LR和GBDT模型训练
【待补充】
数据集和训练模型的意义含义:
数据集给出发博者 和 阅读者之间的各种关系,历史点击、互动、曝光等数据,去预测 给阅读者 曝光一个 发博者的内容,这个阅读者是否回去互动。
一、LR模型训练
1、特征分析
dataprocessing.ipynb
分析每个特征和标签的关系
【放个链接,在别的博客里写】
2、分析每个特征的基本特点
步骤1是看相关性,是为了筛选特征,删除不必要特征
本步分析特征基本特点是在选完特征基础上,为数据处理做准备
【放个链接?】
3、根据特征的特点,以及模型的输入要求 对数据集进行整理
【只写有代表的特征】
(1)删除某列
(2)删除有缺失值的行
(3)链接新列
# 2数据处理 ======= 一个一个看吧,周三来了,新建一个数据处理,快速把每一个特征都看下,然后直接在这边使用处理方法,整理数据
#2.1 删除 m_sourceid列
data.drop(['m_sourceid'], axis=1, inplace=True)
【TODO】inplace=True 表明删除结果作用在data上
# 2.2 click 0、1值不做处理
# 2.3 m_chour 取值0-23,缺失10个删除行
data.dropna(subset=['m_chour'],inplace=True) # 删除m_chour列为缺失值的 整行,并更新数据
#data.info()
dummies_m_chour = pd.get_dummies(data['m_chour'], prefix = 'm_chour') #24维
# 把m_chour列删除,并contact dummies_m_chour
data.drop(['m_chour'], axis=1, inplace=True)
data = pd.concat([data, dummies_m_chour], axis=1)
# 2.5 - 2.15
#m_is_business 0、1取值 缺失10个 删除
data.dropna(subset=['m_is_business'],inplace=True)
data.dropna(subset=['m_is_long_blog'],inplace=True)
data.dropna(subset=['m_is_original'],inplace=True)
......
【典型】
# 2.16 m_feed_expo_num_hour 0--320w左右,取值分散,建议scaler0-1 46个缺失值,删除
data.dropna(subset=['m_feed_expo_num_hour'],inplace=True)
LR的输入只能是0 或 1 因此,不要scaler,而是要分组,然后get_dummies
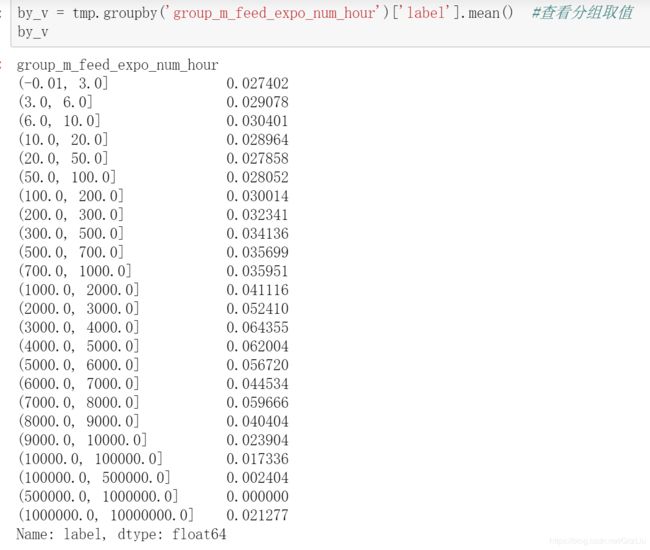
由于取值范围较大,根据画图表明该特征的分布情况,取值分散,因此分组,并get_dummies,分组是(1)取值范围,最大值为320w,因此组右边界为1千万 (2)根据value_counts; (3)分完组后看groupby,看看分组是否合理
tmp=data
bins = [-0.01, 3, 6, 10, 20, 50, \
100, 200, 300, 500, 700, \
1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, \
10000, 100000, 500000, 1000000, 10000000]
tmp['group_m_feed_expo_num_hour'] = pd.cut(tmp['m_feed_expo_num_hour'], bins)
tmp['group_m_feed_expo_num_hour'].head(10)
#查看分组取值:因为label 有 0、1两个取值, 因此 .mean() 方法是 一个分组中,label的平均取值,平均值越接近1,说明该分组中label为1的数据越多,这可以看出分组是否合理。
by_v = tmp.groupby('group_m_feed_expo_num_hour')['label'].mean()
by_v
data=tmp
dumies_m_feed_expo_num_hour = pd.get_dummies(data['group_m_feed_expo_num_hour'], prefix = 'group_m_feed_expo_num_hour') #n维度
# 把m_feed_expo_num_hour 和 group_m_feed_expo_num_hour列删除,并contact dumies_m_feed_expo_num_hour
data.drop(['m_feed_expo_num_hour', 'group_m_feed_expo_num_hour'], axis=1, inplace=True)
data = pd.concat([data, dumies_m_feed_expo_num_hour], axis=1)
data.head()
这里强调几点
(1)处理第n个特征开始的时候,一定要先 tmp=data下,否则一旦处理出错,之前的所有特征,(1…n-1个特征)的处理基本作废,需要重新读取数据集,或者从数据集读取之后保存的某一个变量开始,重新做前面(1…n-1个特征)的特征处理。
(2)因为该特征的取值在0-320w,因此应该取log分组。关于log分组:
对于特征16、 取值0-320w,有300w数据,但有120w+取值都为0,因此均匀分(qcut)筒最多只能分2个桶,否则报错,因此用自定义bins(cut会好些);
bins从-0.01开始,是因为bins左开右闭,需要把最左边的0包括进来。
不一定非要每个值取log,直接按照“log”划分,这个是说
比如DataFrame 某一列取值 0,2,5,113, 488, 1009,1899,9999
直接0 -10
10-100
100-1000
1000-10000
这样给他分组
其实就相当于对DataFrame 这一列取log,然后 划分到bins =[0, 1, 2, 3, 4] 这几个桶,这是等价的
如果想bins =[0, 0.5,1, 2, 3, 4]
可以 0-3, 3-10,10-100 … 因为 log以10为底3 取值约为0.47
这样的好处是不用对DataFrame 这一列取log,因为for循环计算太慢了。
下面代码是我最开始,想使用对该列特征先取log,再分组的代码,for的计算确实太慢,
i=0
for index, row in data.iterrows():
if data.at[index, 'm_feed_expo_num_hour'] == 0:
continue
data.at[index, 'm_feed_expo_num_hour'] = math.log(data.at[index, 'm_feed_expo_num_hour'], 10)
i=i+1
if i % 500000 ==0:
print i
data.loc[1,'m_feed_expo_num_hour']
tmp=data
#tmp['m_feed_expo_num_hour'] = pd.qcut(tmp['m_feed_expo_num_hour'], 3) # 去取值为0的有12w+
#print (tmp[['m_feed_expo_num_hour', 'label']].groupby(['m_feed_expo_num_hour'], as_index=False).mean().sort_values(by='m_feed_expo_num_hour', ascending=True))
#bins = [-0.01, 0.5, 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5, 5.5, 6, 6.5, 7]
# bins = [-0.01, 0.3, 0.4, 0.6, 0.7, 0.8, 0.9, \
# 1, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, \
# 2, 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9, \
# 3, 3.1, 3.2, 3.3, 3.4, 3.5, 3.6, 3.7, 3.8, 3.9, \
# 4, 4.5, 5, 5.5, 6, 6.5, 7]
可以看到,上面这段代码的处理,效果和之前的一样,但由于for的原因(300w数据,循环300w次),处理速度非常慢,因此强烈不建议这么干了。这里贴出来主要是为了记录下访问DataFrame 的方式:for index, row in data.iterrows()
该特征缺失值补0
#2.22 m_u_vtype:取值0、1、2、3;其中0、1取值明显较多,2、3取值只有个位数,有1400个缺失值 #问下这个字段的含义,看看是否拿众数添上?补0
#缺失值补0
tmp=data
print(len(tmp.m_u_vtype[tmp.m_u_vtype.isnull()].values)) #缺失值行数
tmp.loc[(tmp.m_u_vtype.isnull(), 'm_u_vtype')] = 0
print(len(tmp.m_u_vtype[tmp.m_u_vtype.isnull()].values)) #缺失值行数

一个完整的处理
#24、m_u_fans_num:取值较分散:0到千万,1383个缺失值 伪log分段 属于哪个区间,然后区间onehot
#缺失值补0
tmp=data
print(len(tmp.m_u_fans_num[tmp.m_u_fans_num.isnull()].values)) #缺失值行数
tmp.loc[(tmp.m_u_fans_num.isnull(), 'm_u_fans_num')] = 0
print(len(tmp.m_u_fans_num[tmp.m_u_fans_num.isnull()].values)) #缺失值行数
bins=[-0.01, 1, 10, 100, 1000, 3000, 5000, 7000, 10000, 12500, 15000, 20000, 25000, \
30000, 100000, 500000, 1000000, \
1500000, 2000000, 3000000, 4000000, 5000000, 6000000, 7000000, 8000000, 9000000,\
10000000, 20000000, 30000000, 40000000, 50000000, 100000000, 200000000]
tmp['group_m_u_fans_num'] = pd.cut(tmp['m_u_fans_num'], bins)
tmp['group_m_u_fans_num'].head()
by_v = tmp.groupby('group_m_u_fans_num')['label'].mean() #查看分组取值
by_v
data=tmp
dummies_m_u_fans_num = pd.get_dummies(data['group_m_u_fans_num'], prefix='group_m_u_fans_num')
data.drop(['m_u_fans_num', 'group_m_u_fans_num'], axis=1, inplace=True)
data=pd.concat([data, dummies_m_u_fans_num], axis=1)
data.head()
手机品牌,该特征确实较多,直接将缺失值作为一类
#34 mobile_brand: get_dummies; 74905个缺失值,作为未知类
tmp=data
print(len(tmp.mobile_brand[tmp.mobile_brand.isnull()].values)) #缺失值行数
tmp.loc[(tmp.mobile_brand.isnull(), 'mobile_brand')] = "unknowphone"
print(len(tmp.mobile_brand[tmp.mobile_brand.isnull()].values)) #缺失值行数
5、保存处理完成的数据
这里保存下处理完的数据,让另起一个文件,读取此数据,进行训练
#保存数据
data.to_csv('./process_data_model1.csv') #看看这个是否保存了 列名字
# 这里回头加上 index=False,去掉index,否则读的时候,第0例读出是index
#如果保存的时候没有加index=False, 则读的时候要加index_col=0 去掉index
6、准备训练
(1)读取数据
tmp_data = pd.read_csv('./process_data_model1.csv', index_col=0)
tmp_data.head()
data=tmp_data
print data.shape
data.head()
由于300w数据,在训练时,发现服务器内存不够,因此只抽取其中的200w进行训练
#随机抽样
#获取随机值
r=np.random.randint(0,2999944,2000000)
#对行进行切片
data=data.loc[r,:]
print data.shape
看一下数据集标签的取值情况
data.label.value_counts()

发现200w数据,标签为1的数据只有5w,占比2.5%,样本极度的不均衡,这也意味着我们训练完的模型,不能看准确率这个指标,因为模型将验证集都预测为 0,正确都有97.5%的保证,无意义,应该看其他指标(roc、auc等)
删除缺失值
按理说应该没有缺失值的,在数据处理时都处理完了。但是模型训练的时候总是崩掉,看了下错误,显示有缺失值,我想可能是数据读取的过程中,产生了错误。看来下,还好,只有一个缺失值,删掉就行
data[data.isnull().values==True].drop_duplicates().head()
data.dropna(subset=['label'],inplace=True)
#data.dropna(inplace=True)
print data.shape
np.isnan(data).any() #都false 表明没有缺失值
(2)划分训练集和验证集
#划分训练集验证集
# 训练数据:cv数据 = 0.95:0.05的比例
from sklearn import cross_validation
#划分
split_train, split_cv = cross_validation.train_test_split(data, test_size=0.05, random_state=0)
# 训练集
train_df = split_train
print (train_df.shape) # 大小
# print (train_df.columns.tolist()) # 列名
# print train_df.head()
(3)训练LR
# LR :maybe skip this step to load lr.model
from sklearn.linear_model import LogisticRegression
# 训练
clf = LogisticRegression(penalty='l2', # 惩罚项,可选l1,l2,对参数约束,减少过拟合风险
dual=False, # 对偶方法(原始问题和对偶问题),用于求解线性多核(liblinear)的L2的惩罚项上。样本数大于特征数时设置False
tol=0.0001, # 迭代停止的条件,小于等于这个值停止迭代,损失迭代到的最小值。
C=1.0, # 正则化系数λ的倒数,越小表示越强的正则化。
fit_intercept=True, # 是否存在截距值,即b
intercept_scaling=1, #
class_weight='balanced', # 类别的权重,样本类别不平衡时使用,设置balanced会自动调整权重。为了平横样本类别比例,类别样本多的,权重低,类别样本少的,权重高。
random_state=None, # 随机种子
solver='sag', # 优化算法的参数,包括newton-cg,lbfgs,liblinear,sag,saga,对损失的优化的方法
max_iter=200, # 最大迭代次数,
multi_class='ovr',# 多分类方式,有‘ovr','mvm'
verbose=1, # 输出日志,设置为1,会输出训练过程的一些结果
warm_start=False, # 热启动参数,如果设置为True,则下一次训练是以追加树的形式进行(重新使用上一次的调用作为初始化)
n_jobs=1 # 并行数,设置为1,用1个cpu运行,设置-1,用你电脑的所有cpu运行程序
)
#sag
clf.fit(train_df.as_matrix()[:,1:], train_df.as_matrix()[:,0])
# TODO 训练的模型 和 处理完的数据怎么保存下来(带name的保存)
保存模型
from sklearn.externals import joblib
#保存Model
joblib.dump(clf, './lr.model')
加载模型,进行后续操作
clf = joblib.load('./lr.model')
w = lr.coef_
b = lr.intercept_
print w.shape
print b.shape

包括:
处理缺失值:dropna删除,补0,如果是type,就补type类数量最大的type
get_dummies
log分组
bins(cut 或者 qcut)
保存训练好的数据集
(一些技巧,比如使用notbook 每个特征处理前 tmp=data, 然后再 data=tmp)
4、训练模型,保存模型
5、模型评估(准确率、精确率、召回率、ROC曲线、AUC)
6、特征重要性分析
7、特征覆盖率分析
8、结合特征覆盖率的特征重要性分析
二、GBDT训练
和lr类似
网格搜索