【论文解读】 FPGA实现卷积神经网络CNN(一): CNP: AN FPGA-BASED PROCESSOR FOR CONVOLUTIONAL NETWORKS
博主评论:目前在移动端部署深度学习推断的需求越来越多,博主认为这类需求属于边缘计算的一部分,目前移动端的主要方式有嵌入式ARM,NPU,FPGA等,然而早在2009年,在卷积神经网络之父Yann LeCun挂名的一篇论文里就提出了使用FPGA实现卷积神经网络推断,考察卷积神经网络并行性,并结合FPGA的高并行计算,对人脸检测达到了每秒十帧的速度,虽然现在网络复杂度变高,但同时FPGA计算能力也在提高,论文里面的实现思路完全可以借鉴,论文解读如下(文章不重要的部分有省略)
目录
摘要:
1. INTRODUCTION
2. ARCHITECTURE
2.1. Hardware
2.2. Software
3. APPLICATION TO FACE DETECTION
4. RESULTS
Speed
5. CONCLUSIONS, FUTURE WORK
摘要:
本文介绍了一个在面向低端DSP的高效实现ConvNets现场可编程门阵列(FPGA)。利用ConvNets的固有并行性并充分利用硬件FPGA上单元的多重累积。整个系统使用一个单个FPGA带有外部存储器模块,没有额外的功能部分。实施了ConvNet人脸检测系统并测试过。在512*384帧上进行人脸检测需要100毫秒(每秒10帧),相当于平均每秒![]() 个连接的性能(这里的连接换成计算量应该是6.8Gops/s )。设计可以用于低功率,轻量级嵌入式视觉系统,用于微型无人机和其他小型机器人。
个连接的性能(这里的连接换成计算量应该是6.8Gops/s )。设计可以用于低功率,轻量级嵌入式视觉系统,用于微型无人机和其他小型机器人。
1. INTRODUCTION
介绍嵌入式视觉系统应用前景,包括本文设计系统的简单介绍:FPGA系统功耗小于15W, 是专门针对卷积网络的,但也可用于许多类似的架构基于本地过滤器组和分类器,如HMAX和HoG方法。现代DSP-oriented fpga包括大量的硬连接乘法累加可以大大加快计算密集型操作的单元。本文介绍的系统充分利用了卷积的高度并行性,采用现代面向dsp的fpga,提供了高并行度的ConvNet操作。
2. ARCHITECTURE
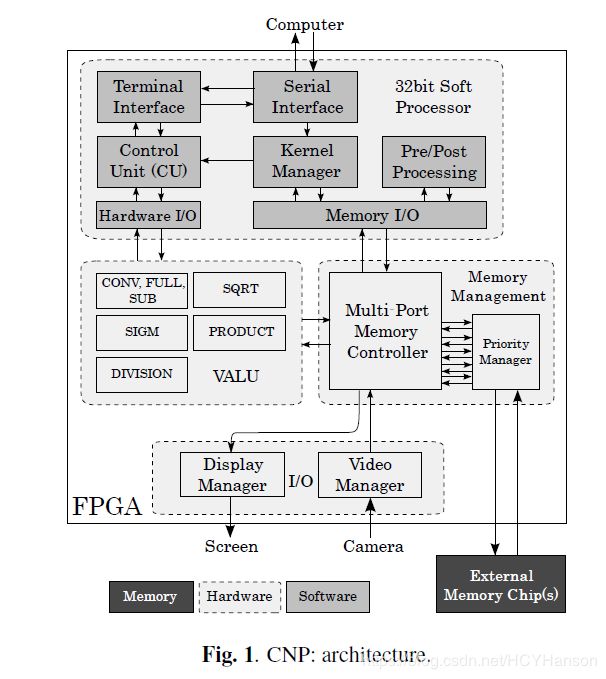
图1显示了系统的功能体系结构。整个系统只适用于一个FPGA,需要一个外部存储模块。设计采用两种不同的平台实现:低端Xilinx Spartan-3A DSP 3400 FPGA与DDR-SDRAM模块(来自Xilinx的开发板)耦合,高端Xilinx Virtex-4 SX35与一对QDR-SRAM芯片(定制设计)耦合。fpga都有大致相同的密度(53000斯巴达式的逻辑单元,Virtex - 34000),主要区别在内置硬件乘法器的数量(前后者分别为126和192),和他们可以操作的速度(250 mhz前者,后者450 mhz)。另一个主要区别是外部内存的带宽:开发板为1GB/s,定制设计为7.2GB/s。内置的定点乘法器使用18位输入,累积在48位上。
2.1. Hardware
CNP包含一个控制单元(CU)、一个并行/流水线向量算术和逻辑单元(VALU)、一个I/O控制单元和一个内存接口。
内存接口是系统的关键部分。它的主要目的是通过透明地允许对同一内存位置的多个并发访问来实现并行化。设计了一种专用的硬件仲裁器,通过提供8个可以同时读写内存的端口来多路/多路访问外部内存芯片。它的启发式非常简单:它将某个端口连接到外部内存,并估计其带宽来分配某个时间片,然后在到达该计算时间片时切换到下一个端口。通过这种方式,系统的不同部分可以同时访问外部内存(例如,数据从/到VALU、摄像头、显示器等)。为了确保每个端口上数据流的连续性,在两个方向都使用了fifo。这些fifo的深度决定了每个端口的最大时间片。
第二个关键组成部分是CNP的VALU单元。ConvNet的所有基本操作都在硬件级实现,并作为宏指令提供。这些宏指令可以按任何顺序执行。它们的排序由CPU在软件级管理。该体系结构结合了硬件的效率和软件的灵活性。
这个系统的主要与硬件相关的macro-instructions是:(1)多个二维卷积乘累加, (2) 2D空间池化和下抽样,使用max/均值滤波器,(3)平面矩阵与向量的点积 (4)逐点非线性映射(目前一个近似的双曲正切 sigmoid函数)。VALU包含预处理图像所需的其他指令(除法、平方根、乘积)。整个指令集是向量的,并正确地流水线计算这些指令中的任何一条在线性时间内输入大小。
当运行一个ConvNet时,大部分工作都涉及到2D卷积。因此,系统的效率在很大程度上取决于卷积硬件的效率。我们的2D卷积器,如图2所示,并包含一个后积累,以允许多个卷积的组合。它在一个时钟周期内执行以下基本操作

其中![]() 是输入平面中的值,
是输入平面中的值,![]() 是K*K卷积核中的值,
是K*K卷积核中的值,![]() 是平面上的一个值与结果相结合,
是平面上的一个值与结果相结合,![]() 为输出平面的值。
为输出平面的值。
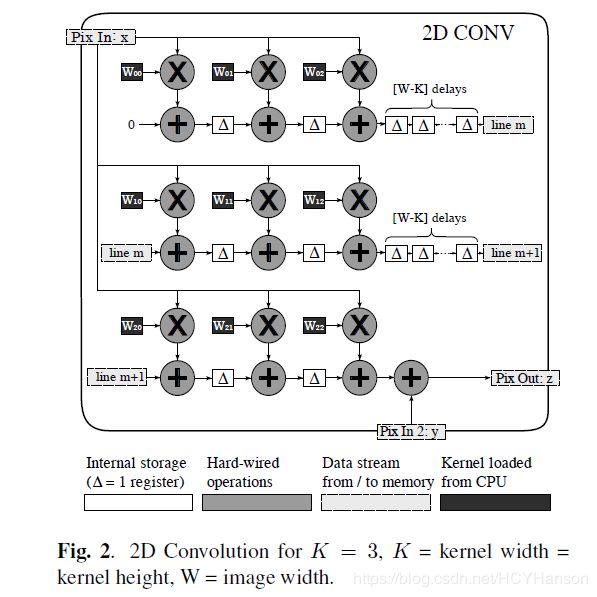
将输入平面的值放入芯片上的K个FIFOs中,其大小为图像的宽度减去内核的宽度。这些fifo中的值的移动对应于在输入平面上移动卷积窗口。在每个时钟周期中,值都会移动1,并行计算输入平面窗口和内核之间的点积。换句话说,在每个时钟周期,卷积器同时执行K*K次乘积累操作(加上临时平面Y的积累)。因此,卷积运算所使用的总的时钟周期数目等于输出平面的值的个数,加上填充输入平面所需的延迟fifo(大致等于输入平面的宽度乘以核的高度)。执行所有算术运算用16位定点精度核系数,and 8-bit for the states(这句话我没有理解,是指输入片面的值吗?),中间积累值存储在FIFOs中的48位上。
用于此实现的低端FPGA有126个乘-积累单位,因此最大平方核大小为11*11,或者两个同时大小为7*7的内核,理论上最大速率为24.5*![]() ,每秒250兆赫的运算速度。然而,我们的实验使用一个单独的7*7卷积器,因为我们目前的应用不需要更大的内核,哪个对应理论最大值为12*
,每秒250兆赫的运算速度。然而,我们的实验使用一个单独的7*7卷积器,因为我们目前的应用不需要更大的内核,哪个对应理论最大值为12*![]() op/s。第二个7*7卷积器将被添加到未来的设计。
op/s。第二个7*7卷积器将被添加到未来的设计。
逐点(point-wise )非线性是双曲正切函数g(x) = a.tanh(B.x)的分段逼近。由于卷积器使用的是硬件乘法器,因此这里实现的目的是避免再使用硬件乘法器,只依赖于加法和移位。该函数由一组线段近似而成,the binary representation of the slopes ![]() has few ones.(很少有斜率
has few ones.(很少有斜率![]() 的二进制表示法?? 也没读太懂)。这允许使用少量的移位和加法来实现乘法。
的二进制表示法?? 也没读太懂)。这允许使用少量的移位和加法来实现乘法。

有了这个约束,sigmoid函数就可以通过两次移位和三次加法来计算。
系统的不同指令对外部内存可以并发访问,在可用带宽足够的情况下允许它们异步工作。
2.2. Software
软CPU为系统增加了一层抽象:软CPU上的程序充当VALU的微程序,允许高度的灵活性。如图1所示,不同的函数在这个处理器上运行。
- 内存I/O:与内存控制器接口的驱动程序。它提供对外部存储器的访问:来自摄像机的图像和ConvNet生成的特征图
- 对象检测应用程序的后处理操作包括非最大抑制、计算活动中心点等硬件中无法方便实现的功能,如格式化计算结果、绘制DVI输出中检测到的对象位置等
- 卷积内核管理器:将卷积内核存储/检索到外部存储器(闪存或SD卡)
- 串行接口:提供从外部系统(如主机)传输数据的方法
- 终端接口:它提供一组命令,用户可以从远程机器发送这些命令来执行、调试或简单地获取结果
- 控制单元,硬件I/O: CNP的控制单元在软件级实现。它用于对指令流进行排序,因此我们要计算的是ConvNet的结构。在软件级别拥有CU提供了尽可能灵活的环境:系统的整个行为可以用一个简单的程序(用C语言)描述
嵌入式软件还控制外部外设,如摄像机(如动态曝光调节)和视频监视器(分辨率、颜色)。
3. APPLICATION TO FACE DETECTION
为了验证该系统,并测试其性能,在CNP平台上搭建了一个基于卷积神经网络的人脸检测系统。基于ConvNets的人脸检测系统在速度和精度上都优于目前流行的Haar小波方法的增强级联。
这一章节下部分面介绍了人脸识别的网络结构以及训练方式,放到现在来看已经不再流行,所以略过。
4. RESULTS
Speed
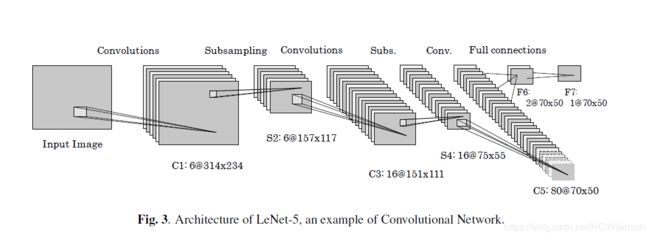
目前的设计可以运行在高达200MHz的fpga。在这个频率下,峰值性能为98亿每秒连接,在实际运行时,平均每秒连接数网络大约40亿次。这两个值之间的差是由于前期/后期处理和数据花费的时间抓取。利用这些计算资源,处理一个完整的512*384灰度图像-使用标准卷积包含5.3亿个连接的网络(如图3)- 100ms,即每秒10帧。这是预计算多分辨率的尺度不变检测系统图像金字塔作为对流网络的输入。计算在单尺度输入上的相同的对流将这个时间减少了1 / 5。在当前实现中对Xilinx进行开发板,外部存储器总线的带宽是有限的(1 gb / s)。由于这个限制,这个系统只能以125MHz运行,产生每秒6帧的速率。使用我们自定义的印刷电路板,带宽没有问题(7.2GB/s),这使得设计很容易达到200 mhz。事实上,随着进一步的优化,系统将很快使用两个同时7*7卷积器,将帧速率增加2倍。
5. CONCLUSIONS, FUTURE WORK
本文提供了一个自包含的高性能实现在一个FPGA上的卷积网络。介绍了该系统在人脸实时检测中的应用。实践证明,该系统是可行的在我们的定制板允许相同的设计全速运行,这要感谢可用的带宽。FPGA就在这个定制的平台上是一款高端产品,而下一步的工作将是什么旨在改进设计,利用其特点:(1)通过实现第二个卷积器允许两个同时进行卷积,(2)通过重新组织CPU接口到VALU,实现一个完全异步的系统,(3)通过允许在VALU中的操作级联。所有这些改进应该提高的整体速度乘以6倍。我们系统的灵活性也将允许我们进行集成新指令向VALU,以扩展CNP的能力。