【Numerical Optimization】2 非约束优化基础 (Jorge Nocedal 学习笔记)
本章主要介绍:无约束优化的基本概念(泰勒定理等),以及各种算法(线搜索/信任域)的基本介绍总览
对于无约束优化,其数学表达如下:
其中 x∈Rn x ∈ R n 是实数向量且 n>=1 n >= 1 , f:Rn→R f : R n → R 是一个平滑函数(处处连续可微)。通常对于这样的情况,我们可以求取其局部最优解(求取全局最优解在一些情况下非常困难)。
举个例子
拟合 ϕ(t;x) ϕ ( t ; x ) 这样一个同时拥有指数和振荡性质的函数,通过其已知函数点 y1,y2,...ym y 1 , y 2 , . . . y m (分别对应 t1,t2,...,tm t 1 , t 2 , . . . , t m ),得到其中的参数 x1→x6 x 1 → x 6
将其参数矩阵定义为 x=(x1,x2,...,x6)T x = ( x 1 , x 2 , . . . , x 6 ) T ,并且定义其残差为:
最后可转化为下列非线性最小二乘法问题来解决拟合问题:
但如何解这个非线性最小二乘法问题呢?
1. 最优解
首先解决几个概念问题:
全局最优解:a point x* is a global minimizer if f(x∗)≤f(x) f ( x ∗ ) ≤ f ( x ) for all x
(弱)局部最优解:a point x* is a local minimizer if there is a neighborhood N of x* such that f(x∗)≤f(x) f ( x ∗ ) ≤ f ( x ) for all x∈N x ∈ N
(强/严格)局部最优解:a point x* is a strict/strong local minimizer if there is a neighborhood N of x* such that f(x∗)<f(x) f ( x ∗ ) < f ( x ) for all x∈N x ∈ N with x≠x∗ x ≠ x ∗
孤立局部最优解: a point x* is an isolated local minimizer if there is a neighborhood N of x* such that x* is the only local minimizer in N
其中需要注意的是,强局部最优解不一定是孤立局部最优解,但孤立局部最优解一定是强局部最优解(即,强局部最优解是孤立局部最优解的必要不充分条件)
1.1 雅各布矩阵与黑森矩阵
雅各布矩阵(Jacobian Matrix) 求函数的一阶偏导:
黑森矩阵(Hessian Matrix)求函数的二阶偏导,代表局部曲率
1.2 泰勒定律
如果目标函数 f:Rn→R f : R n → R 且连续可微, p∈Rn p ∈ R n 那么:
一阶:
二阶:
1.3 局部最优性质
1.3.1 一阶必要条件
若 x* 为局部最优解其 f 在 x* 的开邻域区间连续可微,那么 ∇f(x∗)=0 ∇ f ( x ∗ ) = 0
另外,当 ∇f(x∗)=0 ∇ f ( x ∗ ) = 0 时,我们称 x* 为平衡点(stationary point),局部最优解一定为平衡点
1.3.2 二阶必要条件
若 x* 为局部最优解且 f 在 x* 的开邻域区间的二阶导存在且连续,那么 ∇f(x∗)=0 ∇ f ( x ∗ ) = 0 且 ∇2f(x∗) ∇ 2 f ( x ∗ ) 部分正定(即 pT∇2f(x∗)p≤0 p T ∇ 2 f ( x ∗ ) p ≤ 0 )
1.3.3 二阶充分条件
假定 ∇2f ∇ 2 f 在 x* 的开邻域区间内连续且 ∇f(x∗)=0 ∇ f ( x ∗ ) = 0 且 ∇2f(x∗) ∇ 2 f ( x ∗ ) 正定(即 pT∇2f(x∗)p>0 p T ∇ 2 f ( x ∗ ) p > 0 ),那么 x* 一定是 f 的严格/强局部最优解
需要注意这一条是充分不必要的1.4 凸函数
之前也介绍过有关凸函数的性质,见这里,稍微重申一下:
若 f 是凸函数,那么任意局部最优解 x* 都是 f 的全局最优解。另外,如果 f 还是可微的,那么任何平稳点 x* 都是 f 的全局最优解。
1.5 非平滑函数的最优解思路
平滑函数指二阶连续可微,本书重点
一般而言,对于非平滑函数的最优解解决思路:
- 分成平滑片段并分段解决
- 或者对于连续但不可微的函数:检测其次梯度/广义梯度
2. 算法简介
对于所有非约束优化问题,都需要给出初始搜索点 x0 x 0 ,这个点的确定方法主要:
- 通过应用场景的原理机制确定
- 经验确定
- 用算法寻找
- 系统法
- 随机法
从这个初始点 x0 x 0 开始优化算法需要开始迭代 {xk}∞k=0 { x k } k = 0 ∞ ,直到 迭代次数达到限值 或 结果达到期望精度以内
而其算法主要起到的作用是寻找 xk→xk+1 x k → x k + 1 使得 f(xk)>f(xk+1) f ( x k ) > f ( x k + 1 )
的方法。
需要注意的是,非单调算法(nonmonotone algorithm)不要求没一步得到的 f(xk)>f(x{k+1}),只需要 f(xk)>f(x{k+m}) 即可2.1 线搜索 Line Search
重点是选择一个方向 pk p k , 在这个方向上用解一维最小化问题的方法寻找步长 αk α k ,每算一次 pk p k 和 αk α k 都需要更新:
其面临的重点问题是: pk p k 的选择
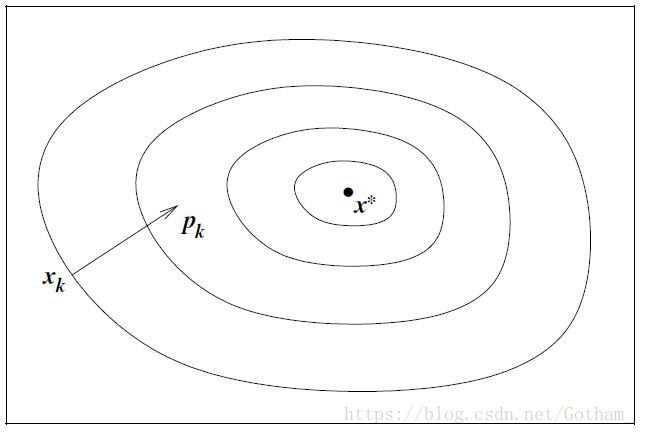
2.1.1 最速下降法 Steepest Descent Optimization
为寻找单位搜索方向 ||p|| = 1 则:
又因为 pT∇fk=||p||||∇fk||cosθ=||∇fk||cosθ p T ∇ f k = | | p | | | | ∇ f k | | c o s θ = | | ∇ f k | | c o s θ ,其中 theta t h e t a 是 p 和 ∇fk ∇ f k 直接的夹角,当 cosθ=−1 c o s θ = − 1 时可以得到最小时的 p 值:
可以看出,在最速下降法里面,搜寻方向与每步时的目标函数正交
2.1.2 下坡法 Downhill
在上述最速下降法的基础上,严格定义 pk p k 与 −∇fk − ∇ f k 的夹角 θk<π2 θ k < π 2 (即 cosθk<0 c o s θ k < 0 ),以保证步长足够小
2.1.3 牛顿法 Newton Optimization
在泰勒二阶变换的基础上,用 ∇2fk ∇ 2 f k 换 ∇2f(xk+tp) ∇ 2 f ( x k + t p ) ,当 ||p|| 很小时约等式准确:
使 mk(p)=0 m k ( p ) = 0 时
当 ∇2fk ∇ 2 f k 正定时,Newton direction pk p k 为 descent direction,否则不是(证明略)。
在这种方法中,除非特别需要,步长 α=1 α = 1
牛顿法的优点为:收敛速度很快;缺点为:需要计算 Hessian matrix(可以用有限差分或自动微分避免手动计算二阶导)
2.1.4 高斯牛顿法(准牛顿法)Quasi-Newton Optimization
使用近似 Bk B k 代替 Hessian ∇2fk ∇ 2 f k ,在无需计算 Hessian 的情况下保证线性收敛
推导:
在原泰勒二阶定义式基础上 加上 ∇2f(x)p ∇ 2 f ( x ) p 再减去 ∇2f(x)p ∇ 2 f ( x ) p
使得上式最后积分项为 o(||p||),设定 x=xk x = x k 而 p=xk+1−xk p = x k + 1 − x k 则得到:
当 xk x k 与 xk+1 x k + 1 在 x* 附近且 ∇2f ∇ 2 f 正定时,可将上式简化为:
使用 Bk+1 B k + 1 来代替 Hessian,得到割线方程形式:
从 Bk→BK+1 B k → B K + 1 的方法很多,其中最常用的有两种:
- SR1(symmetric-rank-one) 方程
Bk+1=Bk+(yk−Bksk)(yk−Bksk)T(yk−Bksk)Tsk B k + 1 = B k + ( y k − B k s k ) ( y k − B k s k ) T ( y k − B k s k ) T s k - BFGS 方程
Bk+1=Bk−BksksTkBksTkBksk+ykyTkyTksk B k + 1 = B k − B k s k s k T B k s k T B k s k + y k y k T y k T s k
如此代替之后,搜寻方向 pk p k 便可以如下推导:
pk=−B−1k∇fk p k = − B k − 1 ∇ f k
另外为了避免 因式分解/求倒数流程(factorization/back-substitution procedure),可直接利用更新 B−1k B k − 1 而非 Bk B k 的方式
Hk=defB−1k H k = d e f B k − 1
Hk+1=(1−ρkskyTk)Hk(1−ρkyksTk)+ρksksTk,ρk=1yTksk H k + 1 = ( 1 − ρ k s k y k T ) H k ( 1 − ρ k y k s k T ) + ρ k s k s k T , ρ k = 1 y k T s k
2.1.5 非线性共轭梯度优化 Nonlinear Conjugate Gradient Optimization
其计算更加简单,更有效率
其原理为:
线性方程组 Ax=B A x = B 其中 A 对称正定,解此线性方程组等价于求目标函数 ϕ(x) ϕ ( x ) 的最小值点(极小值点)
2.2 信任域 Trust Region
不同于线搜索方法只在单一方向搜寻最优解,信任域的原理如下:
- 建一模式函数 mk m k ,其在 xk x k 附近的部分与 f f 相似(对于距离 xk x k 远的 x 可能不适用)
- minpmk(xk+p) min p m k ( x k + p ) ,where xk+p x k + p lies inside the trust region ( xk+p x k + p 可看做处于信任域中)
- 需要选择定义信任域。通常而言,可行域为球形 ||p||2≤Δ | | p | | 2 ≤ Δ ,其中信任域半径为 Δ>0 Δ > 0 。椭圆和盒型信任域也可以用。
- 模式函数确认方程为: mk(xk+p)=fk+pT∇fk+12pTBkp m k ( x k + p ) = f k + p T ∇ f k + 1 2 p T B k p

2.2.1 信任域相关算法
除共轭梯度算法之外,线搜索算法上面提到的所有方法都有对应的信任域算法。
最速下降法( Bk=0 B k = 0 )
设定 Bk=0 B k = 0 则变为:
则:
可以看出,在这种情况下和线搜索的最速下降法很类似,其步长受到信任域半径的影响。
其他
- 当 Bk=∇2fk B k = ∇ 2 f k ,则为牛顿信任域法
- 当 Bk B k 满足 SR1 与 BFGS 方程时,则为高斯牛顿(准牛顿)信任域法
3. Scaling
To be poorly scaled if changes to x x in a certain direction produce much larger variations in the value of f f than do changes to x x in another direction
举个例子
f(x)=109x21+x22 f ( x ) = 10 9 x 1 2 + x 2 2 中 x1 x 1 为 poorly scaled,而 x2 x 2 相对更好一些
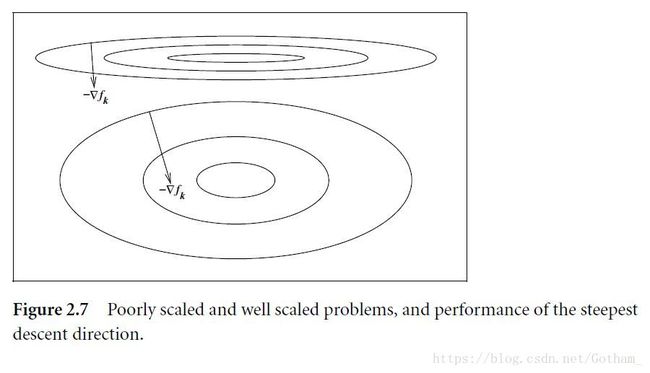
算法来说,最速下降法对于 scale 非常敏感,而牛顿法在这一点上表现更好。通常做算法的时候需要进行尺度/标度不变性(scale invariance)测试。