Deep&Cross Network模型与TensorFlow实现
0、DCN网络模型结构:
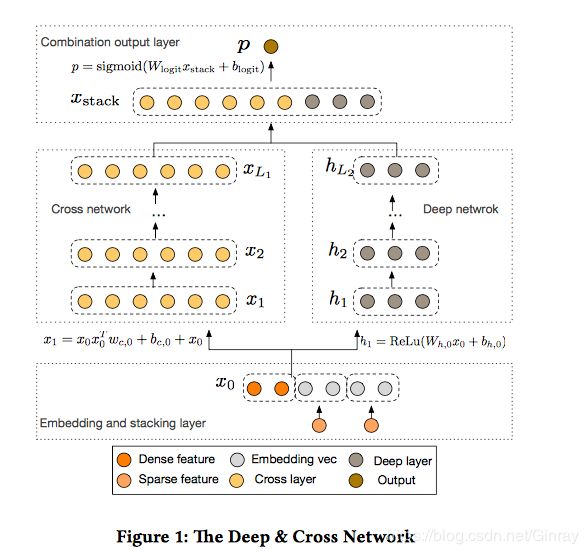
特征分为类别型与数值型,类别型特征经过 embedding 之后与数值型特征直接拼接作为模型的输入。所有的特征分别经过 cross 和 deep 网络,经过拼接后输出。
1、embedding层
这部分和DeepFM所用到的方法一致,都采用了NLP中常用的word2vec思想。不同的是DCN网络中只需要对离散特征做embedding,连续特征不需要进行embedding。而DeepFM是需要对所有的特征都进行embedding。
2、交叉网络
交叉网络由交叉层组成,每个层具有以下公式:
一个交叉层的可视化如图所示:
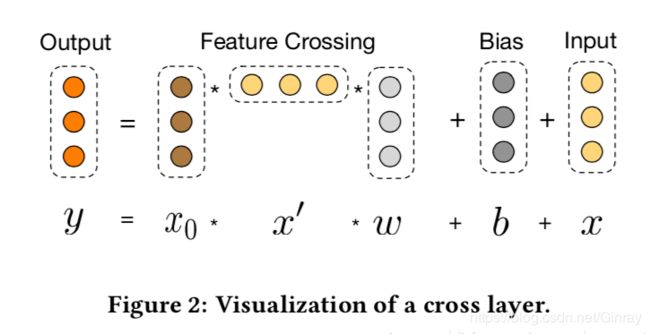
x₀ 为输入的特征及第一层的输入,x 为 第 L 层的输入,我们可以看到它的基本思路还是用矩阵乘法来实现特征的组合。并且该模型还用了残差的思想,解决网络性能退化的问题。
2、Deep 层
deep层和DeepFM中一样,是一个全连接的前馈神经网络。
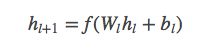
3、总结与对比
可以看到 wide & deep 的思路中,deep 部分的做法和 deepFM 是大相径庭的,关键的 wide 部分其实是离线的特征工程,根据业务场景提前完成了特征交叉等处理,该模型可以看作是 DNN 与离线特征模型的融合结果。
而从 DCN 的网络中我们可以发现,deep 部分网络除了使用离散嵌入特征外,还拼接了数值型特征;cross 部分网络直接完成了特征组合,对比 FM 层它可以学到更高阶的组合特征,对比 wide 网络它不需要做线下的特征工程[1]。
4、代码实现
完整代码以及测试用例见:
https://github.com/Ginray/DeepRecommendation/blob/master/Deep_Cross_Network/model.py
模型主要部分:
def build_model(self):
self.weights['feature_weight'] = tf.Variable(
tf.random_normal([FLAGS.feature_sizes, FLAGS.embedding_size], 0.0, 0.01),
name='feature_weight')
self.embedding_index = tf.nn.embedding_lookup(self.weights['feature_weight'],
self.X_sparse_index) # Batch*F*K
sparse_value = tf.reshape(self.X_sparse, shape=[-1, FLAGS.field_size, 1])
self.embedding_part = tf.multiply(self.embedding_index, sparse_value)
self.input = tf.concat(
[self.X_dense, tf.reshape(self.embedding_part, shape=[-1, FLAGS.field_size * FLAGS.embedding_size])],
axis=1)
self.total_size = FLAGS.field_size * FLAGS.embedding_size + FLAGS.numeric_feature_size
self.input = tf.reshape(self.input, [-1, self.total_size, 1])
# cross part
for i in range(FLAGS.cross_layer_num):
self.weights['cross_layer_weight_{0}'.format(i)] = tf.Variable(
tf.random_normal([self.total_size, 1], 0.0, 0.01), tf.float32)
self.weights['cross_layer_bias_{0}'.format(i)] = tf.Variable(
tf.random_normal([self.total_size, 1], 0.0, 0.01), tf.float32)
x_now = self.input
for i in range(FLAGS.cross_layer_num):
x_now = tf.add(tf.add(tf.tensordot(tf.matmul(self.input, x_now, transpose_b=True),
self.weights['cross_layer_weight_{0}'.format(i)], axes
=1), self.weights['cross_layer_bias_{0}'.format(i)]), x_now)
self.cross_network_out = tf.reshape(x_now, (-1, self.total_size))
print(self.cross_network_out)
# deep part
deep_layer_num = len(FLAGS.deep_layers)
for i in range(deep_layer_num):
if (i == 0):
self.weights['deep_layer_weight_{0}'.format(i)] = tf.Variable(
tf.random_normal([self.total_size, FLAGS.deep_layers[0]], 0.0, 0.01), tf.float32)
self.weights['deep_layer_bias_{0}'.format(i)] = tf.Variable(
tf.random_normal([1, FLAGS.deep_layers[0]], 0.0, 0.01), tf.float32)
else:
self.weights['deep_layer_weight_{0}'.format(i)] = tf.Variable(
tf.random_normal([FLAGS.deep_layers[i - 1], FLAGS.deep_layers[i]], 0.0, 0.01), tf.float32)
self.weights['deep_layer_bias_{0}'.format(i)] = tf.Variable(
tf.random_normal([1, FLAGS.deep_layers[i]], 0.0, 0.01), tf.float32)
self.input = tf.reshape(self.input, [-1, self.total_size])
deep_out = tf.nn.dropout(self.input, keep_prob=FLAGS.dropout_deep[0])
for i in range(deep_layer_num):
deep_out = tf.add(tf.matmul(deep_out, self.weights['deep_layer_weight_{0}'.format(i)]),
self.weights['deep_layer_bias_{0}'.format(i)])
if FLAGS.deep_layers_activation == 'relu':
deep_out = tf.nn.relu(deep_out)
else:
deep_out = tf.nn.sigmoid(deep_out)
deep_out = tf.nn.dropout(deep_out, keep_prob=FLAGS.dropout_deep[i + 1])
self.deep_out = deep_out
print(self.deep_out)
self.weights['concat_weight'] = tf.Variable(
tf.random_normal([FLAGS.deep_layers[-1] + self.total_size, 1], 0.0, 0.01), dtype=tf.float32)
self.weights['concat_bias'] = tf.Variable(tf.random_normal([1, 1]), dtype=tf.float32)
self.out = tf.concat([self.cross_network_out, self.deep_out], axis=1)
self.out = tf.add(tf.matmul(self.out, self.weights['concat_weight']), self.weights['concat_bias'])
print(self.out)
# loss
if FLAGS.loss == 'logloss':
self.out = tf.nn.sigmoid(self.out)
self.loss = tf.losses.log_loss(self.label, self.out)
correct_prediction = tf.equal(tf.to_int32(tf.round(self.out)), self.label)
self.acc = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('loss', self.loss)
tf.summary.scalar('acc', self.acc)
elif FLAGS.loss == 'mse':
self.loss = tf.losses.mean_squared_error(labels=self.label, predictions=self.out)
self.train_op = tf.train.AdamOptimizer(FLAGS.learning_rate, beta1=0.9, beta2=0.999, epsilon=1e-8).minimize(
self.loss)
def train(self, sess, X_sparse, X_sparse_index, X_dense, label, index):
_loss, _step, _acc, _result = sess.run([self.loss, self.train_op, self.acc, merged], feed_dict={
self.X_sparse: X_sparse,
self.X_sparse_index: X_sparse_index,
self.X_dense: X_dense,
self.label: label
})
writer.add_summary(_result, index) # 将日志数据写入文件
return _loss, _step, _acc
def predict(self, sess, X_sparse, X_sparse_index, X_dense):
result = sess.run([self.out], feed_dict={
self.X_sparse: X_sparse,
self.X_sparse_index: X_sparse_index,
self.X_dense: X_dense,
})
return result
def eval(self, sess, X_sparse, X_sparse_index, X_dense, y, index):
val_out = self.predict(sess, X_sparse, X_sparse_index, X_dense)
correct_prediction = np.equal(np.int32(np.round(val_out)), y)
val_acc = np.mean(np.int32(correct_prediction))
print('the times of training is %d ,and val acc = %s' % (index, val_acc))
return val_acc
参考链接:
[1]https://www.jiqizhixin.com/articles/2018-10-17-18
[2]https://www.jianshu.com/p/77719fc252fa
[3]Deep & Cross Network for Ad Click Predictions