Azkaban 使用
Azkaban 安装请参考博客:
https://blog.csdn.net/hg_harvey/article/details/80342396
登录Azkaban,首页有四个菜单

projects:最重要的部分,创建一个工程,所有flows将在工程中运行。
Scheduling:显示定时任务
Executing:显示当前运行的任务
History:显示历史运行任务
主要介绍Projects部分,在创建工程前,我们先了解下之间的关系,一个工程包含一个或多个flows,一个flow包含多个job。job是你想在azkaban中运行的一个进程,可以是简单的linux命令,可是java程序,也可以是复杂的shell脚本、或者python脚本,当然,如果你安装相关插件,也可以运行插件。一个job可以依赖于另一个job,这种多个job和它们的依赖组成的图表叫做flow。
web-server:节点负责项目作业管理(上传和分发)
exec-server:负责具体执行的executor会解析job文件
一、commond 类型单一Job
1.创建工程
创建完成后跳转到如下页面

Flows:工作流程,有多个job组成
Permissions:权限管理
Project Logs:工程日志
2.创建Job
job就是一个以.job结尾的文本文件,例如创建一个job,名为hello.job,用于打印hello azkaban
# hello.job
type = command
command = echo 'hello azkaban'3.打包
将创建的job打包成.zip压缩文件,注意只能是.zip格式

4.使用Azkaban UI 界面创建project并上传压缩包
点击Execute执行

然后点击Continue
执行后,点击Detail,查看日志

可以看到打印出来hello azkaban

二、commond 类型多JOb 工作流 flow
1.创建项目
首先,创建一个项目,名为 command_multiple_job

2.job 创建
假设有这么一种场景:
(1).task1 依赖 task2
(2).task2 依赖 task3
(3).task3 依赖 task4
说明:假设task1是一个计算指标任务,task2 给 task1 提供执行需要的基础数据
task3 给 task2 提供数据,以此类推。
3.flow 创建
多个jobs和它们的依赖组成flow。怎么创建依赖,只要指定dependencies参数就行了
定义4个job:
(1).run_task1.job:计算业务指标数据
(2).run_task2.job:计算task1所需要的数据
(3).run_task3.job:计算task2所需要的数据
(4).run_task4.job:从 slaves 中抽取源数据
依赖关系:
task1 依赖 task2,task2 依赖 task3,task3 依赖 task4
4个job文件内容如下(这里以执行python为例,这个比较popular哈)
# run_task1.job
type = command
command = python /home/hadoop/pyshell/run_task1.py
dependencies = run_task2# run_task2.job
type = command
command = python /home/hadoop/pyshell/run_task2.py
dependencies = run_task3# run_task3.job
type = command
command = python /home/hadoop/pyshell/run_task3.py
dependencies = run_task4# run_task4.job
type = command
command = python /home/hadoop/pyshell/run_task4.py创建python脚本
[hadoop@harvey pyshell]$ touch run_task1.py
[hadoop@harvey pyshell]$ touch run_task2.py
[hadoop@harvey pyshell]$ touch run_task3.py
[hadoop@harvey pyshell]$ touch run_task4.py4个文件内容如下,笔者只写了一句打印,这里根据公司你的业务写代码即可。
run_task1.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
print("task1:计算业务指标数据...")run_task2.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
print("task2:计算基础数据,为task1提供数据")run_task3.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
print("task3:数据清洗,为task2提供数据")run_task4.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
print("task4:从Slaves中抽取源数据")3.将上述 job 打成zip包,上传至 azkaban
上传完成后,点击右侧Execute Flow按钮,查看流程视图


Flow view:流程视图。可以禁用,启用某些job
Notification:定义任务成功或者失败是否发送邮件
Failure Options:定义一个job失败,剩下的job怎么执行
Concurrent:并行任务执行设置
Flow Parametters:参数设置。
4.执行
(1).执行一次,点击右下角Execute
(2).定时执行,点击左下角Schedule
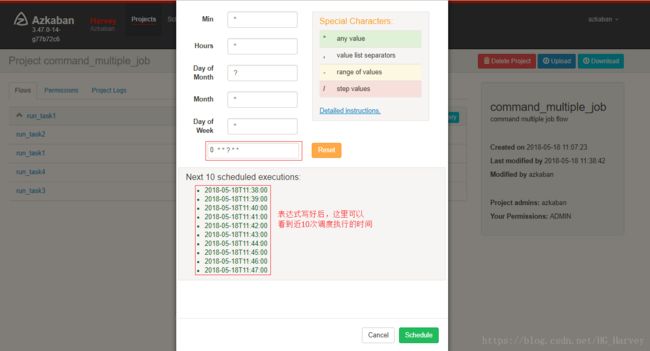
设置完成后,执行右下角schedule,即完成调度配置,azkaban这里的配置与linux下的crontab类似
想要查看job的调度列表,切换到Schedule菜单即可
5.查看项目flow中各个Job的执行情况

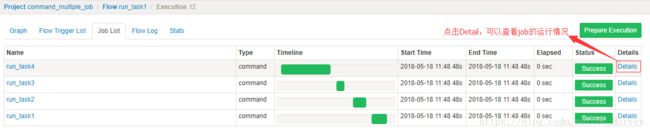
绿色代表成功,蓝色是运行,红色是失败。可以查看job运行时间,依赖和日志,点击details可以查看各个job运行情况
run_task4.job

run_task3.job

run_task2.job

run_task1.job

三、MapReduce 任务
Azkaban 执行 MapReduce 任务,我们以 WordCount 为例
1.准备数据
$ hadoop fs -mkdir -p /azkaban/input /azkaban/output
$ hadoop fs -put data/words.txt /azkaban/inputwords.txt文件内容
Welcomt to azkaban
Hello Hadoop
Hello Hive
Hello HBase
Hello Azkaban使用hadoop提供的jar统计单词数量
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.1.jar wordcount /azkaban/input/* /azkaban/output运行结果
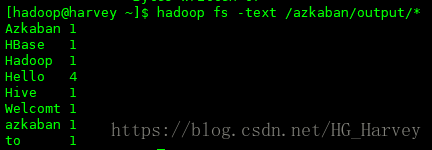
2.创建项目

3.job创建
job
# mapreduce_wordcount.job
type = command
command=sh /home/hadoop/shell/wordcount.shwordcount.sh
#!/bin/bash
# author:harvey
# fileName:wordcount.sh
input=/azkaban/input/*
output=/azkaban/output
hadoop fs -test -e $output
if [ $? -eq 0 ] ;then
printf "%s is exists!\n" $output
hadoop fs -rm -r $output
fi
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.1.jar wordcount $input $output4.打包上传,执行



5.查看运行结果
azkaban上打印的日志显示已经成功

查看运行结果

四、Hive 脚本任务
1.创建项目
2.job创建
我们要完成,hive中创建表,加载数据,然后导出数据到mysql,分为两个job
run_task1:将hive中的数据导出到mysql中
run_task2:hive中创建表,加载数据
依赖关系:run_task1 依赖 run_task2
3.flow创建
job 文件内容如下
# run_task1.job
type = command
command = sh /home/hadoop/shell/run_task1.sh
dependencies = run_task2# run_task2.job
type = command
command = sh /home/hadoop/shell/run_task2.sh脚本内容如下
#!/bin/bash
# author:harvey
# fileName:run_task1.sh
#!/bin/bash
# author:harvey
# fileName:run_task1.sh
/home/hadoop/software/sqoop1/bin/sqoop export \
--connect jdbc:mysql://localhost:3306/sqoop \
--username root --password P@ssw0rd \
--table emp \
--export-dir /user/hive/warehouse/test.db/emp \
--input-fields-terminated-by '\t' \
--input-null-string '\\N' --input-null-non-string '\\N' \
-m 1#!/bin/bash
# author:harvey
# fileName:run_task2.sh
hive -f /home/hadoop/sql/test.sqlsql文件 test.sql内容如下
create database if not exists test;
use test;
drop table if exists emp;
create table emp(
empno int,
ename string,
job string
)
row format delimited fields terminated by '\t';
load data local inpath '/home/hadoop/data/emp.txt' overwrite into table emp;emp.txt文件内容如下
1001 Tom Java
1002 Jack PHP
1003 Harvey BigData
1004 David IOS
1005 Ketty DBA说明:脚本run_task1.sh中为什么使用全路径的原因是笔者使用sqoop运行后,azkaban报找不到sqoop命令(已经配置了环境变量),具体什么原因笔者也不清楚,如果你知道,记录留言一下。使用全路径后就不会命令找不到了。
4.打包上传
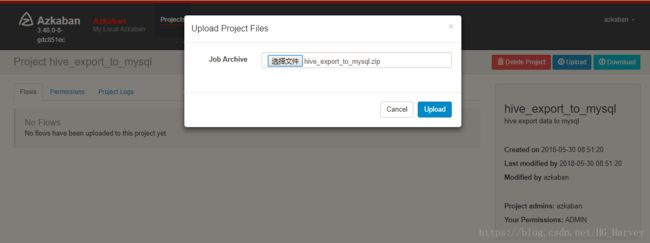
5.执行,查看运行结果
执行前记得先在mysql中创建表emp,sql语句如下
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`empno` int(11) DEFAULT NULL,
`ename` varchar(255) DEFAULT NULL,
`job` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
SET FOREIGN_KEY_CHECKS=1;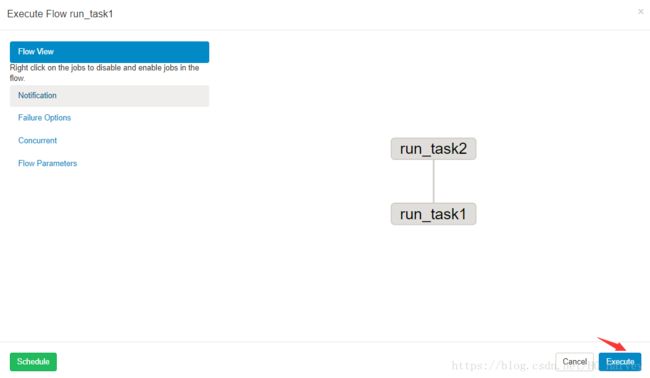
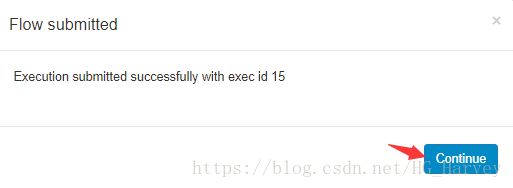
然后Continue执行
执行完成后hive查看表emp是否存在mysql中查看表emp是否有数据

