【论文解读】 FPGA实现卷积神经网络CNN(二): Optimizing FPGA-based Accelerator Design for DCNN
博主评论:这篇论文发表在2015年,是一篇FPGA实现CNN的高引用论文,该文从理论与实践结合展示了在FPGA上实现CNN。根据roofline模型分析计算峰值与CTC rate关系,深入探讨了CNN卷积层中的数据依赖关系,进行数据复用从而在内存带宽不变的情况下提升CTC rate,对不同循环分片参数的performance建模,并为每一层卷积选择通用的分片参数来避免复杂的硬件结构。值得一提的是:该系统的在Xilinx vivado+hls下实现,给出了伪代码,这给复现论文提供了帮助。
目录
摘要:
1,介绍
2, 背景
2.1 CNN 基础
2.2 介绍了经典神经网络AlexNet
2.3 提出roofline模型
3,加速器设计考察
3.1 设计预览
3.2 计算优化
3.3 内存访问优化
3.4 设计空间考察
3.5 多层CNN加速器设计
4,运行细节
4.1 系统概览
4.2 计算引擎
4.3 内存子系统
4.4 外部数据传输引擎
5,实验评估
6,相关工作
7,总结
摘要:
FPGA平台是实现卷积神经网络的利器,但仍有很大的设计提升空间,尤其是在匹配计算量与内存带宽方面,为了克服这个问题,作者提出使用一个 roofline 模型分析设计方案。作者通过各种各样的优化工具(如循环分片和转换)来定量分析了计算量与所需要的内存带宽,在roofline工具的帮助下,使用最少的资源获得了最高的performance。使用VC707FPGA平台在100MHz频率下获得了61.62GFLOPS。
1,介绍
主要介绍了一些前人应用FPGA实现卷积神经网络的例子,在文章作者的实验中,发现在相同的FPGA硬件资源下,采用不同的设计空间方案可以有90%的不同performance。为了有效的考察设计空间,作者在这项工作中提出了一个分析设计方案。该方案的表现好于以往成果的原因有两个,一是:过去的工作只注意计算能力优化,忽视了外部memory操作,并且将加速器直接连到memory,但是作者通过buffer management和bandwidth optimization可以更好的利用FPGA资源;二是:过去的研究通过精巧的数据复用减少了外部数据交换,但是这种方法没有整体最好表现,并且为了不同层的计算需要重新配置FPGA,而作者使用的方法不需要。
文章主要贡献:
1,针对特定CNN算法定量分析了计算量与所需要的内存;
2,在算力和内存带宽的限制下,在设计空间中利用roofline模型验证所有可行的方法;并讨论了如何发现最优方法;
3,提出的CNN加速器:在不同卷积层使用统一的loop unroll因子;
4,作为案例研究,实施的CNN加速器达到61.62 GFLOPS的性能。
2, 背景
2.1 CNN 基础
CNN网络由特征提取器与分类器构成,给出了滑窗法实现卷积运算的伪代码:

2.2 介绍了经典神经网络AlexNet

2.3 提出roofline模型

一个roofline模型是将系统整体performance 与 片外储存器流量(off-chip memory traffic)和 硬件平台可以提供的峰值计算量(peak performance)联系起来。使用float-point performance(GFLOPS)作为输出度量,实际可获得输出如下表示:

Computational Roof:计算资源瓶颈 ; CTC Ratio * BW: 计算to交流比率*带宽 ; (这边CTC Ratio还不是很理解,但两者相乘结果单位应是GFLOPS,其中带宽单位是GFLOPS,在同一个平台上带宽的值是固定的),在图三中可看出algorithm 2比algorithm 1 获得了更好的performance,因为有了更高的CTC Ratio,或者说更好的数据复用。
3,加速器设计考察
针对设计FPGA加速器的一些挑战,提出相一致的考察设计空间优化方法。
3.1 设计预览

加速器主要由计算单元PE(processing-element),片上存储,外部存储,片外/片内内部连接组成。设计加速器有一些挑战,如: 强制对循环使用分块以适应片上的部分数据;PEs和缓存间的内部关系;匹配计算量与片下存储器带宽。
循环展开策略如图:

原始循环(上图) 新循环(下图)

(1)只对R,C,M,N这四个大循环做循环分块,K太小,不用分;
(2)根据循环分块因子计算优化引擎并公式化计算输出performance;
(3)在内部存储使用数据重用减少数据交互流量,根据分块因子公式化计算CTC Ratio;
(4)根据分块因子和CTC Rate(是这两个吗?),考察设计空间提出:计算-内存-访问-匹配-设计(computation-memory-access-matched-design) ;
(5)讨论为多层CNN选择合适的通用加速器。
3.2 计算优化
计算优化的目标是通过有效的循环展开与流水线利用FPGA中的所有计算资源,在这一章假设需要的数据都已经存放在片上存储(BRAM?),3.3节将考虑片下带宽限制。
Loop Unrolling: loop unrolling可以增大计算资源的利用率,在某种程度上当两个同时展开的进程使用共享数据(shared data)时,将会影响生成硬件的复杂性、展开复制(unrolled copies)的次数、硬件运行频率。对于一个已知数组A的特定维度,不同的循环迭代之间数据共享关系可被总结成3类:
(1)不相关(Irrelevant): 如果循环迭代器![]() 不出现在任何访问数组A的函数中,相应的循环维度与数组A也不相关;
不出现在任何访问数组A的函数中,相应的循环维度与数组A也不相关;
(2)独立(Independent):如果在一个数组A中,被访问的数据空间并集在特定循环维度![]() 下是完全可分离的,或者对于任两个不同的参数(循环维度)
下是完全可分离的,或者对于任两个不同的参数(循环维度)![]() ,被DS访问的数据与DS不相交,那么这个循环维度
,被DS访问的数据与DS不相交,那么这个循环维度![]() 与数组A之间是独立的;
与数组A之间是独立的;

(3)依赖(Dependent):如果在一个数组A中,被访问的数据空间并集在特定循环维度![]() 下是不可分离的,则循环维度
下是不可分离的,则循环维度![]() 依赖数组A。
依赖数组A。
三种关系示意图如下:

实际卷积层依赖关系分析:

Loop Pipelining: 循环流水线是hls中增大output的核心优化技术,它在不同的循环迭代中重叠执行操作,片上资源限制和数据依赖(dependence)是限制循环流水线的主要因素。而防止数据携带依赖的方式:基于多面体优化框架【16】,执行自动循环转换,将并行循环放置到最内层(perform automatic loop transformation to permute the parallel loop levels to the innermost levels to avoid loop carried dependence.) 具体实现如下图:
从:

变为:

对于所有数组都展开循环维度too,tii,避免复杂的连接拓扑。too,tii被排列到最内层简化hls代码生成。
code 3 生成的硬件部署图:

Tile Size Selection: 针对特定的循环结构,不同变量确定的不同分片大小也有不同的表现,分片大小![]() 满足如下公式:
满足如下公式:

PEs怎么计算?
由确定的分片大小确定计算峰值(computation roof):

发现计算峰值是![]() 的函数。 执行循环的数目?(number of execution cycles ?)-->为什么这样算??
的函数。 执行循环的数目?(number of execution cycles ?)-->为什么这样算??
3.3 内存访问优化
上面的章节假设所有的数据都已经放在片内BRAM里面了,然而由于片外内存带宽限制,达不到理论上的计算表现,解决这一问题的办法是采用数据复用(data reuse),变相增加带宽。

如上图:在计算引擎启动前在片内存储(BRAM)加载输入/输出特征图和权重,计算完成将输出特征图写回片外内存。
Local Memory Promotion:如果最内层循环在交流的部分(如图9中的循环![]() )对于数组而言是不相关的,那么在不同的循环迭代操作中会有冗余的内存操作。在图9中循环维度
)对于数组而言是不相关的,那么在不同的循环迭代操作中会有冗余的内存操作。在图9中循环维度![]() 与输出数组
与输出数组![]() 不相关,所以对输出数组
不相关,所以对输出数组![]() 的访问可以放在更外层。并且在最内层循环对内存访问变成相关之前,Promotion可以迭代进行。
的访问可以放在更外层。并且在最内层循环对内存访问变成相关之前,Promotion可以迭代进行。
Loop Transformations for Data Reuse: 最大化数据重用使用Local Memory Promotion,表三显示了循环迭代和数组间的关系,Local Memory Promotion被使用在每一个合法的循环,无论是否真的减少了总的通信流量。

CTC Ratio. CTC被用来描述:计算量/每一次内存访问。计算CTC:


3.4 设计空间考察

作者最终使用了图(b)中的(C)点做实际设计,实际使用平台带宽(2.2GB/s)。图中斜率表示所需带宽,粗灰色线斜率表示平台最大带宽,即使用较大的CTC ratio 减少依赖使用平台带宽。
3.5 多层CNN加速器设计

作者发现每一层单独优化(不同的分块因子),有助于提高性能,但会带复杂的硬件结构,最终使用了统一的分块因子<64,7>,只降低了5%的性能。
4,运行细节
4.1 系统概览

由微控制器MicroBlaze和主机cpu进行通信。AXI4Lite总线负责发送命令,AXI4总线负责发送数据。
4.2 计算引擎

计算采用树形多边形结构。
4.3 内存子系统
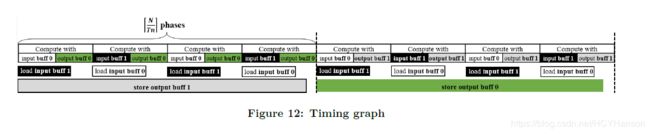
为了在执行计算时也能够传输数据,片上内存采用乒乓策略的双缓冲结构。
4.4 外部数据传输引擎

增加IP-AXI总线接口的位宽对带宽没有影响,而给AXI总线增加更多的IP接口数几乎线性的增加带宽,作者为了获得至少1.5Gb/s的带宽,使用了4个IP。
5,实验评估

FPGA资源利用情况;

和过去的研究比较;

和cpu进行速度和能耗的比较;

浮点和定点硬件资源利用比较;
6,相关工作
介绍一些已有的工作,指出优缺点;
7,总结
- 提出roofline模型
- 对所有可能的分片情况建模,选出通用的最好设计
- 通过枚举找到了最佳的跨层设计。
解读如有不足之处,还请不吝赐教!