Python3.6.3官方文档阅读笔记
Python3.6.4官方文档阅读笔记
- Python3.6.4官方文档阅读笔记
- 一、基本格式说明
- 二、基础语法以及相关操作模式
- (一) 基本数据类型以及操作符
- 1、数字类数据类型
- 2、字符串
- (1) 字符串打印
- (2) 字符串拼接与访问
- 3、列表
- 4、补充
- (二) 控制流程
- 1、if…elif语句
- 2、for循环语句
- 3、while循环
- 4、range()函数
- 5、countinue、break和else关键字
- 6、pass关键字
- (三) 函数相关
- 1、函数定义
- 2、函数中的默认参数
- 3、关键字参数
- 4、任意参数列表
- 5、拆包
- 6、lambda表达式
- 7、文档规范
- 8、函数注释
- 9、代码风格
- (一) 基本数据类型以及操作符
- 三、Python标准库
- 1、数据结构
- (1)、列表详解
- (2)、将列表作为栈
- (3)、将列表作为队列
- (4)、递推式构造列表
- (5)、嵌套列表构造
- (6)、del关键字
- (7)、元组
- (8)、set集合
- (9)、字典
- (10)、循环技术
- (11)、更多的条件语句
- 2、模块
- (1)、模块简介
- (2)、模块的使用和注意事项
- (3)、执行模块
- (4)模块名字查找
- (5)Python模块加载问题
- (6)标准库模块
- (7)dir
- 3、包(Packages)
- (1)、包简介
- (2)导入包内所有内容(import *)
- (3)包内引用(Intra-package References)
- 4、输入与输出
- (1)、更多的输出格式
- (2)、读写文件
- (3)、文件操作
- (4)、将数据存入json
- 5、错误和异常
- (1)、异常
- (2)、处理异常
- (3)、抛出异常
- (4)、自定义异常
- (4)、定义清理动作
- (5)预定义清理工作
- 6、类
- (1)、作用域和命名空间
- (2)类定义
- (3)类对象
- (4)类属性和成员函数
- (5)关于函数和变量名
- (6)、继承
- (7)、私有变量
- (8)迭代器
- (9)、生成器
- 7、标准库使用
- (1)、系统接口
- (2)、文件通配符
- (3)、命令行参数
- (4)、错误输出重定向和终止程序
- (5)、字符串模式匹配
- (6)、数学库
- (6)、有许多提供了网络接口和网络协议的库,比较简单的有,从url获取数据的urllib.request和发送邮件的smtplib:
- (7)、日期与时间
- (8)、数据压缩
- (9)、性能测试
- (10)、质量控制
- (11)、Batteries Included
- (12)、输出格式
- (13)、模版
- (14)、使用二进制数据记录布局
- (15)、多线程
- (16)、日志
- (17)、列表工具
- (18)、十进制浮点数算法
- 8、虚拟环境和包
- (1)、创建虚拟环境
- (2)、使用 pip 管理包
- 9、浮点数问题
- (1)、浮点数精度
- (2)、表达错误
- 10、附录
- (1)、错误处理
- (2)、可执行 Python 脚本
- (3)、交互式启动文件
- 1、数据结构
这篇文章是我通过阅读官方文档学习Python时写的,不会对一些基础概念进行过多的说明,默认至少熟悉一门编程语言。因此,有的地方可能过于啰嗦有些地方又显得过于简洁。因此有问题的可以通过博客联系我,希望能给出改进的建议。
一、基本格式说明
Python源文件的格式和bash等脚本文件很类似,需要在头部添加脚本解释器的说明和编码规则,当然这些可选并不作为源文件的一部分,主要是为了源文件的阅读者方便。具体格式如下:
#!/usr/bin/python3
#-*- coding:utf-8 -*- Python的注释符号为 #,从#开始到行尾的所有字符都将被解释器忽略作为注释看待。
Python中不存在{}来控制作用域,使用缩进来控制作用域。
另外python交互模式是以三个’>’作为标志,如下:

可以在交互模式下直接输入相关代码进行相应的计算。并且在交互模式下输入可打印字符或表达式回车便可以回显,可打印字符或表达式一般为数字、字符串、列表、元组以及返回值为数字、字符串、列表、元组的表达式等。
二、基础语法以及相关操作模式
(一) 基本数据类型以及操作符
1、数字类数据类型
Python支持C语言中的大部分类型以及操作符比如int,float等,当然Python也定义了一些类似的数据类型比如Demical,Fraction。
这些数据的操作基本和C语言相同,基本运算符,加(+)、减(-)、乘(*)、除(/)以及除余(%)。但注意这里的除(/)不是地板除法而是正常的除法操作,结果个小数。同时还定义了地板除法(//),以及幂(**)。还有其他一些比较操作符后序描述。
另外,Python中变量的定义不需要类型。在交互模式下,Python还定义了一个行为就是用’_’来指代上一个未被赋值的表达式的值。
下图为上述内容的演示结果:

当输入的表达式出错时会打印相应的出错信息,如图中的Traceback…可以根据出错信息进行修改,另外这里的输入表达式计算并回显只是在交互模式下的状态,脚本文件中需要利用变量来暂存数据值并进行相应的显示与处理。
2、字符串
(1) 字符串打印
Python中的字符串是用”“或者”包裹的,左右引号必须匹配,’ “或” ‘都是错误的。
注:Python中可以使用print打印可打印字符和表达式,具体用法下面描述。
字符串的一般打印形式即直接使用print打印print("string")或者使用字符串变量print(str)
在使用print打印需要注意的问题:
1. 字符串中’\’作为转义字符后面接部分字符比如n,a,r,t等等都会与原来的意思不符合显示出来的是另外一种形式,比如\n是换行,\t是制表符。为了避免这种现象可以使用r来规避,如print(r"string\nstring");
2.要想分多行输入与打印字符串可以使用"""string"""和'''string'''的格式,具体结果见下图:

注:可以看到#在行中作为注释的规则在”’string”’中不适应,他被解释为字符串的一部分。
(2) 字符串拼接与访问
字符串拼接类似于C++和java中的string类,可以使用"string""string"或"string"+"string"将两个字符串连接在一起,也可以使用类似于3 * "str" + "str"的方式。前面提到的方式对于字符串变量也适用,但是不能将字符串和其他类型的变量相连接。
字符串的访问类似于C语言中的数组,但同时又添加了多种访问方式,如最常见的,这里str="string",str[0],str[1],字符串是从0开始计数,以及str[-1],str[-2],意思分别是倒数第一个字符和倒数第二个字符。注意:访问都不能越界否则会报错。
还有一种范围访问方式,格式为str[n1:n2],意思是从n1到n2的字符串,不包括下标为n2的字符,比如str="string",str[1:3]为tri。n1和n2可以缺省,n1缺省为0,n2缺省为字符串长度;n1,n2也可以是负值含义如上所述,并且n1和n2没有界限的限定。(如果理解困难可以将n1,n2理解为C++中的迭代器,n1为开始迭代器,n2为尾迭代器)
不可以通过范围和下标来替换字符串。
获取字符串的长度len(str)。
演示如下图:

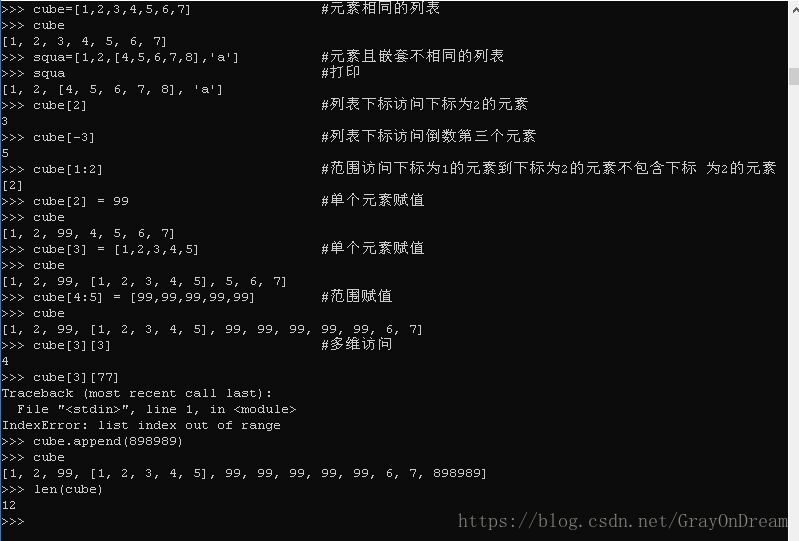
3、列表
列表就是多个元素的序列,用中括号[]包裹起来,元素内容可以相同,也可以不同,如:ls=[1,2,3,4],也可以是ls1=[1,'a','b',2]。列表的访问和字符串的访问相同,比如ls1[0],ls[-3],ls[1:2]之类的规则和字符串是相同的,即左闭右开。列表也可以通过+进行合并。
列表和字符串不同之处是列表可以通过下标访问并且赋值,而且赋值没有限制,可以原位置元素不同。并且如果需要赋值的是一个范围内的数据,赋值的值可以和列表指定范围大小不同。另外也可以通过append方法将元素添加到列表的最后,比如cu=[1,2],cu.append(3)。
同时,要说一下列表元素中有列表的情况,比如cube=[[1,2,3],2,3,[4,5]],需要通过多次访问,访问过程和其他高级语言中的多维数组类似,例如cube[0][1]意思是列表中下标为0的元素也就是[1,2,3]的下标为1的元素即2。当然列表可以多级嵌套访问方法和上面所说的类似。
也可以使用len方法来取得列表的长度。
演示如下图:
4、补充
Python提供一种特殊的赋值方式,如a,b=1,2等号两边的值是一一对应的,左右两边必须能够对应起来不可多也不可少。
Python还定义了高级语言基本都会支持的的比较操作符,如大于()、小于(<)、等于(==)、大于等于(>=)、小于等于(<=)、不等于(!=)。返回值是布尔类型即True或False。
打印时可以使用,将表达式隔开结果用一个空格作为分隔符将结果显示。并且可以通过print(string,end='ch')指定结束符,默认是换行。
表达式中-3**2的意思是-(3**2)要想计算-3的平方使用括号括起来即可,(-3)**2
因为”等特殊符号被Python用作一些结束符无法在相应的表达式中使用该字符,可以用转移字符\如”是\",#是\#等。
以下为演示结果:

注意:使用a,b=a,a+b格式进行赋值,如果之前a和b已经定义过可能就会正常执行,说是有可能是因为我自己实验结果不一样,所以尽量自己实验以下
(二) 控制流程
Python中的控制流程和大部分的高级语言类似都包含if,for,while等流程控制操作符,只是在格式上有细微的不同。同时Python还定义了一些其他方便运算的关键字,下面进行简单的描述。
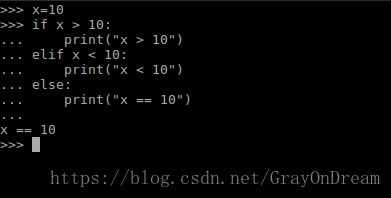
1、if…elif语句
if控制流程的基本格式是:
if [expression]:
[expresion]
elif [expresion]:
[expresion]
else:
[expresion] if和elif可以多层嵌套,需要注意的是每个判断表达式后要接冒号(:)。判断条件中的表达式和C语言中相同要求能够进行布尔运算,如果表达式为真则执行相应的表达式,为假则跳转到else或elif语句进行执行或判断。
演示图:
2、for循环语句
for语句在C语言中需要指定初始值,判断条件,步进的大小,但Python中的for更为简单些。for语句的格式是:
for [expresion1] in [expresion2]:
[expresion3]expresion2应该是一个类似于列表的变量或表达式比如字符串,列表,序列等等,expresion1应该是一个变量用于接收从expresion2取出来的值。for语句执行的结果是从expresion中依次取出一个值赋给expresion1然后执行expresion3。(这块感觉讲的很模糊)可以理解为C++中迭代器如下代码,python中只有it,str和expresion其他比较和自增的步骤Python替你做了:
for(auto it = str.begin(); it != str.end(); it ++)
expresion;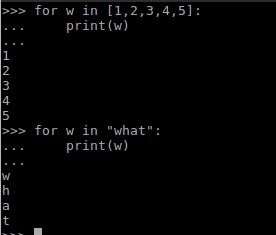
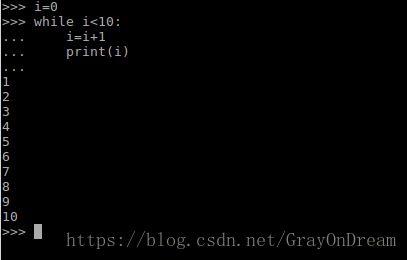
3、while循环
while语句和for也是循环语句不同之处是while只有一个判别式,格式为:
while [expresion1]:
[expresion2] expresion1中的表达式需要能够进行布尔运算,True就执行循环体,False就退出循环。
4、range()函数
如果你想获得一个数字序列可以使用range()来获得,range可以指定范围的起点,终点,步进。一般起点和步进可以省略,如果起点省略则默认为0,步进省略默认为1。range(begin,end,step)的意思是[begin,end)中以begin为起点step作为步进的所有元素,注意不包括end。
另外要显示range中元素可以使用list函数打印。
需要注意的是range返回的是一个对象不是列表,因此可以使用其他成员方法进行修饰,具体查看官方文档。
range演示图:

5、countinue、break和else关键字
break和continue关键字和C语言相同,break是跳出循环,continue是跳过本次循环执行下一个循环。for和while中的else是可选的,意思就是可写可不写,如果写了在for或while正常结束的时候会执行else中的语句,如果执行不正常退出循环则不执行(如通过break跳出循环)。
演示图片:
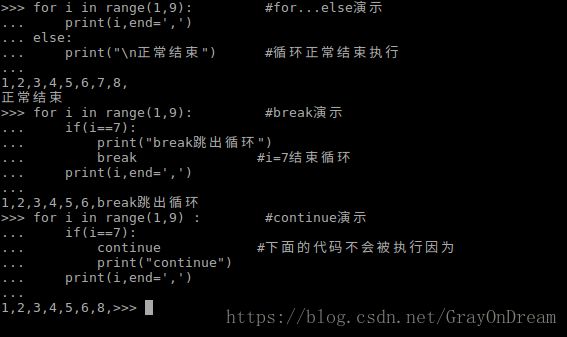
6、pass关键字
pass关键字的本意是什么都不做,类似于汇编中的nop,一般用作三个用途:
1、创建最小类;(类在后面讲)代码是
class classname:
pass2、作为占位符,比如你定义了一个函数但又没有想好具体实现方法,可以添加pass作为占位符以后在回来修补,代码如下:
def functionname():
pass3、什么都不做的空位,循环中可以用到
(三) 函数相关
1、函数定义
Python中的函数和C语言中的函数一样可以理解未可供调用的代码块,Python中函数定义的一般格式是:
def function-name(parameters-list):
[expresion]
return [result] #可有可无
function-name是函数名可以自定义,符合一般命名规则即可;parameterslist是参数列表可有可无,看你的需求;[expresion]应该是你需要执行的代码,return用来返回值给外部调用者,如果没有默认返回None可以用print查看。
Python中的函数也是对象,因此可以通过赋值的方式将函数赋值给其他变量。
演示图:

2、函数中的默认参数
Python的函数可以指定默认参数,当参数未指定具体值时使用默认参数,若指定使用指定值。函数格式为:
def function-name(para1,para2=def2):
[expression]
需要注意参数列表中有默认参数的参数必须在无默认参数的参数的右边,因为参数匹配是从左到右的;如果有默认参数的参数可以在无默认参数的参数的左边,除非全部提供参数否则无法为有默认参数的参数之后的无默认参数的参数匹配参数。
有默认参数的函数调用时必须为无默认参数的参数提供值,其他参数看你的需求。
演示图:
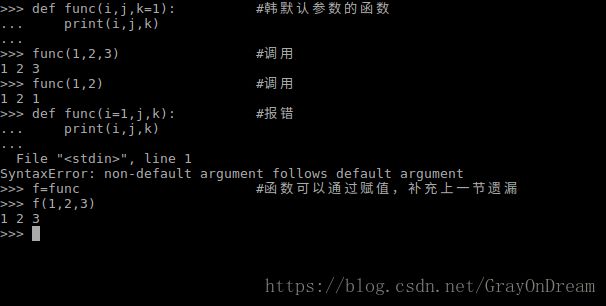
另外,需要注意的是,参数的传递发生在函数的调用时期,默认参数只在第一次调用时进行赋值,也就类似与C语言中的静态变量。对于一些可变对象如列表,字典,大多数类等对象来说可能会出现不同函数共享同意变量的情况。如下图所示:

要想解决这个问题可以用下图所示代码:
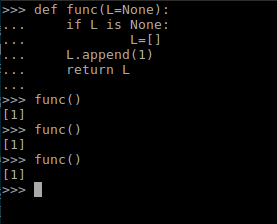
3、关键字参数
上面说道默认函数参数是从左到右进行参数匹配的,不能跨关键字传参,但Python也提供了另一种方法进行精确的函数传参。格式如下:
def function-name(para1,para2=p2,para3=p3,para4=p4,para5=p5):
[expression]
function-name(p1,para3=t3) 函数调用时指定参数对应的形参就可以精确的进行参数传递,但是参数的传递时不能在关键字参数后面插入普通的传参方式,即便参数的位置是对的也不行,也就意味着普通传参需在关键字传参的前面。演示如下图:
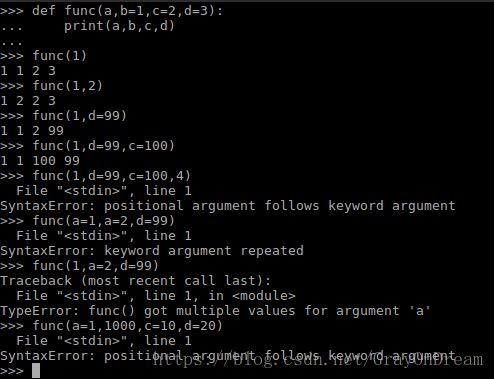
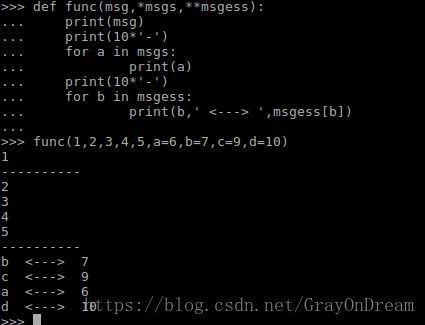
有一种例外,函数定义中*表示接受一个tuple,**表示接受一个字典即便参数列表中没有该参数也可以接受,但是*必须在**的前面*必须在末尾,函数格式与调用格式如下:
def function-name(par1,*par2,**par3) function_name(1,2,3,4,5,a=4,b=5,h=9) 该调用形式中1会传参给par1,2,3,4,5,会传参给par2,剩余的会传参给par3。如下图:
4、任意参数列表
任意参数列表和上一节最后提到的有关,使用*接收参数,*接受的是一个元组,前面参数列表匹配剩下的参数就会传递个*对应的变量,也就意味着*之后的变量无法获得参数,因此其只能通过关键字参数获得参数值。演示图如下:

5、拆包
*可以对列表类的对象进行拆包,**可以对字典累的对象进行拆包,拆包的意思可以理解为讲对象内的元素裸露出来,对于列表,[1,2,3]拆包之后就是1,2,3,对于字典{a=1,b=2,c=3}拆包之后就是讲关键字对应的值裸露也就是{1,2,3},拆包之后的值可以传递给函数参数,只需与参数位置或关键字对应即可。
演示如下:
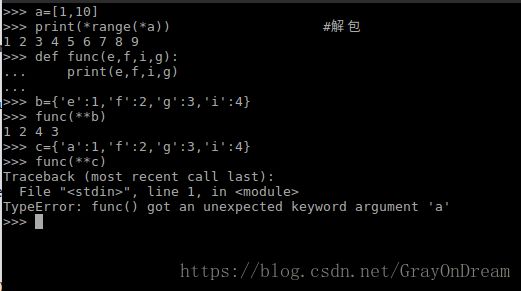
如图所示c因为关键字不对应因此无法传递参数给func。
6、lambda表达式
lambda表达式就是用一句表达式来定义一个函数,一般用来定义一些轻量级的简单的函数,就可以不去定义真正的函数了,lambda的格式是:
lambda [参数列表]:[表达式] lambda定义的函数可以作为普通函数使用。

7、文档规范
这里提及的只是一部分并没有完全的文档说明规范,可能之后补充。
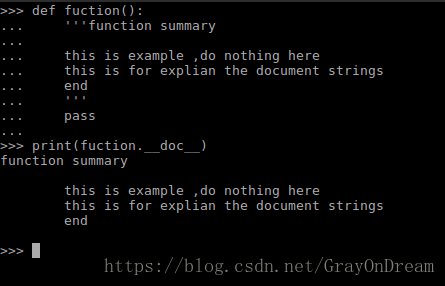
第一行应该是类或者方法的简单说明,不应过长
第二行为空白行
第三行开始对类或者函数进行完全的说明
可以使用print(function_name.__doc__)查看文档说明
8、函数注释
Python为每个对象提供了方法__annotations__获取函数的注释,自定义的方法的格式是:
def function-name(par1:comm1=tar1,par2:comm2=tar2)->comm3:
[expresion] 解释一下comm1,comm2,comm3全是注释分别是参数1参数2和返回值的注释,而par1,par2分别为参数名,tar1,tar2分别未参数1和参数2的默认参数。
演示结果:
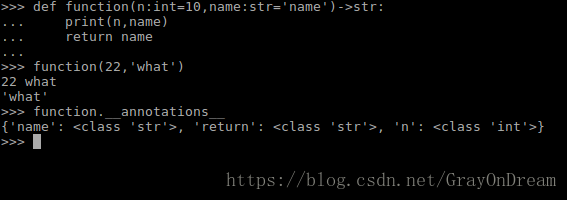
解释一下打印的结果的意思是函数参数n和name的类型为int,返回值为字符串。
9、代码风格
代码风格是为了别人方便阅读代码而自我约束的规范,并不要求任何人遵守该规范,但是为了方便代码的维护与管理好的代码风格很必要,一般性的要求如下:
1、使用四个空格缩进。4个空格缩进是为了避免tab在不同环境下的差异引起的不必要的代码阅读障碍。
2、一行的字符量尽量不要超过79个字符。过长的表达式很难阅读,尽量是代码保持可阅读性。
3、使用空白行,空白块来分隔类、函数和局部函数的定义。这样可以很快分清类的结构,因为Python没有{}之类的分界符,完全是由缩进和空白行区分,因此插入空白行是好的习惯。
4、可能的话,把注释和代码放在一行上。
5、使用文档字符串。
6、在操作符和逗号后面使用空格,但不要直接在包围结构中使用空格。
7、让你的类名和函数名看起来更有意义,尽量让别人看到你的函数名或类名便可以明白他的作用,一般采取驼峰命名法或者用下划线将单词隔开。
8、如果您的代码旨在用于国际环境,请不要使用国语酷炫的编码。Python的默认,UTF-8甚至纯ASCII在任何情况下都是最好的。
9、同样,不要在标识符中使用非ASCII字符尽管可以,即使只有很小的机会,但说不同的语言会读取或维护代码。
三、Python标准库
1、数据结构
(1)、列表详解
之前我们已经熟悉了list的基本用法,下面在具体说一下列表的其他方法:
| 成员函数名 | 功能说明 |
|---|---|
| append(x) | 将x添加到list的末尾 |
| extend(iter) | 通过迭代器iter将元素添加到列表末尾 |
| insert(i,x) | 将元素x插入到指定的位置i,i可取0-len(list) |
| remove(x) | 删除list中第一个值为x的元素,如果没找到报错 |
| pop(i) | 从列表中弹出下标未i的元素并返回,i可以不写,则弹出返回最后一个值 |
| clear | 移除列表的所有元素 |
| index(x,start,end) | 返回从列表中start开始到end之间第一个元素值为x的下标,start和end可选,默认在整个列表中搜索,若没找到返回值错误 |
| count(x) | 返回list中值为x的元素出现的次数 |
| sort(key=None,reverse=False) | 在本地对列表进行排序,key为用来排比较的函数,reverse指定排序为正序还是逆序 |
| reverse | 本地翻转列表 |
| copy | 返回list的一个副本 |
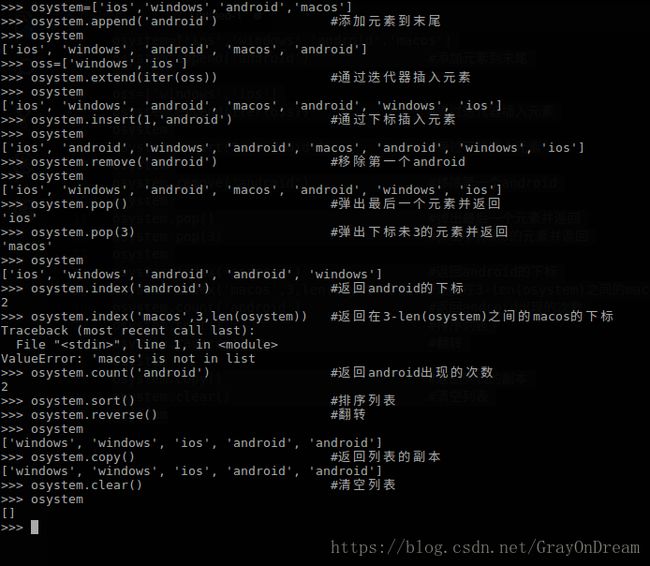
(2)、将列表作为栈
利用list实现栈的操作,栈即先进后出的序列,利用list中的append和pop方法即可实现。append相当于栈中的push,pop就是pop。演示如下:

(3)、将列表作为队列
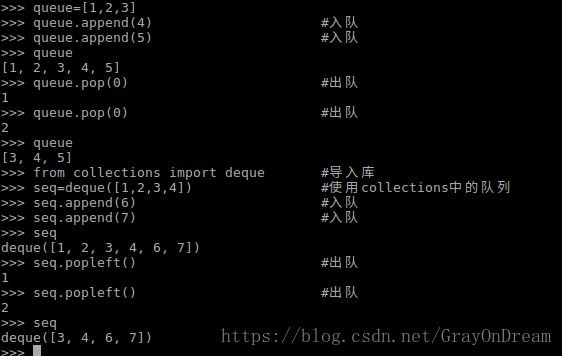
利用list实现队列,队列即先进先出的序列,可利用append和pop来实现,append相当于队列的endeque,pop相当于队列的dequeue。但是使用list有个问题是出队时太过耗时,因为要把出第一个元素外的所有元素移动一遍。因此可以使用collections.deque中定义的队列进行操作。
演示如下:
(4)、递推式构造列表
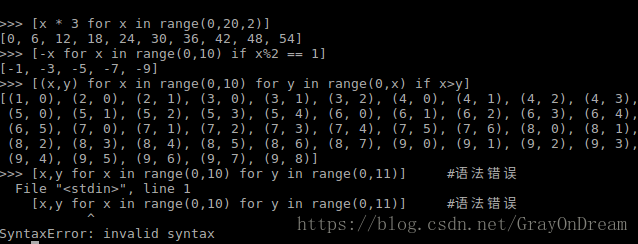
通常我们构造列表除了直接赋值外就是通过循环进行构造,Python还提供了一种比较方便的构造方式递推式构造列表(List Comprehensions),递推式构造列表的基本格式是:
[(x1,x2,x3) [expresion1] [expresion2] [expresion3]]上面的表达式返回的就是一个列表,其中x1,x2,x3可以数量没有限制,当只有一个x1时可以省略括号,后面的表达式可以有多个,但只能是for或者if语句,并且前面的参数列表x1,x2等必须在后面的表达式中出现过,并且参数列表也可以用一些函数进行修饰。递推式构造可以解析为:
expresion1
expresion2
expresion3
list.append(x1,x2,x3) 演示图片如下:
(5)、嵌套列表构造
对于构造嵌套列表,官方文档中是以矩阵开始的,我这里说一下我自己的理解。嵌套列表构造的仍然符合上一节所说的递推式列表构造表达式中可以包含if和for数量不限。基本格式为:
[[(x1,x2) [expression1] [expression2]] [expression3] [expresion4]] 可以看到前版本部分[(x1,x2)[expresion1] [expresion2]和上面提到的递推式构造相同也就意味着这种方式基本可以无限嵌套下去当然一般不会这么做,另一个层面来说所说的嵌套列表构造本身也是递推式构造的变体而已,因此递推式的要求和解析方式同样适合嵌套式。
expression2
expression3
list.append([(x1,x2) [expression1] [expression2]]) 对于嵌套式构造文档中还提到了内建方法zip,可以理解为将不同列表的元素进行一一对应的构造成元组,返回的是迭代器
演示图:

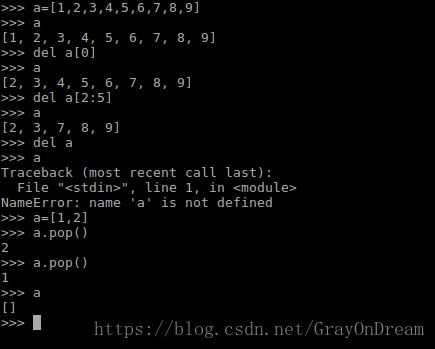
(6)、del关键字
Python定义了del关键字,del可以用来删除列表中的单个元素,也可以用来删除列表中一个范围的元素,甚至于删除整个列表。和pop和clear不同使用pop删除队后一个元素后或者clear之后列表都被置空,但是使用del列表就不复存在了。演示图如下:
(7)、元组
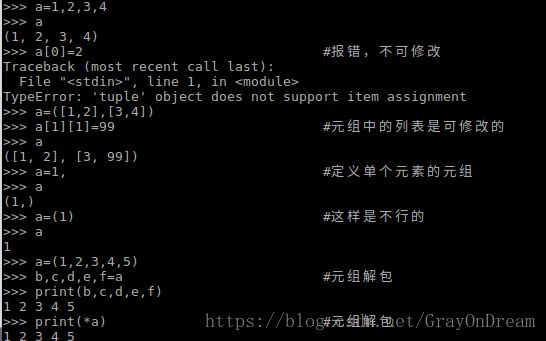
元组是和列表很相似的顺序数据结构。元组和列表的不同之处是元组的元素是不可修改的,列表的元素是可修改的,当元组包含可修改序列时比如列表,该可修改序列中的元素是可修改的。元组和列表 另一个不同是,元组一般用来存放不同类型的元素,列表存放相同类型的元素(虽然可以存放不同元素)。元组通常通过解包或索引访问元素,列表通过迭代访问。
注意,如果想定义一个只有一个元素的元组需在末尾加逗号,否则会被解释成定义一个该值类型的变量。
元组的解包有两种方式一种是通过*进行解包,另一种是使用p1,p2=t的方式将元组中的元素传递给每个变量,元组的数目必须和左边变量的数目相同。
演示:
(8)、set集合
Python还定义了无序的数据集合set,set中的数据是独一无二的是无序的类似与C++标准库中的set。创建集合可以使用set或者{}进行创建,但如果要创建空集合只能使用set,因为使用{}创建的是字典。
set支持基本的数学操作与,或,异或。并且set也支持递推式构造和list相同。演示如下:

(9)、字典
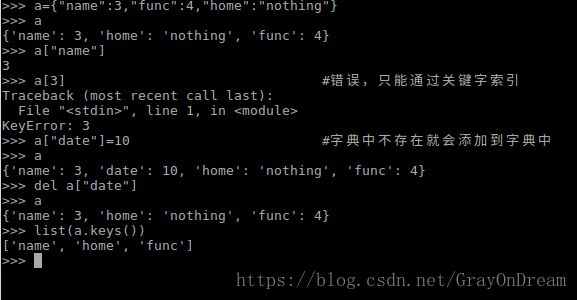
Python还提供了一种利用关键字进行索引的集合——字典,和前面提到的序列list,tuple等通过下标索引不同,字典是通过关键字索引的。字典的关键字只能是不可改变的类型,比如字符串,数字,元组,列表就不行,列表可以通过一些成员函数进行修改。
字典是一个无序的键值对key:value的集合。在一个字典中关键字是独一无二的,可以通过关键字索引对应的值,如果给一个不存在的关键字赋值该字典就会在字典中添加对应的键值对,如果给一个已经存在的关键字赋值,旧的值会被覆盖,并且索引一个不存在的值是错误的。可以使用del删除字典中的键值对,也可以使用类似于list(a.keys())获得关键字的列表。
另外可以使用dict构造字典,可以使用以下三种形式进行构造:
dict([(key1,val1),(key2,val2)]) dict(key1=val1,key2=val2)也可以使用递推式构造。
{x:y expresion} 演示图片:
(10)、循环技术
1.循环时,对于字典可以使用items成员方法同时获得关键字和值;
2.循环时,对于一个序列,可以通过enumerate方法同时获得索引和值;
3.循环时,当有多个序列,可以使用zip解包同时获得不同序列的值;
4.循环时,可使用reversed逆置序列反向遍历;
5.循环时,可以通过sorted方法排序序列后访问
6、循环时,如果需要修改一个列表的值,新建一个列表接受其值是一个明智的选择。

(11)、更多的条件语句
Python提供了如下for while if等判断条件语句中所用到的操作符或关键字:
1、in,not in。分别表示元素在,不在对应的序列中,符合条件为真,不符合为假;
2、is,not is。比较两个对象是否相同,只适应于可变对象,如list;
3、Python中比较运算符是可以相互链接的。如a==b>c指的是a等于b,并且b大于c;
4、and,or,not布尔操作运算符。分别对应C语言中的与或非
5、布尔操作和C语言中一样是可短路的,如果已经可以确定表达式的结果,后面的表达式将不再计算。如a==b or c==d,如果a已经等于b则后面的c==d的表达式则不再进行即便语法错误也忽略;
6、Python中不能在表达式中间对变量进行赋值。
7、优先级。所有的比较操作符优先级相同,且低于算数运算符。or,and,not三者优先级低于比较操作符,且三者中not最高,or最低。
注意:比较序列时采用类似字符串比较的字典序比较,即先比较第一个元素,如果第一个序列元素1大于或小于另一序列元素1,则序列1大于或小于序列2,如果相等则比较下一个元素以此类推,如若全部相等则相等
2、模块
(1)、模块简介
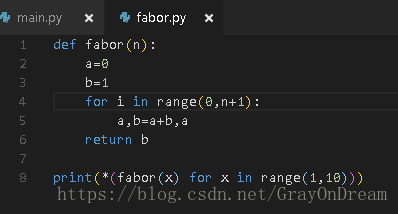
直接介绍的都是在交互模式下执行Python命令,Python也支持类似于脚本文件的将一些功能写入一个文件,然后让Python解释器对文件中的功能进行解释,这个文件就是模块。模块文件的扩展名为.py,执行方式是Python module-name,前面的Python根据你选择的版本不同可以进行变更比如Python3,Python2.7等。不同模块之间功能的引用可以通过import module的方式将模块功能导入到当前计算环境,需要调用其中的方法时只需module-name.function-name即可。Python还定义了全局变量__name__来获取模块名。
模块使用演示:
下图为模块程序:
使用方式:
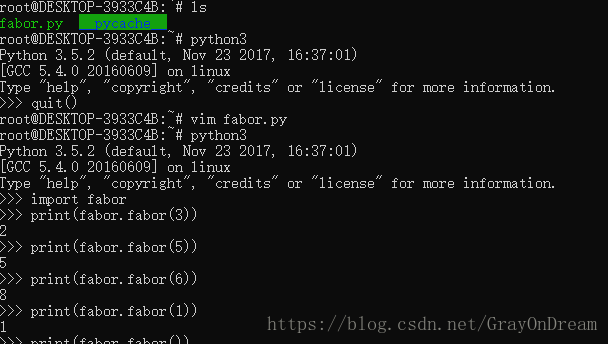
(2)、模块的使用和注意事项
模块中可以包含函数定义也可以包含执行语句,这些执行语句只在模块第一次被调用时执行。每个模块有自己的符号表,这些符号表对于模块内的成员和方法是全局的。模块之间可以互相调用,可以通过import module-name的形式导入模块然后用格式module-name.function-name使用模块中的方法。如果只想导入模块的部分方法或者变量只需使用from module-name import function-name导入对应的方法即可,执行这条语句后该方法的名字被加到当前模块的符号表中;其中function-name可以是*表示导入模块中的所有变量和方法,除了以下划线_开头的方法或变量。
在每个Python解释器运行环境下,模块只会被导入一次,使用importlib.reload(module-name)即可重新导入。
下面是文件内容:

使用演示:
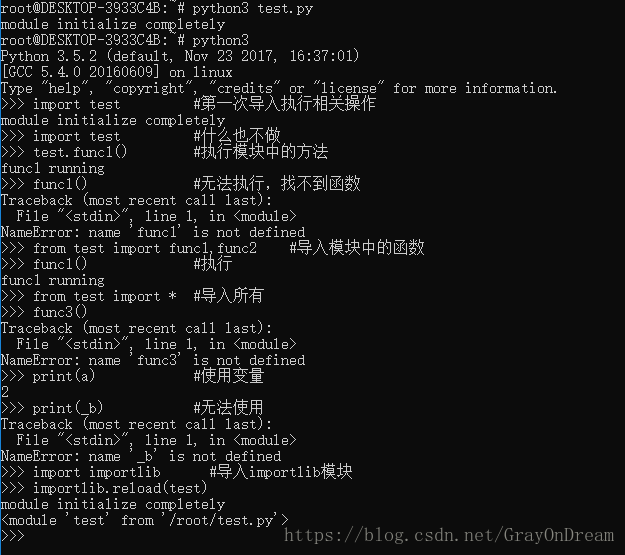
(3)、执行模块
上面提到了可以使用python module-name [args]的方式执行python脚本,可以通过在脚本中插入下面这句话保证只有脚本直接被执行时才执行内部的调用方法,如果只是导入则不执行。
if __name__ == "__main__":
#TODO:your code如图:

(4)模块名字查找
导入一个模块时,python名字查找顺序是:
1.内建模块。也就是python本身拥有的模块;
2.根据sys.path目录进行查找,分别为
+当前执行模块的运行目录;
+Python环境变量中的目录:
+安装的依赖目录。
初始化完成后,Python程序能够修改sys.path,脚本的运行目录在标准库目录前方,也就意味着本地的模块会覆盖标准库中的同名模块。
注意:符号链接(类似windows快捷方式)的目录不会被纳入查找范围。
注意:这块好像没懂!
(5)Python模块加载问题
Python为了加快模块加载速度,会将编译过的模块缓存在当前目录下的__pycache__目录下,对应的模块在该目录下以module-name.python-version,pyc的格式存放,module-name是模块名,python-version是python版本如python3,python35等。Python是通过检查源文件修改时间和编译过的文件时间来判断是否重新编译。另外这些编译模块是平台独立的。
Python只有在两种情况下不检查缓存目录:
1、经常重新编译而不缓存编译结果;
2、没有源文件的模块,也就是只存在编译后的结果文件的模块。
notes:
+可以使用-0或者-00减小模块编译后的尺寸,-0移除assert语句,-00移除assert语句和__doc__说明。在使用该开关时必须明确你要做什么。
+缓存编译模块只会加快加载速度不会改变运行速度
+模块compileall可以为目录中的所有模块创建.pyc文件
(6)标准库模块
Python定义了标准库模块,标准库模块文档在一个单独的说明文档中。标准库模块中的一些模块是内嵌在解释器中一方面为了提供系统支持,另一方面为了效率。标准库模块中有些是平台相关的如:winreg只支持Windows系统。标准库中还定义了一些变量如ps1,ps2,’path’,ps1的值是>>>,ps2的值是’…’,path是Python目录。
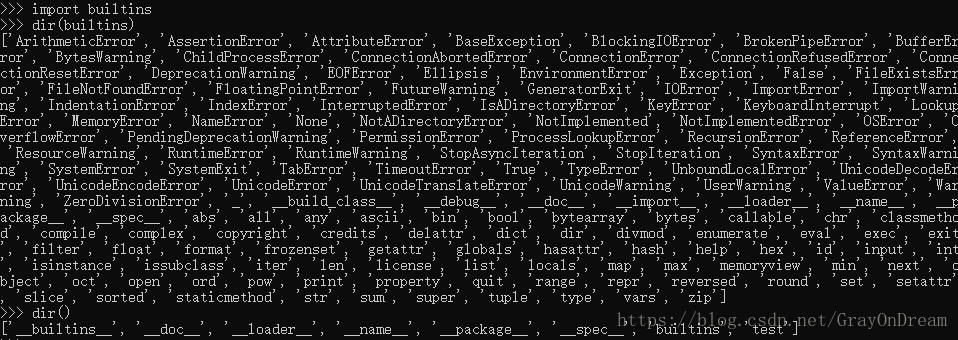
(7)dir
dir函数的功能是返回一个指定模块内定义的所有名字,除了’_’开始的名字的列表。若dir不提供参数则返回当前环境已经定义的变量,函数,模块等。dir不会包含内建的函数和变量,可以使用dir(builtins)查看。
3、包(Packages)
(1)、包简介
包是一种用来组织Python中的模块的方式。包可以用来隔离不同开发人员在不同平台不同环境下的模块,不然命名冲突将影响开发。包其实就是一个含有文件__init__.py的文件夹,该文件可以为空,也可以设置一些初始化工作。包提供了一种方便的层次性模块管理方式。Python导入包是根据sys.path目录进行检索的。
下图就是一个层级的报结构目录:
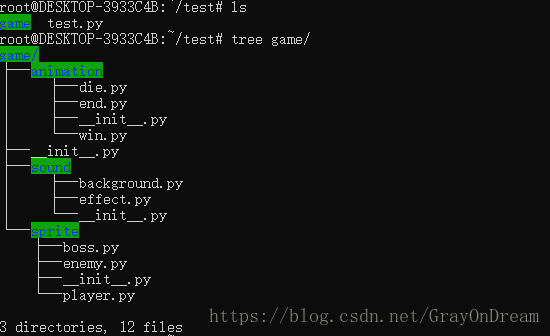
包的使用和模块有一些相似的地方,如上图中导入包可以使用下面的语句:
import game.sound或者:
from game import sprite 当使用import package.package.item,item可为包名或者模块名,进行加载模块或者导入包时必须指出完整的路径名,比如package.package.module.function()。使用from package import item,item可为包名,模块名,函数名或变量名,就可以省略前面的内容直接使用module.funciton()进行调用。
当导入包时,解释器会先寻找该包进行导入,如果不存在则判定为一个模块,试图加载模块,如果失败则返回ImportError错误。
上述表达格式可以归纳为import package1.subpack.item,item可以是包或者模块。
from package.package import item,item可以为包名,模块名,函数名或变量名。
演示图片:

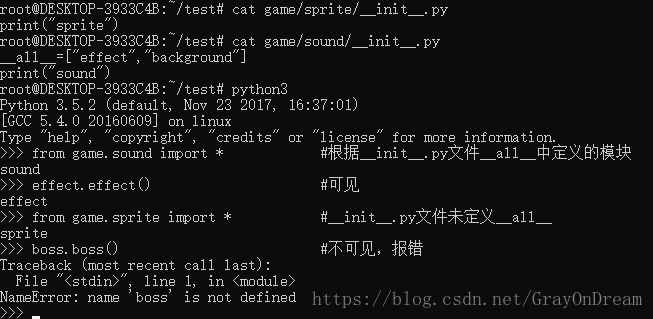
(2)导入包内所有内容(import *)
语句from package.subpackage import *,默认情况下(__init__.py为空)并不如我们所想会递归的导入包和模块,而是只导入该包内的模块等不包含子目录中的信息。如果希望能够导入子目录中的信息,必须明确的在__init__.py中定义变量__all__指明要包含的子包或模块的名称。__all__是一个列表包含你需要包含的包的名称。
演示图片:
(3)包内引用(Intra-package References)
__path__定义本模块搜索路径。
可以通过.,..来相对于当前路径进行包的导入,.表示当前目录,..表示上级目录和linux下的目录关系类似。
这种方式我自己没有执行成功,很尴尬!!!!
4、输入与输出
(1)、更多的输出格式
有三种输出格式:1、[expresion]直接输出,2、使用print函数;3、使用write写文件函数,将输出对象定向到标准输出sys.stdout。
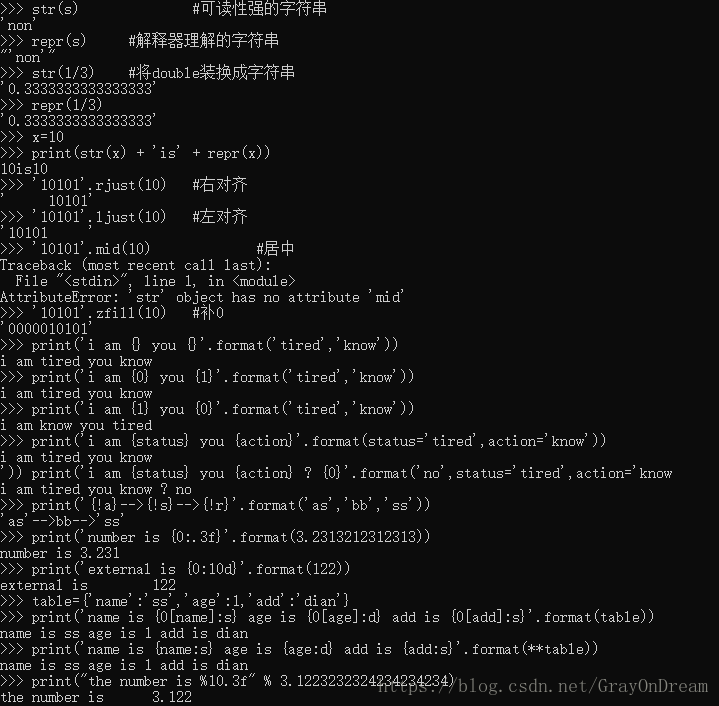
Python提供了两种将其它类型的变量转换为字符串的方法,一个是str,str返回一个可读的字符串,另一个repr函数返回一个能够被Python解释器解释的字符串,当字符串并不具备特殊含义时str和repr返回值相同。
Python还提供了其他方法,如rjust,ljust,center,都可接受一个整形参数,分别表示右对齐,左对齐,居中。str.zfill()函数将字符串扩展到指定位数多余的位数用0填充,如果原字符串大于指定长度,则不作处理。
str.format()市一中比较自由的字符串格式化方式。第一种方式类似于下面这种方式:
'we can {} something in the {}'.format('str1','str2') {}作为占位符,输出时会自动按顺序匹配format中的值。
第二种是指定参数顺序,类似与:
'we can {0} something in the {1}'.format('str1','str2') {}中的数值用于索引format中的值,0表示第一个值,1表示第二个值,{}中的数值索引没有顺序要求,0,1可以互换但对应的值还是format中第i+1个值。
第三种是通过关键字索引:
'we can {name} something in the {age}'.format(age='str1',name='str2') 并且关键字索引和数值索引可以组合起来。
还可以使用具体的格式对字符串值进行修饰,如{!a},{!s},{!r}分别表示输出获取ascii的返回值,获取str的返回值,获取repr的返回值。
使用{i:n}表示format中第i+1个值的输出宽度是n。还可以用类似的方式修饰数值,{i:.nf}表示format中第i+1个值小数点后保留n位。
对于字典也可以使用类似的方式输出
table={'name'=12,'age'=23,'addr'=120}
print('{0[name]d} is {0[age]d} and live in {0[addr]d}'.format(table)) #d表示输出数字也可以使用解包的方式获取关键字对应的值。
print('name {name:d} age {age:d} address {addr:d}'.format(table)) Python也兼容C中的字符串格式化方式使用方式类似于'string %d' % data。
上述演示图如下:
(2)、读写文件
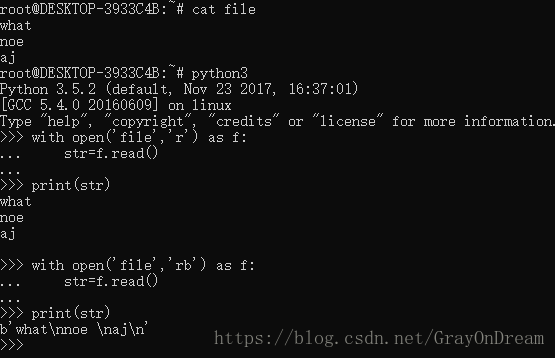
使用open函数获得一个文件对象,可以通过操作这个文件对象可以完成相应的文件操作。open函数接受两个参数,第一个是文件名,第二个是打开方式的描述,‘r’表示只读,‘w’表示写文件,‘r+’表示可读可写,‘a’表示以写模式打开,写入的内容会自动添加到文件末尾。上面所述均是以字符为单位进行操作是平台相关的,还可以使用模式‘b’以二进制模式操作文件,这种模式下是以字节为单位操作的。
需要注意的是文本模式下读取文件时平台相关的即不同平台下文本行为有区别,主要表现在行尾字符上,Windows下是‘\r\n’,unix下是‘\n’。在文本模式下,python读写文件只会解释为‘\n’。
打开文件操作和关闭文件操作必须成对出现,虽然Python会在程序终止时为你关闭未关闭的文件,但是将文件状态的控制权掌握在自己手里相对来说更好。另外在好似用文件时可以使用with关键字,意思是无论表达式中出现了什么错误,解释器都会进行相应的清理错误,这样可以保证文件的安全使用。格式如下:
with open('filename') as f;
read = f.read() 演示图片:
(3)、文件操作
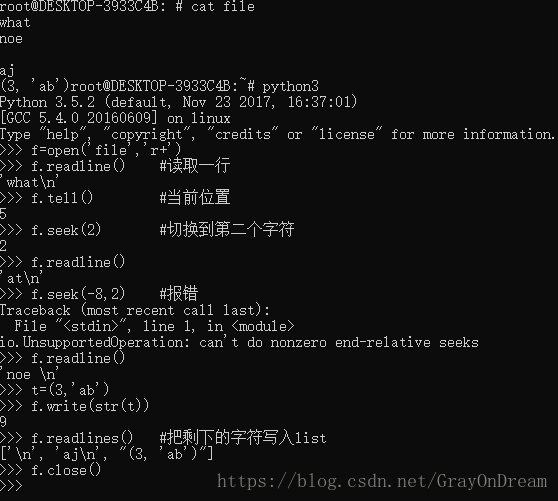
read方法可接受一个参数指定读入的长度,如果省略或者为负数则会读取文件全部内容,如果读到了文件末尾则返回string(”)。
readline函数每次读取一行,返回的字符串末尾会是‘\n’当读取空行是返回的时’\n’,到达文件末尾时返回的时”。
对文件的操作也可以使用循环操作文件对象,比如:
for line in file:
print(line) 也可以使用list(f)``f.readlines()将文件内容返回到列表中。write函数将字符串写入文件,并返回写入的长度,若接受的对象不是字符串会先把该对象转换成字符串在写入。因为文件操作会改变当前操作的位置(每次读取文件会自动改变指针到我们操作的下一个地方),因此可以使用tell函数获取当前位置,使用seek函数定位,seek接受两个参数一个是,偏移量,另一个事相对于谁from_what,from_what可以有三种取值,0表示相对于文件开头,1表示相对于当前位置,2表示相对于结尾(位置索引从0开始);如果没有以‘b’模式打开文件则只能从文件开始偏移,不能从文件尾。并且文件操作还有其他方法,可以查阅文档。
演示图片:
(4)、将数据存入json
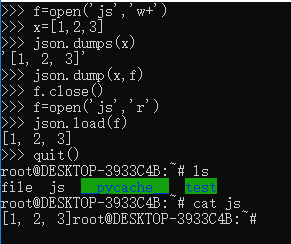
Python支持将数据写入json文件,可以通过json.dumps()将数据转换成json格式,用json.dump(dat,f)将数据dat写入文件f,json.load(f)将数据从为念中解析出来。这里提到的json只是简单说一下,具体以后再说。
演示图片:
5、错误和异常
一般性的错误中语法错误,运行时错误,如除0错误,段错误等中语法错误可以在编译时期有编译器进行检查但是运行时错误只能在程序运行时显现出来因此需要开发人员格外小心,对于C语言只能预防错误的出现,一旦错误发生就很难纠正,C++和java提供了异常机制来为用户处理错误提供了便利。Python同样也提供了类似的异常机制。
(1)、异常
正如上面所说,当运行时出错时Python会抛出相应的异常,抛出的异常一般包括异常名,异常具体说明,以及异常发生位置,开发人员可以通过这些信息对程序进行修改,但是并不是所有的异常都是致命的,因此可以通过异常机制捕捉异常保持程序的运行。
演示图:

(2)、处理异常
异常处理是通过异常处理语句进行处理的,基本格式如下:
try:
#TODO1
except ExceptType:
#TODO2 上述语句的工作机制是,如果语句TODO1中未发生异常则则不会执行TODO2语句,如果发生异常,则tr…except之间的语句中发生异常的语句下面的语句则不会执行,跳到except语句如果发生的异常类型和ExceptType匹配或者是ExcepType的子类则异常被捕获执行#TODO2中的语句,否则异常向外传递直至程序出错。
ExceptType中可以有多个异常类型,每个try后面可以有多个except语句。另外需要注意的是如果同一个try后面跟的多个except语句中捕获的异常类型之间存在继承关系则要把基类放在子类的下面,因为前面说了异常发生后,except捕获异常的类型可以使该异常类型也可以是其子类类型,类似于C++中的try…catch语句。
异常捕获语句的最后一个except后面的异常类型可以省略,他表示者这条语句会捕获所有异常。异常捕获语句同样可以使用else语句表示异常不发生时执行该语句。
捕获异常语句中可以为异常类型指定一个实例,该实例包含异常类型的具体信息,可以通过成员args获取异常中包含的参数。另外异常的抛出机制时如果异常触发就会从执行函数想外抛出,直至程序崩溃,除非被捕获,因此可以在函数外捕获函数异常。
演示:

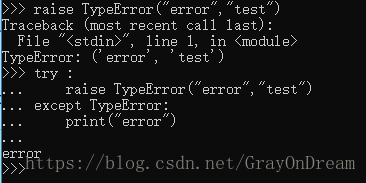
(3)、抛出异常
Python定义了raise关键字来主动抛出异常,抛出的异常必须继承自异常类。
(4)、自定义异常
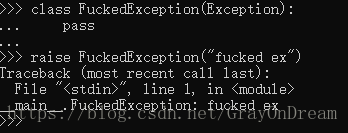
上一节提到了用户可以主动抛出异常,抛出的异常用户可以自定义,但这个一场必须继承自Exception或者其子类,关于继承和类可以查看下一大节的内容。这里先大概演示一下:
(4)、定义清理动作
Python中引入了异常清理,利用关键字finally类似与java中的finally关键字,意思是在离开异常块的时候该语句一定会被执行。这位清理工作提供了方便,比如在对文件进行操作时抛出异常可在finally中定义文件关闭操作,这就可以保证资源的正确使用。
示例图:

(5)预定义清理工作
有些对象自身设置了清除动作,无论对他的使用是否成功,在资源不再被需要时自动清除。这种行为就像之前提到的with语句的行为。
6、类
类是数据成员和方法和集合,数据成员作为类的状态,成员方法可以改变这些状态。Python中的类是在运行时动态创建的,可以在运行时修改类的结构。Python中的类同样包含了大多数面向对象编程语言中类所具有的特性,比如继承,多态等。
(1)、作用域和命名空间
Python中可以用不同名字绑定到同一个对象上,就类似与C++中的引用,但又不同,这种行为的特点是当获得一个比较大的对象时不用拷贝数据从而更加高效。
官方文档中提到了Python的命名空间是以字典的形式实现的,不同命名空间之间不存在任何关系,比如内建函数和类,全局命名空间以及本地函数等等,但我个人更倾向于将其看作作用域。在Python中命名空间是名字到对象映射,比如之前看到的modulename.functionname方式的调用,就是modulename和函数functionname之间的映射,functionname作为modulename的一个属性被调用。另外,命名空间的属性可以是可读的,可写的。我们可以为这些属性赋值,改变其状态也可以使用del关键字删除。
不同命名空间在不同情况下的生命周期是不同的。内建命名空间是在解释器开始运行时就创建的,并且是不能del的;一个模块的全局命名空间是在模块被载入时创建的,一般来说模块的命名空间会持续到解释器退出。由解释器顶层调用的语句(语句可以从脚本文件中读取也可以是交互模式下输入的语句)是作为__main__的模块的一部分,他们也有自己的全局作用域。函数调用的命名空间是在函数被调用时创建,函数返回或抛出未处理的异常时删除,也就意味着递归调用中每次调用都有自己独立的命名空间。
虽然作用域是静态确定的,但它们是动态使用的。在执行期间的任何时候,至少有三个嵌套作用域,它们的名称空间是直接可访问的。作用域名字搜索的顺序是:
1、本地作用域
2、本地函数作用域;
3、本地模块全局作用域;
4、内建定义作用域。
如果一个名字是全局的,所有的引用和赋值都会直接进入包含模块全局名字的作用域。如果需要在内部作用域重新绑定外部变量可以使用nonlocal关键字,否则外部变量是只读的,若尝试写该变量则会在本座用于内创建一个同名变量以保持外部变量值的正确性。
通常局部作用域引用局部函数的名字。在函数外部,局部作用域引用同样的命名空间作为全局作用域也就是模块的命名空间。类定义的时候也会在局部作用域创建一个命名空间。
无论函数在哪里被调用或如何被调用,一个函数的全局作用域限制为一个模块的命名空间。并且名字搜索是动态发生在运行时但是声明解析是发生在编译期,因此不要依靠动态名字解决方案。
Python的一个特殊之处在于,如果没有全局语句,那么赋给名字的任务总是进入最内层的范围。赋值不复制数据,它们只是将名称绑定到对象。对于删除也是一样的:声明del x从本地作用域引用的名称空间中删除了x的绑定。实际上,引入新名称的所有操作都使用本地范围:特别是,导入语句和函数定义将模块或函数名绑定到本地范围。
global关键字可以用来表示特定变量存在于全局范围内,应该在那里进行重新绑定;
nonlocal关键字表明,特定的变量存在于封闭的范围内,应该在那里进行重新绑定。
下面是官方提供的例子:

这节看官方文档看的很模糊,稍微看了下博客稍微理解了点但是还是不知道如何组织语言,这里的文字是将官方文档稍微翻译了一下,以后做修改
(2)类定义
类的定义基本格式如下:
class classname:
[your statement]&emsp: 类中可以包含成员变量和成员函数。类一旦创建就会引入一个新的作用域,类中的内容对外不可见除非显式的使用对象名引用类中的成员。
(3)类对象
上面提到了类中可以定义属性和成员函数,类中也默认添加了__doc__属性用来返回类的说明,类似文档规范的说明。可以通过classname.attributename的形式获得类的属性和成员函数。通过classname()的形式实例化类,获得一个类的对象。实例化类的时候也可以给类传递参数,但前提是类中定义了相应的__init__函数;init函数会在类被创建是调用,很像C++中的构造函数,init函数第一个参数是self也就是当前类本身。
演示图片:

(4)类属性和成员函数
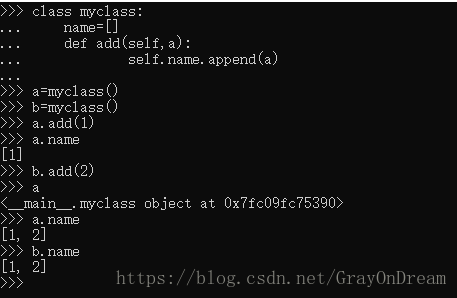
Python的类和其他面向对象语言有一些区别,Python类中的类变量是所有类共享的,也就是定义在类中函数外的变量,而实例变量和其他语言的行为一样只属于单个对象,也就是定义在函数内的变量。因此在定义变量时需要注意。
演示:
(5)关于函数和变量名
在Python中,函数名和成员变量名可以被同名的成员变量名或者成员函数名覆盖,这方面Python不提供语法检查,因此在对类的成员变量和成员函数进行定义时,尽量按照一定的规则命名来提高项目的可维护性。并且由于Python的一些特性Python无法提供完全的抽象数据类型,也就意味着无法隐藏实现细节。当然Python调用的C语言模块是可以做到的,因此某些时候你需要使用C语言编写模块。
Python中对外部模块的调用并没有限制,一般只有来自开发人员遵守的公约来约束,因此尽量遵守这些公约以免对项目的维护增加不必要的麻烦。
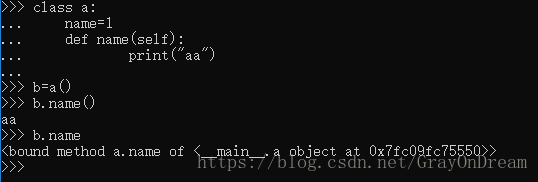
Python中每个类定义了__class__成员来查看类的类型。
演示:
(6)、继承
Python中类的继承基本格式如下:
class DerivedClassName(BaseClassName):
pass BaseClassName必须能被当前作用域发现,BaseClassName也可以是modulename.BaseClassName。继承类继承基类的成员方法和属性信息,但是这些方法还是属于基类的,可以认为是在子类中包含了一个基类。对类成员的名字查找是现在子类中查找如果找不到就到基类中去查找,者也就意味着子类的同名方法或属性会覆盖基类中对应部分,但是也可以用basename.funcaitonname显式的调用基类的方法。另外Python中所有的方法都是虚拟的。
可以使用isinstance方法查看一个实例是不是某个类的实例或者某个基类子类的实例。isubclass函数查看一个类是不是另一个类的子类。
Python支持多继承,基本格式如下:
class DerivedClassName(BaseClassName1,BaseClassName2,BaseClassName3):
pass 多继承中的名字查找是先查找子类,没找到再找BaseClassName1,没找到再找BaseClassName2以此类推。
需要注意的是在继承中如果基类未定义init函数,Python会自动调用父类默认的init函数,如果定义了init,需要用户显式调用init方法来为父类初始化其成员,如果不显式的初始化则无法在类中使用父类属性和成员。一般调用父类init有三种形式:
# A.method(self,arg) #1
# super(B, self).method(arg) #2
# super().method(arg) 1.BaseName.__init__(self,args)
2.super(DericedName,self).__init__(args)
3.super().__init__(args)
这些调用中使用super比较安全,可完成所有超类的构造工作。另外子类中调用其他方法这些形式同样适合。
演示图片:
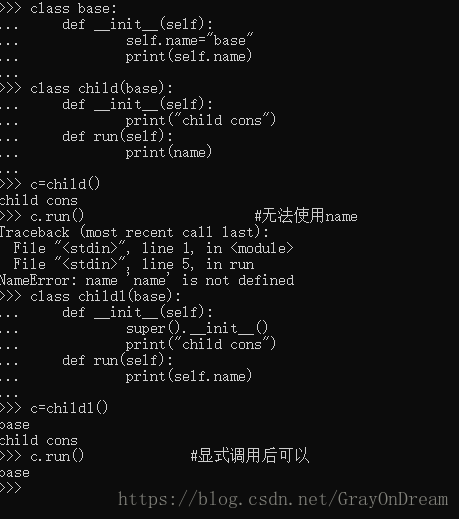
(7)、私有变量
Python中类的成员也分私有(privated),保护(protected)和公有(public),公有成员就是正常的变量和方法的命名,保护成员是在名字前加一个_,私有成员是在名字前加__,另外Python还提供__name__的形式,但这些一般是Python提供的,虽然我们可以定义但是不建议。Python中私有成员只有类本身能访问,保护成员只能子类极其自身访问,公有成员就是公开的没有限制。Python中的私有成员其实是通过改变名字来躲避访问的,如__name__解析为_classname__name,开发人员仍然可以通过上述方式访问。

(8)迭代器
for循环简介方便的使用方法基于迭代器,在后台,for 语句在容器对象中调用 iter() 。 该函数返回一个定义了 __next__ 方法的迭代器对象,它在容器中逐一访问元素。没有后续的元素时,next()抛出一个 StopIteration 异常通知 for 语句循环结束。也可以使用内建的next函数调用__next__函数。为了让类支持迭代可以定义一个__iter__函数返回一个含有__next__方法的对象,如果类本省定义__next__方法则__iter__只需返回自身就行。
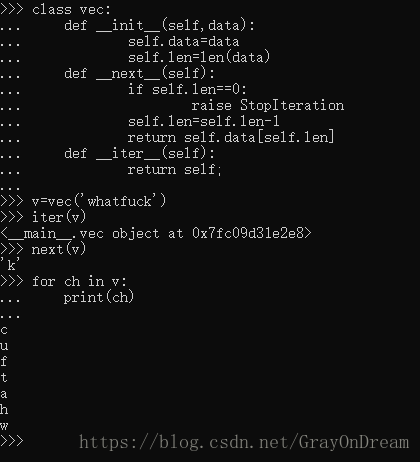
(9)、生成器
生成器是创建迭代器的简单而强大的工具。它们写起来就像是正则函数,需要返回数据的时候使用 yield 语句。每次 next() 被调用时,生成器回复它脱离的位置(它记忆语句最后一次执行的位置和所有的数据值。
关于生成器还不是很懂以后补充
7、标准库使用
(1)、系统接口
os模块提供了诸多系统接口,注意尽量使用import os而不是from os improt *因为os模块中也包含一个open函数使用后者会覆盖内建的open函数。
可以使用内建的dir和help函数获得对应模块的帮助信息。
shutil模块提供了更容易更高级的文件和目录管理接口。
演示图片:

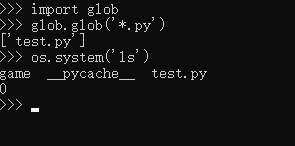
(2)、文件通配符
glob模块提供了一个函数,用于从目录通配符搜索中生成文件列表。
演示图片:
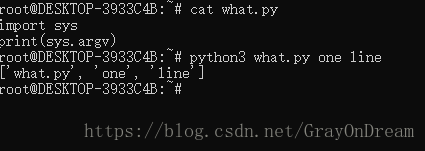
(3)、命令行参数
脚本可能需要从命令行读取参数可使用sys模块,其行为和C语言中的argc,argv很相似,另一更加灵活的模块是argparse。
演示图片:
(4)、错误输出重定向和终止程序
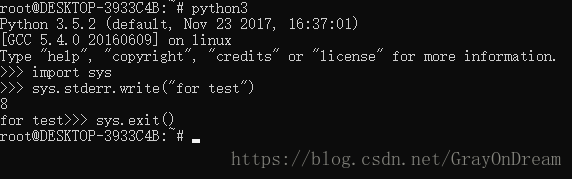
sys模块同一样拥有属性stdin,stdout,stderr分别值标准输入,标准输出,标准错误输出,可以使用sys.stderr.write来修改信息输出流。sys.exit()
演示图片:
(5)、字符串模式匹配
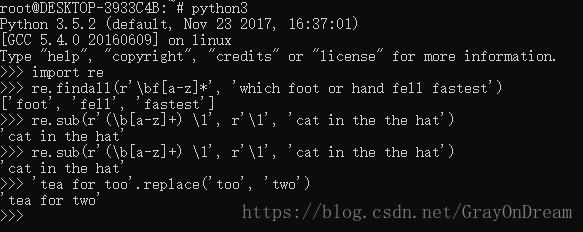
re模块提供了字符串处理的正则表达式工具,另外也可以使用字符串本身提供的简单的方法。正则表达式相关语法查看对应的文档。
演示图片:
(6)、数学库
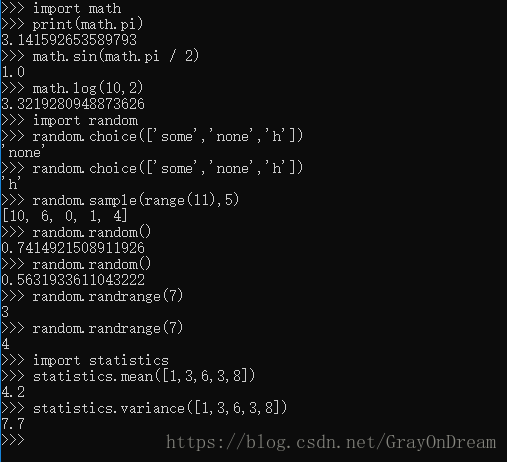
math模块提供了对C浮点数数学运算库访问,比如cos,lg等函数。
random模块提供了随机数的接口。
statistics模块提供了统计学计算的一些数学工具,比如吉萨un平均值,中位数等。
掩饰图片:
(6)、有许多提供了网络接口和网络协议的库,比较简单的有,从url获取数据的urllib.request和发送邮件的smtplib:
演示图片:

(7)、日期与时间
datetime模块提供了简单的和复杂的获取日期和时间的办法。虽然支持日期和时间算法,但实现的重点是对输出格式和操作的有效成员提取。该模块还支持时区感知的对象。
演示图片:

(8)、数据压缩
提供的数据压缩模块有zlib, gzip, bz2,lzma, zipfile 和 tarfile.

(9)、性能测试
Python提供了进行性能测试的工具timeinit。对于时间与细粒度级别,profile和pstats模块提供工具来识别更大的代码块中关键部分的时间评估。
演示图片:

(10)、质量控制
doctest模块提供了一个工具扫描模块嵌入到程序抯文档和验证测试。测试构建非常简单,只需将一个典型的调用和它的结果插入到docstring中。这可以通过向用户提供一个示例来改进文档,并且它允许doctest模块确保代码仍然适用于文档。unittest模块不像doctest模块那样轻松,但是它允许在单独的文件中维护更全面的测试集:
演示图片:
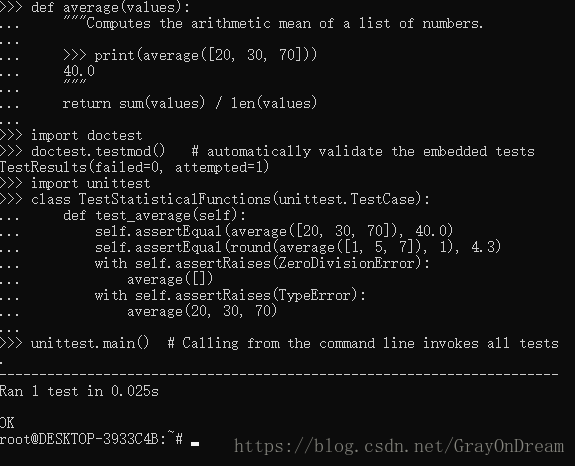
这节不是很懂,代码是来自官方文档
(11)、Batteries Included
Python 展现了“瑞士军刀”的哲学。这可以通过它更大的包的高级和健壮的功能来得到最好的展现。列如:
1.xmlrpc.client 和 xmlrpc.server 模块让远程过程调用变得轻而易举。尽管模块有这样的名字,用户无需拥有 XML 的知识或处理 XML。
2.email 包是一个管理邮件信息的库,包括MIME和其它基于 RFC2822 的信息文档。
3.不同于实际发送和接收信息的 smtplib 和 poplib 模块,email 包包含一个构造或解析复杂消息结构(包括附件)及实现互联网编码和头协议的完整工具集。
4.xml.dom 和 xml.sax 包为流行的信息交换格式提供了强大的支持。同样, csv 模块支持在通用数据库格式中直接读写。综合起来,这些模块和包大大简化了 Python 应用程序和其它工具之间的数据交换。
5.国际化由 gettext, locale 和 codecs 包支持。
(12)、输出格式
reprlib 模块为大型的或深度嵌套的容器缩写显示提供了 :repr() 函数的一个定制版本。
pprint 模块给老手提供了一种解释器可读的方式深入控制内置和用户自定义对象的打印。当输出超过一行的时候,“美化打印(pretty printer)”添加断行和标识符,使得数据结构显示的更清晰。
textwrap 模块格式化文本段落以适应设定的屏宽。
locale 模块按访问预定好的国家信息数据库。locale 的格式化函数属性集提供了一个直接方式以分组标示格式化数字。
演示图片:
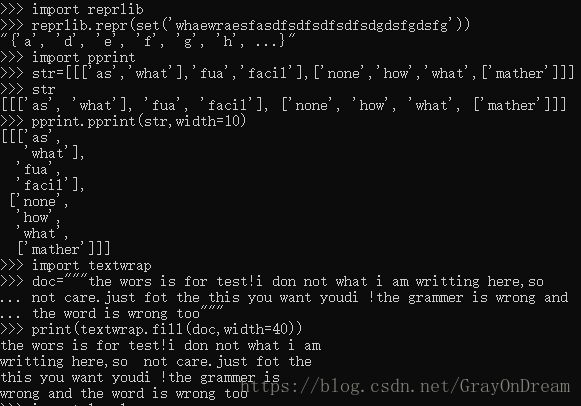
(13)、模版
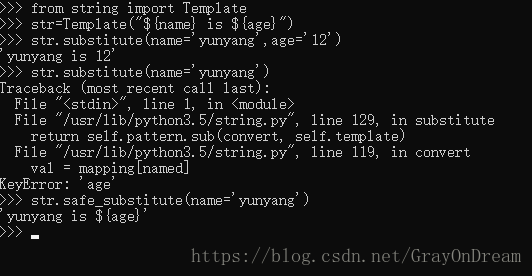
string 提供了一个灵活多变的模版类 Template ,使用它最终用户可以用简单的进行编辑。这使用户可以在不进行改变的情况下定制他们的应用程序。格式使用 为开头的Python合法标识(数字、字母和下划线)作为占位符。占位符外面的大括号使它可以和其它的字符不加空格混在一起。 为 开 头 的 P y t h o n 合 法 标 识 ( 数 字 、 字 母 和 下 划 线 ) 作 为 占 位 符 。 占 位 符 外 面 的 大 括 号 使 它 可 以 和 其 它 的 字 符 不 加 空 格 混 在 一 起 。 创建一个单独的 创 建 一 个 单 独 的 。
当一个占位符在字典或关键字参数中没有被提供时,substitute() 方法就会抛出一个 KeyError 异常。 对于邮件合并风格的应用程序,用户提供的数据可能并不完整,这时使用 safe_substitute() 方法可能更适合 — 如果数据不完整,它就不会改变占位符。
模板子类可以指定一个自定义分隔符。
演示图片:
(14)、使用二进制数据记录布局
struct 模块为使用变长的二进制记录格式提供了 pack() 和 unpack() 函数。下面的示例演示了在不使用 zipfile 模块的情况下如何迭代一个 ZIP 文件的头信息。压缩码 “H” 和 “I” 分别表示2和4字节无符号数字, “<” 表明它们都是标准大小并且按照 little-endian 字节排序。
(15)、多线程
多线程应用程序的主要挑战是协调线程,诸如线程间共享数据或其它资源。为了达到那个目的,线程模块提供了许多同步化的原生支持,包括:锁,事件,条件变量和信号灯。
尽管这些工具很强大,微小的设计错误也可能造成难以挽回的故障。因此,任务协调的首选方法是把对一个资源的所有访问集中在一个单独的线程中,然后使用 queue 模块用那个线程服务其他线程的请求。为内部线程通信和协调而使用 Queue 对象的应用程序更易于设计,更可读,并且更可靠。
演示图片,数字太小效果不明显可以自己修改:

(16)、日志
logging 模块提供了完整和灵活的日志系统。它最简单的用法是记录信息并发送到一个文件或 sys.stderr。
默认情况下捕获信息和调试消息并将输出发送到标准错误流。其它可选的路由信息方式通过 email,数据报文,socket 或者 HTTP Server。基于消息属性,新的过滤器可以选择不同的路由: DEBUG, INFO, WARNING, ERROR 和 CRITICAL 。日志系统可以直接在 Python 代码中定制,也可以不经过应用程序直接在一个用户可编辑的配置文件中加载。
演示代码:

(17)、列表工具
很多数据结构可能会用到内置列表类型。然而,有时可能需要不同性能代价的实现。array 模块提供了一个类似列表的 array() 对象,它仅仅是存储数据,更为紧凑
collections 模块提供了类似列表的 deque() 对象,它从左边添加(append)和弹出(pop)更快,但是在内部查询更慢。这些对象更适用于队列实现和广度优先的树搜索。
除了链表的替代实现,该库还提供了 bisect 这样的模块以操作存储链表。
heapq 提供了基于正规链表的堆实现。最小的值总是保持在 0 点。这在希望循环访问最小元素但是不想执行完整堆排序的时候非常有用。
演示图片:
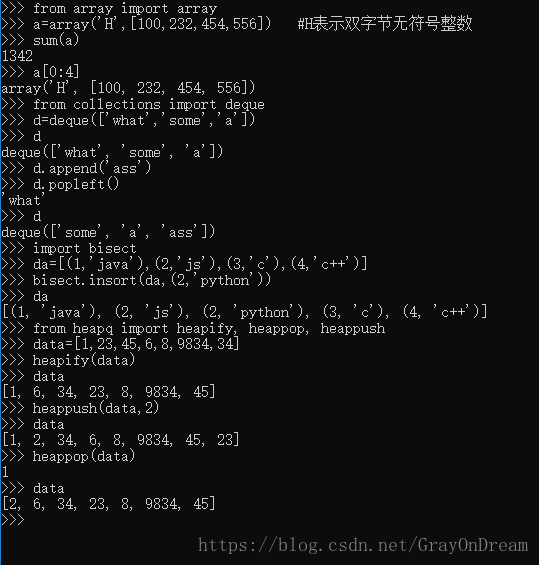
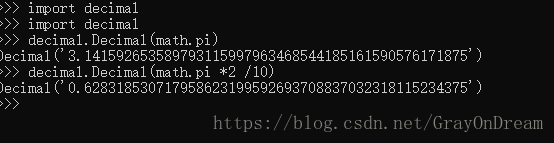
(18)、十进制浮点数算法
decimal 模块提供了一个 Decimal 数据类型用于浮点数计算。相比内置的二进制浮点数实现 float,这个类型有助于:
金融应用和其它需要精确十进制表达的场合,
控制精度,
控制舍入以适应法律或者规定要求,
确保十进制数位精度,
用户希望计算结果与手算相符的场合。
Decimal 的结果总是保有结尾的 0,自动从两位精度延伸到4位。Decimal 重现了手工的数学运算,这就确保了二进制浮点数无法精确保有的数据精度。高精度使 Decimal 可以执行二进制浮点数无法进行的模运算和等值测试。
演示图片:
8、虚拟环境和包
Python 应用程序经常会使用一些不属于标准库的包和模块。应用程序有时候需要某个特定版本的库,因为它需要一个特定的 bug 已得到修复的库或者它是使用了一个过时版本的库的接口编写的。
Python可以创建一个虚拟环境(通常简称为 “virtualenv”),包含一个特定版本的 Python,以及一些附加的包的独立的目录树。不同的应用程序可以使用不同的虚拟环境。
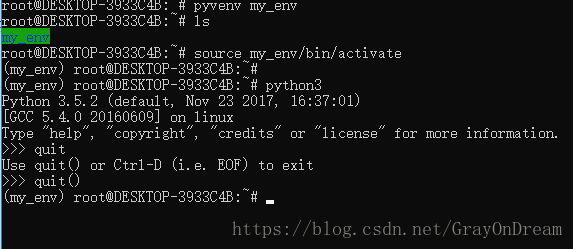
(1)、创建虚拟环境
用于创建和管理虚拟环境的脚本叫做 pyvenv。pyvenv 通常会安装你可用的 Python 中最新的版本。这个脚本也能指定安装一个特定的版本的 Python,因此如果在你的系统中有多个版本的 Python 的话,你可以运行 pyvenv-3.5 或者你想要的任何版本来选择一个指定的 Python 版本。
要创建一个 virtualenv,首先决定一个你想要存放的目录接着运行 pyvenv 后面携带着目录名,如果目录不存在则会自动创建目录,并且也在目录里面创建一个包含 Python 解释器,标准库,以及各种配套文件的 Python “副本”。
pyvenv my_env 一旦你已经创建了一个虚拟环境,你必须激活它。
Windows上运行:
my_env/Scripts/activateUnix类系统运行
source my_env/bin/activate 激活了虚拟环境会改变你的 shell 提示符,显示你正在使用的虚拟环境,并且修改了环境以致运行 python 将会让你得到了特定的 Python 版本。
演示图片:
(2)、使用 pip 管理包
一旦你激活了一个虚拟环境,可以使用一个叫做 pip 程序来安装,升级以及删除包。默认情况下 pip 将会从 Python Package Index, 中安装包。你可以通过 web 浏览器浏览它们,或者你也能使用 pip 有限的搜索功能
pip 有许多子命令:search,install,uninstall,freeze等。可以使用pip install --upgrade升级包。pip show 将会显示一个指定的包的信息:
pip list 将会列出所有安装在虚拟环境中的包:
pip freeze 将会生成一个类似需要安装的包的列表,但是输出采用了 pip install 期望的格式。常见的做法就是把它们放在一个 requirements.txt 文件。
安装包演示,其他类似:
9、浮点数问题
(1)、浮点数精度
跟大多数语言一样由于机器硬件的限制浮点数能够保存的精度是有限的,浮点数的格式有很多标准,目前IEEE提供了754标准来规定硬件中小数的保存方式。因此你计算过程中得到的小数全是近似的,不可能完全等于理论上的计算结果。但是一般情况编程语言提供的精度是足够使用的。
通常可以使用自定义格式化来修饰浮点数。
对于需要精确十进制表示的情况,可以尝试使用 decimal 模块,它实现的十进制运算适合会计方面的应用和高精度要求的应用。
fractions 模块支持另外一种形式的运算,它实现的运算基于有理数(因此像1/3这样的数字可以精确地表示)。如果你是浮点数操作的重度使用者,你应该看一下由 SciPy 项目提供的 Numerical Python 包和其它用于数学和统计学的包。
float.as_integer_ratio() 方法以分数的形式表示一个浮点数的值:
float.hex() 方法以十六进制表示浮点数,给出的同样是计算机存储的精确值:
因为可以精确表示,所以可以用在不同版本的 Python(与平台相关)之间可靠地移植数据以及与支持同样格式的其它语言(例如 Java 和 C99)交换数据。
另外一个有用的工具是 math.fsum() 函数,它帮助求和过程中减少精度的损失。当数值在不停地相加的时候,它会跟踪“丢弃的数字”。这可以给总体的准确度带来不同,以至于错误不会累积到影响最终结果的点。
演示图片:
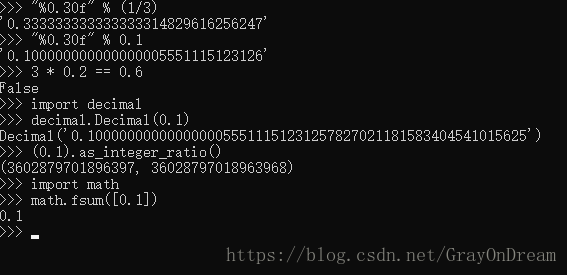
(2)、表达错误
1/10 不能精确的表示为二进制小数。大多数今天的机器(2000年十一月)使用 IEEE-754 浮点数算法,大多数平台上 Python 将浮点数映射为 IEEE-754 “双精度浮点数”。754 双精度包含 53 位精度,所以计算机努力将输入的 0.1 转为 J/2**N 最接近的二进制小数。J 是一个 53 位的整数。
10、附录
(1)、错误处理
当错误发生时,解释器打印一个错误信息和堆栈跟踪。在交互模式下,它返回主提示符;当输入来自文件的时候,在打印堆栈跟踪后以非零退出(a nonzero exit)状态退出。(在 try 声明中被 except 子句捕捉到的异常在这种情况下不是错误。)有些错误是非常致命的会导致一个非零状态的退出;这也适用于内部错误以及某些情况的内存耗尽。所有的错误信息都写入到标准错误流;来自执行的命令的普通输出写入到标准输出。
输入中断符(通常是 Control-C 或者 DEL)到主或者从提示符中会取消输入并且返回到主提示。[1] 当命令执行中输入中断符会引起 KeyboardInterrupt 异常,这个异常能够被一个 try 声明处理。
(2)、可执行 Python 脚本
在 BSD’ish Unix 系统上,Python 脚本可直接执行,像 shell 脚本一样,只需要把下面内容加入到:
#!/usr/bin/env python3.5 (假设 python 解释器在用户的 PATH 中)脚本的开头,并给予该文件的可执行模式。#! 必须是文件的头两个字符。在一些系统上,第一行必须以 Unix-style 的行结束符(’\n’)结束,不能以 Windows 的行结束符(’\r\n’)。 注意 ‘#’ 在 Python 中是用于注释的。使用 chmod 命令能够给予脚本执行模式或者权限。
在 Windows 系统上,没有一个 “可执行模式” 的概念。Python 安装器会自动地把 .py 文件和 python.exe 关联起来,因此双击 Python 将会把它当成一个脚本运行。文件扩展名也可以是 .pyw,在这种情况下,运行时不会出现控制台窗口。
(3)、交互式启动文件
当你使用交互式 Python 的时候,它常常很方便地执行一些命令在每次解释器启动时。你可以这样做:设置一个名为 PYTHONSTARTUP 的环境变量为包含你的启动命令的文件名。这跟 Unix shells 的 .profile 特点有些类似。
这个文件在交互式会话中是只读的,在当 Python 从脚本中读取命令,以及在当 /dev/tty 被作为明确的命令源的时候不只是可读的。该文件在交互式命令被执行的时候在相同的命名空间中能够被执行,因此在交互式会话中定义或者导入的对象能够无需授权就能使用。你也能在文件中更改提示 sys.ps1 和 sys.ps2。
如果你想要从当前目录中读取一个附加的启动文件,你可以在全局启动文件中编写代码像这样:if os.path.isfile(‘.pythonrc.py’): exec(open(‘.pythonrc.py’).read())。如果你想要在脚本中使用启动文件的话,你必须在脚本中明确要这么做:
import os
filename = os.environ.get('PYTHONSTARTUP')
if filename and os.path.isfile(filename):
with open(filename) as fobj:
startup_file = fobj.read()
exec(startup_file) Python 提供两个钩子为了让你们定制 sitecustomize 和 usercustomize。为了看看它的工作机制的话,你必须首先找到你的用户 site-packages 目录的位置。启动 Python 并且运行这段代码:
现在你可以创建一个名为 usercustomize.py 的文件在你的用户 site-packages 目录,并且在里面放置你想要的任何内容。它会影响 Python 的每一次调用,除非它以 -s (禁用自动导入)选项启动。
import site
site.getusersitepackages()sitecustomize 以同样地方式工作,但是通常由是机器的管理员创建在全局的 site-packages 目录中,并且是在 usercustomize 之前导入。