LiteFlowNet: A Lightweight Convolutional Neural Network for Optical Flow Estimation
Abstract
flownet效果好,但是需要160M的参数。创新点:1.使得前向传播预测光流更为效率通过在每一个金字塔层添加一个串联网络。2.添加一个novel flow regularization layer来改善异常值和模糊边界的情况,这个层是通过使用feature-driven local convolution来实现的。3.我们的网络拥有一个有效的金字塔特征提取结构,并采用feature warping而不是像FlowNet2中所做的image warping。
1. Introduction
光流估计是计算机视觉中的一个长期存在的问题。因为众所周知的孔径问题,光流无法被直接测量。因此,常规的解决方法为:在由粗到细的框架中通过能量最小化来求解[![]() ]。然而,基于此的光流计算技术因其复杂的能量优化问题,无法用于实时的应用中。
]。然而,基于此的光流计算技术因其复杂的能量优化问题,无法用于实时的应用中。
FlowNet以及Flownet2为使用卷积神经预测光流场奠定了基础,尤其是flownet2已经达到了传统变分法的精度,然而运行速度却提升了多个数量级。为了提高精度,flownet2使用多个flownet模型进行级联,每个级联中的flownet模型通过处理第一张图与变形之后第二张图之间增量来改善上一层的光流场。因此,flownet2中包含大约160m的参数,对于移动客户端来说,存储异常困难。SPyNet通过对金字塔层中的图片进行变形,使得网络的参数缩减到1.2m。然而损失了精度,只达到flownet的精度。
3. LiteFlowNet
LiteFlowNet由两个紧凑的子网络组成,它们专门用于金字塔特征提取和光流估计
NetC: transforms any given image pair into two pyramids of multi-scale high-dimensional features
NetE :consists of cascaded flow inference and regularization modules that estimate coarse-to-fine flow fields.
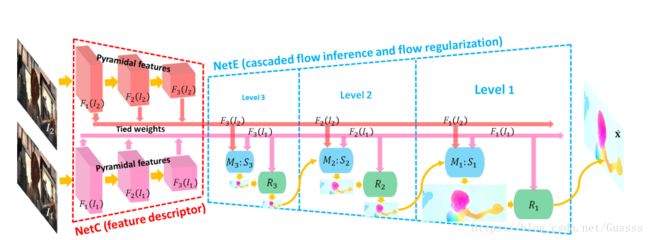
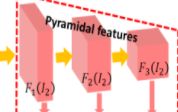
Pyramidal Feature Extraction:NETC为一个两输入的网络,两个网络共享滤波器权重。这两个网络的作用类似于特征描述符(feature descriptor),把一张图片![]() 转换成一个pyramid of multi-scale high-dimensional features
转换成一个pyramid of multi-scale high-dimensional features![]() ,从k=1为全分辨率,到k=L的最低分辨率。以下图整个为一个pyramid of multi-scale high-dimensional feature。以后为了方便,使用
,从k=1为全分辨率,到k=L的最低分辨率。以下图整个为一个pyramid of multi-scale high-dimensional feature。以后为了方便,使用![]() 来表示图片
来表示图片![]() 的CNN特征,省略下标k,当讨论对于一个 pyramid level(例如
的CNN特征,省略下标k,当讨论对于一个 pyramid level(例如![]() )的操作时,所有的 pyramid level都应用于相同的操作。
)的操作时,所有的 pyramid level都应用于相同的操作。
Feature Warping:可以使用warp操作来解决大位移问题(传统方法中应用warp的有:6,20,CNN方法有14,21)。本文提出使用feature warping (f-warp)来减少两个特征![]() ,
,![]() 之间的feature-space distance用来处理大位移情况。
之间的feature-space distance用来处理大位移情况。![]() 被warp成
被warp成 ![]()
![]() 为光流估计结果。这使得网络能够检测出
为光流估计结果。这使得网络能够检测出![]() 与
与![]() 之间小幅度的residual flow,而不是非常难预测的整幅图的光流场。和传统方法不同的是,f-warp应用于高阶CNN特征之中,而非图片中。这使得网络预测光流的能力大大加强。
之间小幅度的residual flow,而不是非常难预测的整幅图的光流场。和传统方法不同的是,f-warp应用于高阶CNN特征之中,而非图片中。这使得网络预测光流的能力大大加强。
为了使得训练能够端到端的训练,![]() 被插值成
被插值成![]() ,如下没懂
,如下没懂
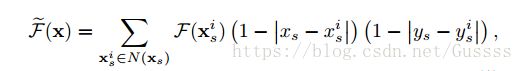
3.1. Cascaded Flow Inference
At each pyramid level of NetE(例如![]() 这一pyramid level),高阶特征的逐像素的匹配会产生粗略的光流,紧接着对于此粗略的光流进行一次refinement,可以把此粗略光流的精度提升至sub-pixel级的精度。
这一pyramid level),高阶特征的逐像素的匹配会产生粗略的光流,紧接着对于此粗略的光流进行一次refinement,可以把此粗略光流的精度提升至sub-pixel级的精度。
First Flow Inference (descriptor matching).图片![]() 与
与![]() 之间的Point correspondence是通过计算pyramidal features
之间的Point correspondence是通过计算pyramidal features![]() 与
与![]() 中的高阶特征向量的联系来建立的。
中的高阶特征向量的联系来建立的。
![]()
以下为公式的解释:

有三种方法来减少cost volume过程中的计算负担,
- We perform short-range matching at every pyramid level instead of longrange matching at a single level.
- We reduce feature-space distance between F1 and F2 by warping F2 towards F1 using our proposed f-warp through flow estimate
 from previous level.对于来说,还需要进行预处理。如下
from previous level.对于来说,还需要进行预处理。如下 
- We perform matching only at the sampled positions in the pyramid levels of high-spatial resolution. The sparse cost volume is interpolated in the spatial dimension to fill the missed matching costs for the unsampled positions.
前两种技术有效减少了所需的搜索空间,第三种技术减少了frequency of matching per pyramid level。
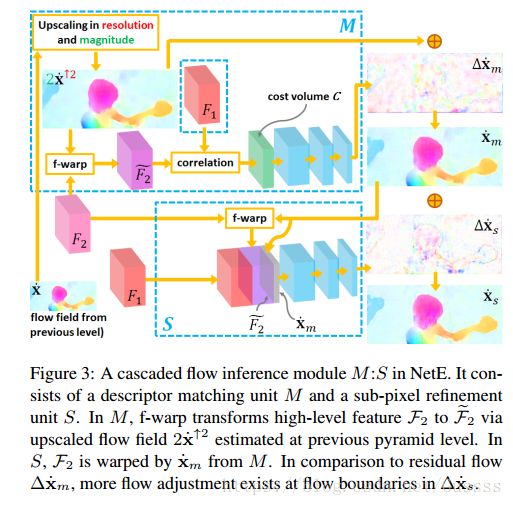
Second Flow Inference (sub-pixel refinement).在M(指的是descriptor matching unit )中,cost volume是通过一个像素一个像素的衡量correlation的方式来聚集的。来自M的![]() 的精度只达到pixel-level的精度,引入第二个 flow inference,目的为把
的精度只达到pixel-level的精度,引入第二个 flow inference,目的为把![]() refine到sub-pixel级的精度。这可以防止错误的光流被向上采样放大并传递到下一个pyramid level。
refine到sub-pixel级的精度。这可以防止错误的光流被向上采样放大并传递到下一个pyramid level。
3.2. Flow Regularization
上文中的Cascaded flow inference类似于传统方法中的data fidelity的作用。只用data fidelity项的化,也是就只使用Cascaded flow inference,会造成边界模糊,以及在光流场中不希望见到的artifacts(类似于干扰,详见http://tieba.baidu.com/p/3642644125)。为此,使用a feature-driven local convolution(f-lcon)技术来对cascaded flow inference阶段产生的光流场进行正则。相比于local convolution,feature-driven local convolution的通用性更好。体现在不仅为feature map的每个位置都使用了一个不同的过滤器,而且为每个flow patch自适应地构造了过滤器
需要正则的F是一个vector-valued feature,有C个通道,spatial dimension为MXN,定义一个滤波器组![]() 用于f-lcon layer.运算可以定义成如下
用于f-lcon layer.运算可以定义成如下
![]()
以下为公式解释

如果需要把上次层的光流场进行正则,只需要把F改为![]() ,Flow regularization module R被定义成如下形式
,Flow regularization module R被定义成如下形式
![]()
f-lcon 滤波器的作用为平滑光流场,假如光流场在一个小块中是平滑的那么这个滤波器就相当于中值滤波器,同时不能过度平滑图像的边缘。
定义一个a feature-driven CNN distance metric D,用来评估局部的光流变化,使用如下输入量

综上,D可以被自适应的通过一个CNN单元![]() 来构建,如下
来构建,如下
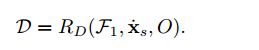
每一个滤波器的定义如下
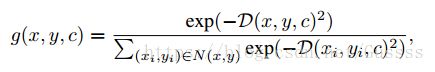
以下为参数说明
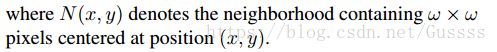
可以通过技巧来使得f-lcon计算变得更有效率,对于一个有C通道的F,使用C个tensors![]() 来存储f-lcon滤波器G,每一个f-lcon filter滤波器
来存储f-lcon滤波器G,每一个f-lcon filter滤波器![]() 转换成一个
转换成一个![]() ,然后装入
,然后装入![]()
需要正则的光流tensor(用F来表示)也做如上的变换,也就是取一个通道中滤波器对应大小的块,然后这一块转换成![]() ,这个通道中所有的块都进行这样的操作。转换成
,这个通道中所有的块都进行这样的操作。转换成![]() , 最好可以把
, 最好可以把![]() 改写为如下。
改写为如下。
![]()
以下为公式解释
![]()
Experiments
Network Details:在liteflownet中,NetC产生6-level pyramidal features(也就是一个pyramidal feature,里面有6个层级,也就是6层),NetE为level6~2预测光流场。level2中的光流场被上采样来产生level中的光流场。
在levels 6 to 4中,设置cost volume中的最大搜索半径为3pixel,
在levels 3 to 2中:设置cost volume中的最大搜索半径为6pixel
除了levels 3 to 2使用a stride of 2的采样,对其他level中的每一个位置都进行匹配(可能设置stride=1)
除了在 descriptor matching M,sub-pixel refinement S,以及flow regularization R units中的最后一层使用5×5 (levels 4 to 3) 或 7×7 (level 2) filters,其他的都使用3X3的滤波器。
5. Conclusion
为了解决大位移现象以及细节保护,LiteFlowNet使用了 short-range matching来产生pixel-level的光流场并进一步改善至sub-pixel。为了产生清晰的边界,LiteFlowNet使用feature-driven local convolution (f-lcon)来正则化光流场。