十大机器学习算法入门
近年来,机器学习与人工智能已广泛应用于学术与工程,比如数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用。
对于一个初学者来讲,周志华教授的西瓜书是一个很好的选择,以及相关机器学习视频课程是必不可少的,在这里我先分享基础学习视频 机器学习课程(20集),网上有很多公开课程,大家可以自行查找。接下来,我将和大家分享我所学到的机器学习常用算法。
机器学习算法可归为三类:有监督学习、无监督学习和强化学习。有监督学习指的是需要标识数据(有训练样本,带有属性标签,也可以理解成样本有输入有输出;用于training,即有正例和负例);无监督学习不需要标识数据(事先不知道样本的类别,通过某种办法,把相似的样本放在一起归位一类);增强学习介于两者之间(有部分标识数据)。所有的回归算法和分类算法都属于有监督学习。回归(Regression)和分类(Classification)的算法区别在于输出变量的类型,定量输出称为回归,或者说是连续变量预测;定性输出称为分类,或者说是离散变量预测。
有监督学习算法(决策树、朴素贝叶斯分类器、最小二乘法、逻辑回归、SVM、集成学习(常见方法:Adaboost模型和Random Forest模型)),无监督学习算法(聚类(K-means聚类、KNN)、主成分析(PCA)、SVD矩阵分解、独立成分分析(ICA))。在这里,介绍的算法如下:1、K-means算法;2、KNN算法;3、决策树;4、Random Forest;5、朴素贝叶斯;6、最小二乘法;7、SVM;8、逻辑回归;9、Adaboost算法;10、神经网络。
算法一:K-means聚类(点击详细说明)
K-means (K均值)是基于数据划分的无监督聚类算法,是数据挖掘领域的十大算法之一。即样本集预先不知所属类别或标签,需要根据样本之间的距离或相似程度自动进行分类。聚类算法可以分为基于划分方法、基于联通性的方法、基于密度的方法、基于概率分布模型的方法等,K-means属于基于划分的聚类方法。
(1)给出一组原始数据,想要将一组数据分为N类;
(2)先初始化,随机选择5中心点作为各类的初始值;
(3)剩下的数据里,每个都与5个初始值计算距离,然后归类到离它最近的初始值所在类别。
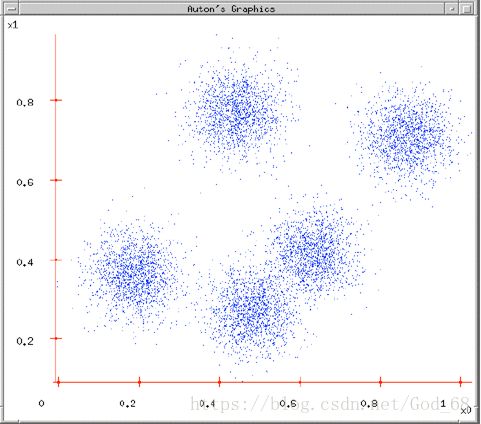
图1. 原始数据
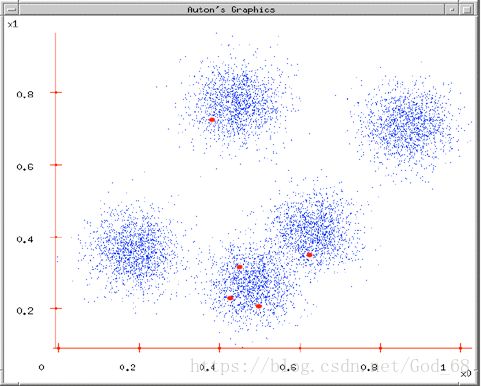
图2. 随机的选择K(K = 5)个初始中心点
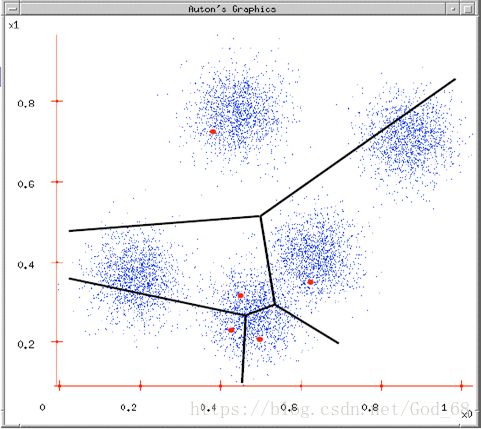
图3. 将各个样本点归到距离自己最近的初始中心点的那一类
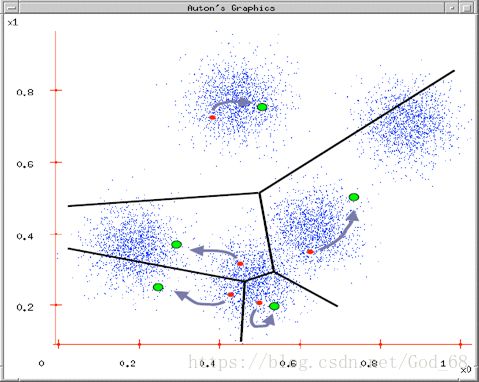
图4. 重新计算新的中心点直到误差最小
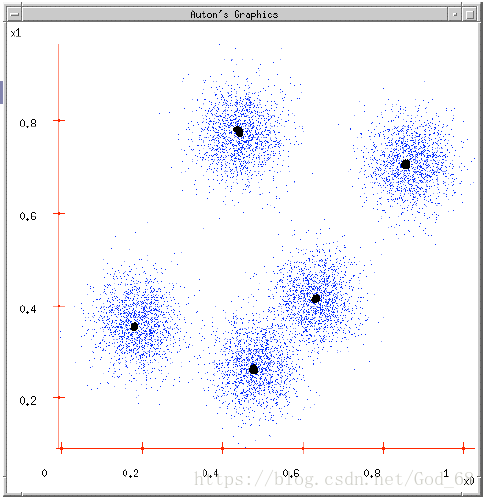
图5. 最终的聚类结果
算法二:KNN算法
KNN学习(K-Nearest Neighbor algorithm,K最邻近方法)是一种统计分类器,属于惰性学习,对包容型数据的特征变量筛选尤其有效。最早相关论文为美国Stanford University的Cover TM和Hart PE发表于1967年的Nearest neighbor pattern classfication (IEEE Transactions on Information Theory),被引用次数超5000次。
KNN的基本思想:输入没有标签即未经分类的新数据,首先提取新数据的特征并与测试集中的每一个数据特征进行比较;然后从样本中提取![]() 个最邻近(最相似)数据特征的分类标签,统计这
个最邻近(最相似)数据特征的分类标签,统计这![]() 个最邻近数据中出现次数最多的分类,将其作为新数据的类别。下图是使用
个最邻近数据中出现次数最多的分类,将其作为新数据的类别。下图是使用![]() 最邻近思想进行分类的一个例子:
最邻近思想进行分类的一个例子:
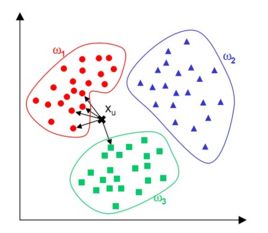
在上图中有红色、蓝色和绿色三类样本。对于待分类样本即图中的黑色“×”,我们寻找离该样本最近的一部分训练样本,在图中是以这个矩形样本为圆心的某一圆范围内的所有样本。然后统计这些样本所属的类别,在这里红色点有4个,绿色的方块有1个,因此把这个样本判定为红色这一类。上面的例子是分类的情况,我们可以推广到多类,k近邻算法天然支持多类分类问题。
算法三:决策树
决策树学习(Decision Tree)是一种有监督机器学习方法。(1)决策树是一种树,一种依托于策略抉择而建立起来的树。(2)决策树是一种代表对象属性与对象值之间映射关系的预测模型。树中每个节点用于表示某个对象,每个分叉路径用于代表某个可能的属性值,从根节点到某叶节点所经历的路径所表示的对象值则对应该叶节点。(3)从数据产生决策树的机器学习方法叫做决策树学习,是一种依托于分类、训练的预测树,可以根据已知预测、归类暂时未知的情况。
根据一些 feature 进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。
例子:可以将找对象的过程用来类比决策树分类思想,如某个“剩女”的母亲要给女儿介绍对象,经典对话如下:
女儿:今年多大岁数? 母亲:34。
女儿:长相如何? 母亲:挺好看的。
女儿:收入怎样? 母亲:中上水平。
女儿:是否公务员? 母亲:是的,在政府部门上班。
女儿:嗯,可以见见。
下图是使用决策树思想进行决策“见与不见”的一个例子:
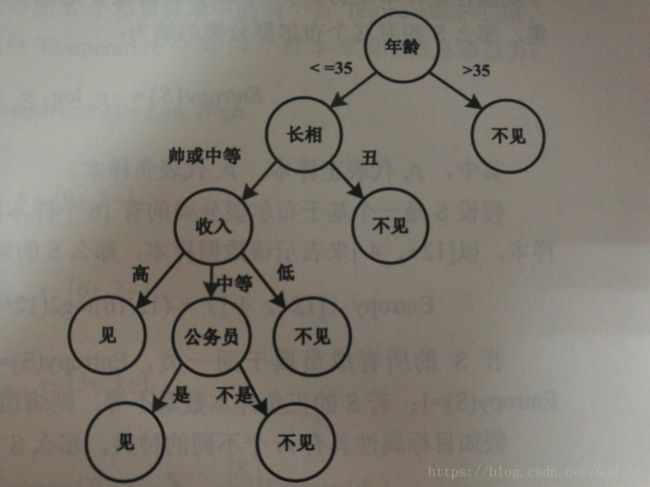
上图是基于决策树找对象,该女孩的决策过程就是典型的分类决策树,通过年龄、长相、收入和是否是公务员将男人分为两类:见和不见。该女孩对男人的要求是:35岁以下、长相中等以上、收入中等以上的公务员。
算法四:Random Forest
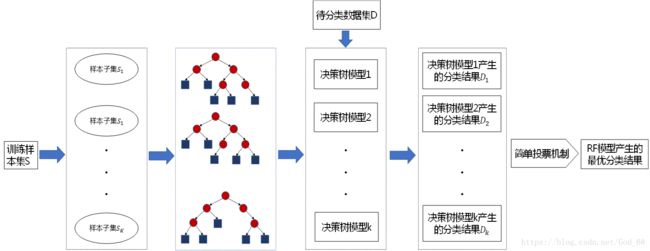
随机森林(Random Forest)是一种采用决策树作为基预测器的集成学习方法,2001年由Breiman提出,结合Bagging和随机子空间理论,集成众多决策树进行预测,通过各个决策树的预测值进行平均或投票,得到最终预测结果。
 随机森林的优点:
随机森林的优点:
- 具有极高的准确率
- 随机性的引入,使得随机森林不容易过拟合
- 随机性的引入,使得随机森林有很好的抗噪声能力
- 能处理很高维度的数据,并且不用做特征选择
- 既能处理离散型数据,也能处理连续型数据,数据集无需规范化
- 训练速度快,可以得到变量重要性排序
- 容易实现并行化
随机森林的缺点:
- 当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大
- 随机森林模型还有许多不好解释的地方,有点算个黑盒模型
算法五:朴素贝叶斯
朴素贝叶斯分类器基于贝叶斯理论及其假设(即特征之间是独立的,是不相互影响的)
![]()
P(A|B) 是后验概率, P(B|A) 是似然,P(A)为先验概率,P(B) 为我们要预测的值。
具体应用有:垃圾邮件检测、文章分类、情感分类、人脸识别等。
算法六:最小二乘法
线性回归必然听过,最小均方就是用来求线性回归的。如下图所示,平面内会有一系列点,然后我们求取一条线,使得这条线尽可能拟合这些点分布,这就是线性回归。这条线有多种找法,最小二乘法就是其中一种。最小二乘法其原理如下,找到一条线使得平面内的所有点到这条线的欧式距离和最小。这条线就是我们要求取的线。
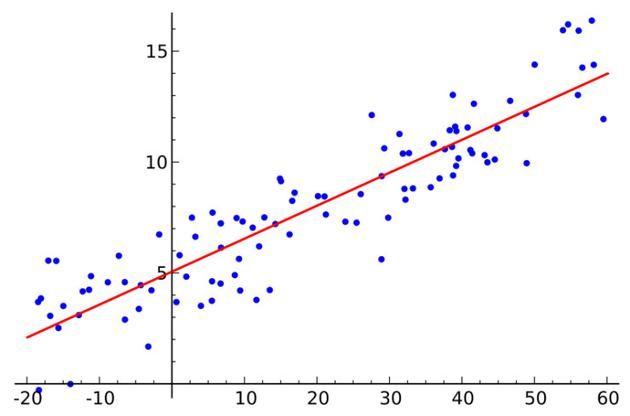
线性指的是用一条线对数据进行拟合,距离代表的是数据误差,最小二乘法可以看做是误差最小化。
算法七:SVM
SVM(Support Vector Machine,支持向量机)是一种有监督的统计学习方法,能够最小化经验误差和最大化几何边缘,被称为最大间隔分类器,可用于分类与回归分析。也就是说,平面内如果存在线性可分的两类点,SVM可以找到一条最优的直线将这些点分开。
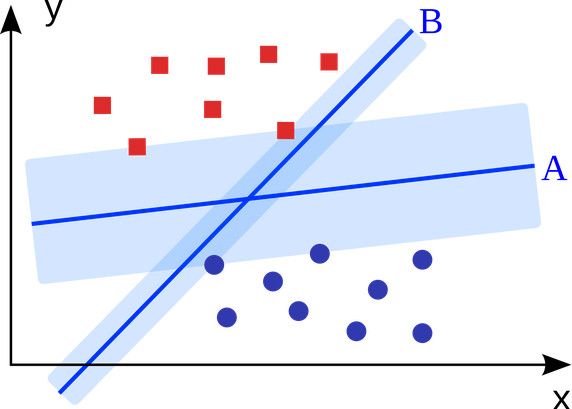
具体应用有:广告展示、性别检测、大规模图像识别等。
算法八:逻辑回归
逻辑回归模型是一个二分类模型,它选取不同的特征与权重来对样本进行概率分类,用一各log函数计算样本属于某一类的概率。即一个样本会有一定的概率属于一个类,会有一定的概率属于另一类,概率大的类即为样本所属类。
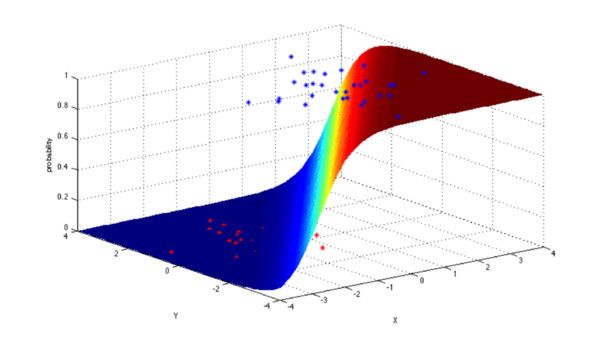
具体应用有:信用评级、营销活动成功概率、产品销售预测、某天是否将会地震发生。
算法九:Adaboost算法
Adaboost 是 bosting 的方法之一。bosting就是把若干个分类效果并不好的分类器综合起来考虑,会得到一个效果比较好的分类器。下图,左右两个决策树,单个看是效果不怎么好的,但是把同样的数据投入进去,把两个结果加起来考虑,就会增加可信度。
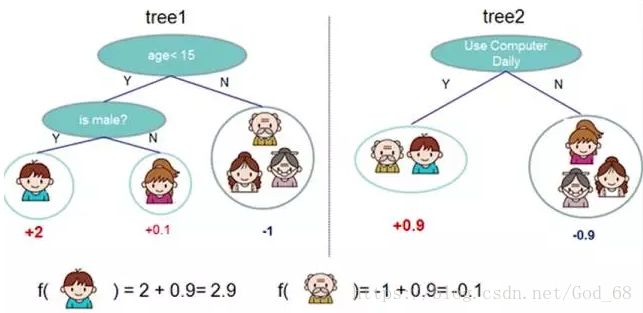
Adaboost 的例子,手写识别中,在画板上可以抓取到很多 Features,例如 始点的方向,始点和终点的距离等。
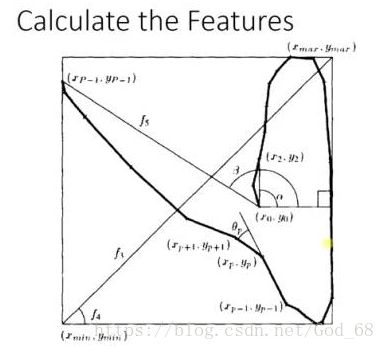
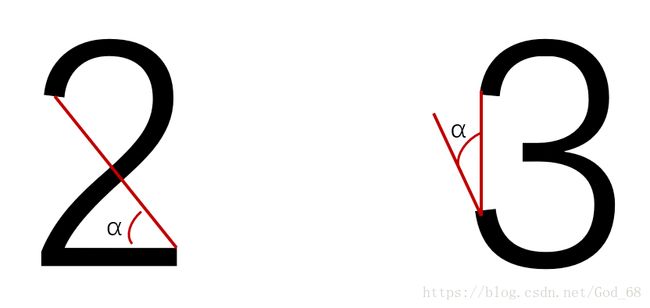
Training 的时候,会得到每个Feature 的 Weight,例如 :数字2和数字3的开头部分很像,这个Feature 对分类起到的作用很小,它的权重也就会较小 。

而这个 Alpha 角 就具有很强的识别性,这个Feature 的权重就会较大,最后的预测结果是综合考虑这些Feature 的结果。
算法十:神经网络
Neural Networks 适合一个input可能落入至少两个类别里,NN 由若干层神经元,和它们之间的联系组成,第一层是 input 层,最后一层是 output 层,在 hidden 层 和 output 层都有自己的 classifier。
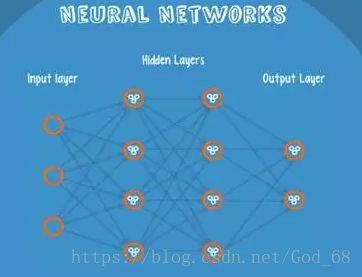
Input 输入到网络中,被激活,计算的分数被传递到下一层,激活后面的神经层,最后Output 层的节点上的分数代表属于各类的分数,下图例子得到分类结果为 class 1。同样的Input 被传输到不同的节点上,之所以会得到不同的结果是因为各自节点有不同的weights 和 bias。这也就是 forward propagation。

附录:
(1)参考资料1
(2)参考资料2
(3)《视觉机器学习20讲》清华大学出版社,谢剑斌等著。