Redis学习(6)——压缩列表(ziplist)
今天学习Redis的压缩列表(ziplist),看着书上写的:压缩表是列表键和哈希键的底层实现之一。于是自己就在Redis上试了一下,可是在测试列表键的时候却发现查看属性,发现不是“ziplist”而是“qucklist”,于是自己又试了不同的小整数和短字符串,发现都是“qucklist”实现的。查询后才知道,Redis已经将3.2之后的版本的列表的底层实现由qucklist实现,取代了曾经的ziplist和linkedlist。这里推荐一个关于qucklist的博文:https://blog.csdn.net/harleylau/article/details/80534159
如图:

一,压缩列表
压缩表(ziplist)是列表键(3.2之前的版本)和哈希键的底层实现之一。
作为哈希键的实现底层条件:当一个哈希键只包含少量的键值对,并且每个键值对的键和值要么是小整数数值要么就是长度较短的字符串时,Redis就会使用压缩列表来作为哈希键的底层实现。
压缩列表是Redis为了节约内存而开发的,由一系列特殊编码的连续内存块组成的顺序型数据结构。一个压缩列表可以包含任意多个节点(entry),每个节点保存一个字节数组或者一个整数值。
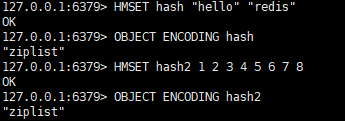
二,压缩列表的构成及源码
1)成员属性定义源码(源码来自自己关注的一个大神博主,他对Redis进行了很多的源码解析和注释。附上他的传送门:https://blog.csdn.net/men_wen/article/details/75668345)
/* Utility macros */
// ziplist的成员宏定义
// (*((uint32_t*)(zl))) 先对char *类型的zl进行强制类型转换成uint32_t *类型,
// 然后在用*运算符进行取内容运算,此时zl能访问的内存大小为4个字节。
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
//将zl定位到前4个字节的bytes成员,记录这整个压缩列表的内存字节数
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
//将zl定位到4字节到8字节的offset成员,记录着压缩列表尾节点距离列表的起始地址的偏移字节量
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
//将zl定位到8字节到10字节的length成员,记录着压缩列表的节点数量
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
//压缩列表表头(以上三个属性)的大小10个字节
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
//返回压缩列表首节点的地址
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
//返回压缩列表尾节点的地址
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
//返回end成员的地址,一个字节。
/* We know a positive increment can only be 1 because entries can only be
* pushed one at a time. */
#define ZIPLIST_INCR_LENGTH(zl,incr) { \ //增加节点数 \
if (ZIPLIST_LENGTH(zl) < UINT16_MAX) \ //如果当前节点数小于65535,那么给length成员加incr个节点 \
ZIPLIST_LENGTH(zl) = intrev16ifbe(intrev16ifbe(ZIPLIST_LENGTH(zl))+incr); \
}
2)图示:
3)压缩列表的部分组成成员:压缩列表没有使用结构体,而是采用的对成员宏定义。
| 属性 | 类型 | 长度/字节 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4 | 记录整个压缩列表占用的内存字节数,在对压缩列表进行内存重分配或者计算zlend的位置时使用。 |
| zltail_offset | uint32_t | 4 | 记录压缩列表尾节点距离压缩列表起始地址有多少个字节,通过这个偏移量,程序可以直接获得压缩列表的表尾节点地址 |
| zllength | uint16_t | 2 | 记录了压缩列表的节点数量。当这个属性的值小于65535时(即:小于UINT16_MAX),这个属性的值就是压缩列表的节点数量,但是当这个值等于UINT16_MAX时,需要遍历整个压缩列表才能获得其节点数量 |
| entryX | 列表节点 | 不定 | 压缩表的各个节点,X代表数量不定 |
| zlend | uint8_t | 1 | 特殊常数值(OxFF,也就是255)。用于标记压缩列表的末端。
|
4)创建一个空的压缩列表源码:
/* Create a new empty ziplist. */
//创建并返回一个新的压缩列表
unsigned char *ziplistNew(void) {
//ZIPLIST_HEADER_SIZE是压缩列表的表头大小,1字节是末端的end大小
unsigned int bytes = ZIPLIST_HEADER_SIZE+1;
unsigned char *zl = zmalloc(bytes); //为表头和表尾end成员分配空间
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes); //将bytes成员初始化为bytes
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE); //空列表的offset成员为表头大小
ZIPLIST_LENGTH(zl) = 0; //节点数量为0
zl[bytes-1] = ZIP_END; //将表尾end成员设置成默认的255
return zl;
} 三,压缩列表的指针移动和解析

1)属性zlbytes的大小为0x50,表示压缩列表为80字节大小。
2)属性zltail_offset的大小为0x3c,表示起始地址指针p加上这个偏移量0xff,就能计算到到表尾地址。
3)zllength表示含有4个节点。
四,压缩列表的节点以及节点的成员
Redis为压缩列表定义了一个zlentry结构来管理节点的信息。
//压缩列表节点信息的结构
typedef struct zlentry {
//prevrawlen 前驱节点的长度
//prevrawlensize 编码前驱节点的长度prevrawlen所需要的字节大小
unsigned int prevrawlensize, prevrawlen;
//len 当前节点值长度
//lensize 编码当前节点长度len所需的字节数
unsigned int lensize, len;
//当前节点header的大小 = lensize + prevrawlensize
unsigned int headersize;
//当前节点的编码格式
unsigned char encoding;
//指向当前节点的指针,以char *类型保存
unsigned char *p;
} zlentry; 但是由于使用这个结构来实现存储小整数和短字符串,浪费空间,不符合设计初衷:节约内存。于是Redis在压缩列表的实现中定义了一些成员来实现节约内存的这个目的。
因此每个压缩列表节点又由prev_entry_length,encoding,content三个部分组成。
(一)prev_entry_length
prev_entry_length就是zlentry中的prevrawlensize和prevrawlen两个成员的整合。
- prevrawlen:前驱节点的长度
- prevrawlensize:编码前驱节点prevrawlen值所需要的字节数
这两个构成的prev_entry_length以字节为单位,记录了压缩列表中前一个节点的长度,prev_entry_length可以是一个字节也可以是五个字节。
- 当前驱节点长度小于254字节,那么prev_entry_length属性的长度为1字节(前驱节点的长度大小值保存在这里面)
- 当前驱节点的长度大于或等于254字节,那么prev_entry_length属性的长度为5字节来保存前驱节点的长度值。
由于节点的prev_entry_length属性记录了前驱节点的长度,所以程序便可以通过指针来由当前节点的起始地址值和prev_entry_length属性计算出前驱节点的起始地址。
(二)encoding
像prev_entry_length一样,encoding也是zlentry中成员lensize和len的一个整合。
- len:当前节点值长度
- lensize:编码当前节点长度len所需的字节数
节点的encoding属性记录了节点content属性所保存的数据的类型和长度。
- 1字节、2字节或5字节,值的最高位为00,01或者10的字节数组编码,这种编码表示content属性保存着字节数组,数组的长度由编码除去最高两位后的其他位记录。
- 1字节,值的最高位为11开头的整数编码。这种编码表示content属性保存着整数值,整数值的长度由编码除去最高两位后的其他位记录。
(三)content
节点的content属性赋值保存节点的值,节点值可以是一个字节数组或者一个整数值。值的类型和长度由encoding来决定。
五,连锁更新
在前面的介绍中prev_entry_length可以是一个字节也可以是五个字节。
- 当前驱节点长度小于254字节,那么prev_entry_length属性的长度为1字节(前驱节点的长度大小值保存在这里面)
- 当前驱节点的长度大于或等于254字节,那么prev_entry_length属性的长度为5字节来保存前驱节点的长度值。
但是这里有一个特殊情景:
这里有X个连续的节点的长度介于250-253字节

这时,节点entry1—X大小都小于254,记录前一个节点的长度的prev_entry_length只需要一个字节,若这时在entry1前添加一个大小为
新节点New_entry,它的长度大于或等于254字节。这时用entry1的prev_entry_length属性记录New_entry的长度,但是由于entry1的prev_entry_length属性只有1个字节,没法记录New_entry的长度,就需要将entry1的prev_entry_length扩展为5个字节。这就会使得原本长度为250到253字节的entry1变为大于或等于254字节,使得entry2也需要扩展prev_entry_length属性为5字节,从而引发entry3直达entryX的prev_entry_length属性的改变。这就是Redis压缩列表的连锁更新。连锁更新最坏复杂度为O(n^2)(由于扩展空间最坏复杂度为O(n),n次的空间分配)
在实际中连锁更新这种会造成性能降低的情况很少见(最坏的情况是整个压缩列表的节点长度全是在250—253,这种情况本来就会比较少见。一般情况,几个节点的长度在250—253,当到最后一个长度在250-253的节点时,后面的节点小于250扩展了prev_entry_length属性为5个字节长度不会超过254字节,也不会影响它的下一个节点的prev_entry_length存储),因此对Redis的性能影响很小。