从commons pool2到池
转载请注明:http://blog.csdn.net/HEL_WOR/article/details/51224388
池该如何理解?我们经常提到的数据库连接池,线程池,对象池。
池这个概念,在计算机里,应该如何用代码来描述?
在网页上可以找到很多关于数据库连接池的描述,实现DataSource接口,用一个链表或者只要能保存数据的容器将事先创建好的连接保存起来,一个连接池就成型了,在需要使用的时候去容器里取出一个连接,使用完毕后归还这个连接,如果想要重写close方法让连接归还到容器中而不是被关闭,那么使用一个动态代理,将原始逻辑封装起来,在需要使用真实对象的close方法时将这个方法拦截,再实现一个归还到链表的逻辑即可。
读源码是为了知道设计者的思路,为什么要这么设计,为什么要这么实现,量变会带来质变,到最后我们要自己设计实现一些内容时,就能触类旁通了,但上面的实现,似乎并不能让我们看到多少内在的内容。
我们可以再往下看看。
什么是池?
一个用来装载资源的容器,这个资源可以是线程,可以是连接,可以是对象;这个容器可以是链表,可以数组,可以是队列等等。
在JDK的线程池实现中,这个池子是用HashSet来实现的。

当创建线程需要将线程加到池子中,这一步是在addWorker函数下完成的。
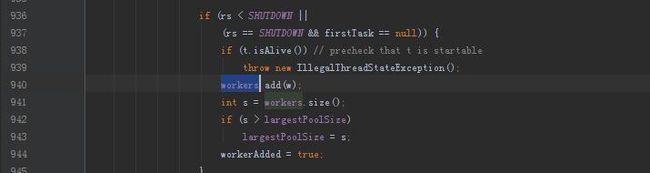
创建后就添加到池子,这一点在commons pool2和线程池的实现中都是相同的,即使让我们来思考,这样的做法也是很正常的。
但与common pool2中不同的是,线程池中并没有提供pollFirst方法,这个方法在common pool2中表示的含义是从池子中取出一个连接,但在线程池中,没有这个取出的方法,因为线程池中不需要从线程池里拿出一个线程去处理正在任务队列里排队的任务,为什么这么说呢,因为首次通过addworker方法创建线程后这个线程会先执行自己的方法,然后这个线程会自己去任务队列中获取排队的任务,所以其并不需要一个取出线程的方法,关于线程池的详细执行流程我后面再单开一篇博客来细说,现在先回到池这个主题。
再来看看common pool2中关于池的描述。
连接池的描述使用一个双端队列来描述的,这个双端队列其实也是使用List来描述的,而阻塞的实现,是使用await(),signal()方法来实现的,关于await(),signal()方法,和object下的wait(),notify()方法本质是一样的,如果有兴趣可以看看条件队列这篇博客,看完其实就明白了。

从池子里拿出一个连接中在borrowObject方法中实现的,通过pollFirst()方法或者takeFirst()方法从LinkedBlockingDeque(双端队列)这个池子的实现中去取出连接。
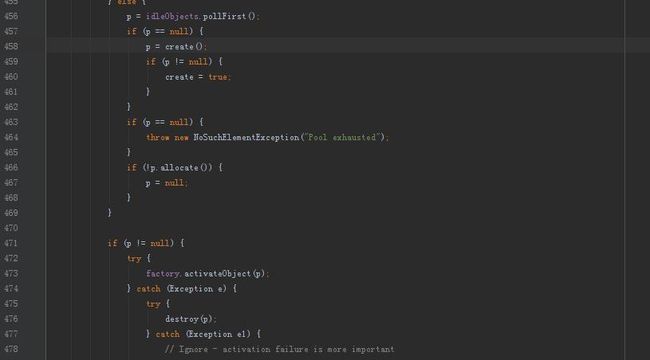
将创建的对象加入到池子中的逻辑是在returnObject方法里实现的。
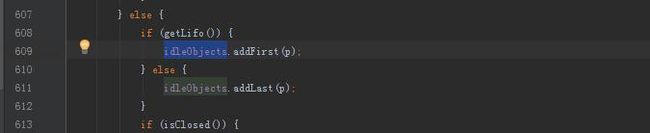
这里和线程池中实现有区别,在线程池中,当线程一被创建就会加入到池子中,但在common pool2中,创建的连接在被使用之后(加入之前还会有验证等一系列操作)才会被加入到池子中,这样的设计是为什么呢?
在borrowObject方法中,也就是去池子里拿出一个连接的方法中,其实现的方式是先去LinkedBlockingDeque(双端队列)这个池子的实现中去取出连接,如果没有拿到连接,那么创建一个连接对象,所以,创建的这个连接在使用完后就会被加入到池子中。
到此,我们可以抽象出一个池子的实现方法,不论是线程池,连接池,还是对象池,池子的组成就3个要素:
1.池的描述。
2.取出对象的方法.
3.对象放回池的方法.
那么这3点的要素的代码描述对应为:
1.一个容器,可以是链表,队列,集合,数组,只要能够保存对象的数据结构都可以
2.各个数据结构的获取方法,也可以自己定义。
3.各个数据结构的加入方法,同样可以自己定义。
仅从池这个角度来描述,这三点,其实就是common pool和线程池的共性,而下次当我们需要实现自己的池子,就可以知道如何设计了。
那现在我们来详细的看看common pool2的实现结构。
再描述后续逻辑之前,我们先想想几个问题。
1.为什么要将对象封装为池对象,不论这个被封装的对象是线程还是连接。
2.为什么会出现驱逐逻辑?其又是如何实现的?
3.为什么要使用到池对象工厂?
4.为什么连接要再使用完毕之后才会加入到连接池?
接下来我们开始看看common pool2的源码。
关于common pool2的使用,可以先看看这篇博客:Apache Commons 系列简介 之 Pool。简单来说,common pool2的使用步骤为:
1.将对象封装为池对象,这一步在PooledObjectFactory中完成。
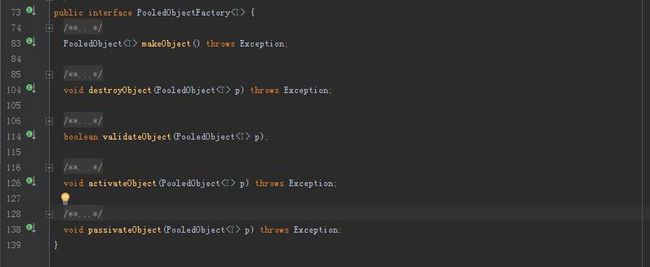
这个工厂类是一个接口,规定了一系列的池对象方法,作为一个框架,很重要的一点需要实现基本的逻辑部分,需要灵活处理的地方再交由使用者自行处理,所以,在common-pool2中用一个抽象类(BasePooledObjectFactory)实现了这个工厂接口。
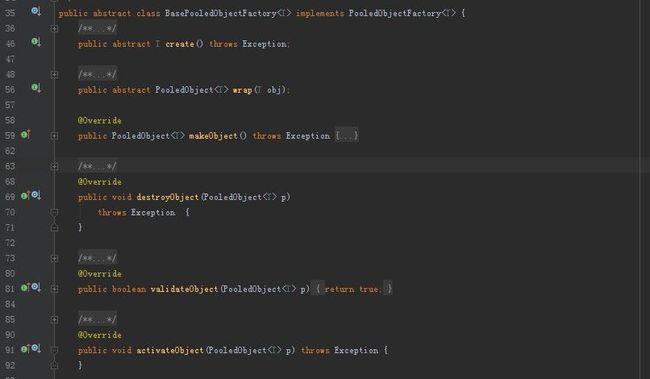
对于必要的部分,代码由common-pool2实现,需要使用者实现的代码打上abstract标记即可,所以当我们需要实现一个池对象工厂时,只需继承BasePooledObjectFactory类并实现create()方法和warp()方法,这两个方法分别表示为:创建对象,把创建的对象封装为池对象。创建池对象可以通过common pool2中的DefaultPooledObject类来完成。
2.将池对象工厂和池的配置信息作为参数传入对象池类的构造函数中获得对象池的实例。
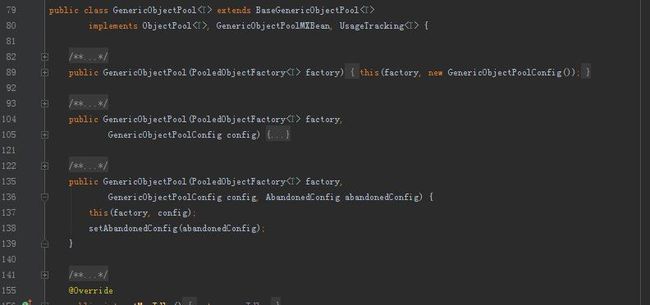
3.获得这个对象池实例后,我们就可以使用获取对象和将对象放回池中的方法了。在GenericObjectPool中这两个方法分别为borrowObject()何returnObject()方法。
以GenericObjectPool为例,来看看对象池的控制逻辑,包括驱逐逻辑,取出,放入。
下面是GenericObjectPool的构造函数:
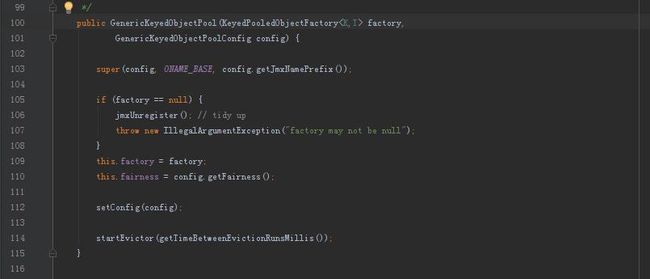
1.设置池对象工厂,这里面会涉及到一系列的对池对象的处理操作,包括激活对象(activateObject),验证对象(validateObject),钝化对象(passivateObject)。
2.设置队列是否满足公平性,简单的说就是按FIFO还是按照优先级。
3.开始执行驱逐逻辑
对于common-pool2池子里最主要的3个逻辑,borrowObject(),returnObject(),startEvictor()。
先来看borrowObject的源码,因为源码太长,所以只截取主要逻辑:
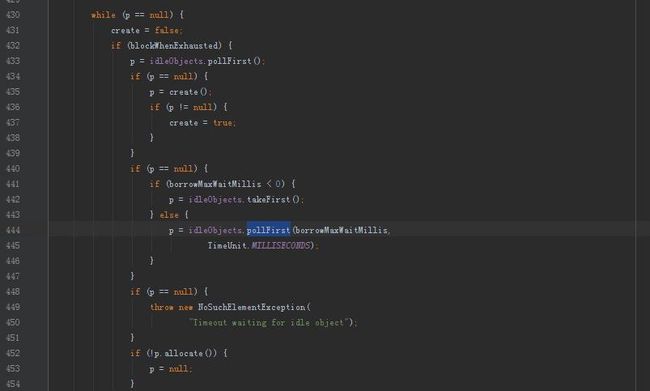
这段代码是阻塞式的从池中获取对象的逻辑。
最顶端的while (p == null),是为了确保拿到对象后才能跳出循环,进入后续的激活,验证逻辑。
柱塞式的最终实现主要表现在pollFirst和takeFirst的区别上,两个方法都是实现从双端队列中取出对象;但在takeFirst方法中有下面这段代码:

notEmpty是一个Conditon对象的实例:
![]()
对于Condition接口可以由ReentrantLock通过调用newCondition方法实现,其调用await方法和signal方法与调用object的wait和notify方法类似,当调用await方法后,当前对象将被挂起,当前对象释放对象锁,允许其他线程进入当前对象以期满足先验条件,直至有其他线程调用当前对象的signal方法唤醒被阻塞的线程,被唤醒的线程将二次获取双端队列中的对象,获取成功后离开循环;否则,继续阻塞。
这段代码主要描述了,当无法从双端队列中获取对象时(这里必须是非阻塞的获取对象,如果是用takeFirst方法阻塞式的获取,由于初始双端队列是不存在对象的,这里就会造成永久阻塞),则创建对象,并为此对象设置初始化对象信息。
非阻塞式逻辑相同,所以不描述了。
接下来进入激活对象,验证对象,钝化对象逻辑(如果有需要)。
太晚了,明天再更新吧。