾一下。仿射变换具体到图像中的应用,主要是对图像的缩放,旋转,剪切,翻转和平移的组合
在OpenCV中,仿射变换的矩阵是一个2×3的矩阵,其中左边的2×2子矩阵是线性变换矩阵,右边的2×1的两项是平移项:


import cv2
import numpy as np
img = cv2.imread('data/dog.jpg')
# 沿着横纵轴放大1.6倍,然后平移(-150,-240),最后沿原图大小截取,
# 等效于裁剪并放大
M_crop_dog = np.array([
[1.6, 0, -150],
[0, 1.6, -240]
], dtype=np.float32)
img_dog = cv2.warpAffine(img,M_crop_dog,(640,480))
cv2.imwrite('data/lanka_dog.jpg',img_dog)
# x轴的剪切变换,角度15°
theta = 15 * np.pi / 180
M_shear = np.array([
[1, np.tan(theta), 0],
[0, 1, 0]
], dtype=np.float32)
img_sheared = cv2.warpAffine(img, M_shear, (640, 480))
cv2.imwrite('data/lanka_safari_sheared.jpg', img_sheared)
# 顺时针旋转,角度15°
M_rotate = np.array([
[np.cos(theta), -np.sin(theta), 0],
[np.sin(theta), np.cos(theta), 0]
], dtype=np.float32)
img_rotated = cv2.warpAffine(img, M_rotate, (640, 480))
cv2.imwrite('data/lanka_safari_rotated.jpg', img_rotated)
# 某种变换,具体旋转+缩放+旋转组合可以通过SVD分解理解
M = np.array([
[1, 1.5, -400],
[0.5, 2, -100]
], dtype=np.float32)
img_transformed = cv2.warpAffine(img, M, (640, 480))
cv2.imwrite('data/lanka_safari_transformed.jpg', img_transformed)