C++中 类与对象,类的定义,类的作用域,类中成员,this指针
概要
这篇文章主要内容是关于类与对象,类的定义,类的作用域,类中成员,this指针。写的比较粗,后期有时间再改。
文章目录
- 概要
- 什么是类?
- 定义一个类
- class 和 struct 有什么区别?
- 如何在类外访问私有成员?
- 类的作用域
- 对象的大小
- this指针
- __cdecl 和 __thiscall
什么是类?
对于类,我认为最早的发言人还是亚里士多德。他归纳事物的方法就是这是什么(属性)、能干什么(方式)、 起个名字(对象名) 、归类(抽象)。
天地有大美而不言,但人能够言其美。计算机语言也能在二进制世界中构建万事万物。
那么C++的想法就是将 事物抽象成一个类,将事物的属性和方法封装到类中。用成员变量表示类的属性,用函数成员表示类的方法。class 为此而生。
class student
{
private:
char _name[20];
char _gender[4];
int _age;
public:
void SetstudentInfo(char *name, char *gender, int age);
void PrintstudentInfo();
};
上面先简单定义一个student类,学生有姓名,性别,年龄等属性。学生类还应该有填写信息的方法SetstudentInfo();学生类有表示自己信息的方法 PrintstudentInfo();
归纳一下一个类有自己的属性(成员变量),自己的方法(函数成员)。
c++是基于面向对象的语言,它具有三大特点:封装,继承,多态
这里主要说明封装性。 封装就是将数据和操纵数据的方法有机的结合起来,只留出外部接口进行调用。简单点,我不需要知道电视机上的画面是怎么来的,但是我会看电视了解新闻信息就行了。c++在class中加入了访问限定符 private 和 public。private定义的成员无法被类外访问,相当于设计者将这些东西藏了起来。public定义的成员可以被类外访问,相当于提供了使用权。
定义一个类
定义一个类有两种方式:
1.类的声明与定义放在一起
2.类的声明放在.h头文件里面,类的定义放在.cpp文件里面
问题:这两种定义有什么区别?
在头文件中放置内部链接的定义却是合法的,但不推荐使用的。因为头文件被包含到多个源文件中时,不仅仅会污染全局命名空间,而且会在每个编译单元中有自己的实体存在。大量消耗内存空间,还会影响机器性能。 注1
编译单元是源文件的意思。对于第一种方法:,如果在头文件中实现了类的定义,那么这个头文件无疑是非常大的。这个时候多个源文件引用了这个头文件就会造成头文件代码重复使用。对于第二种方法: 一个单独的cpp文件实现了类的方法。这个cpp是能外部链接的。如果多个源文件引用了这个头文件,那么他们不需要将头文件的实现拉入自己的文件中。只需要通过外部链接的方式找到头文件方法的实现就可以了。
class 和 struct 有什么区别?
1.在struct中无法定义函数成员。如果想要封装特定的方法就需要使用函数指针。class关键字定义出来的类,可以定义函数成员。函数成员可以封装相应的方法。
2.struct定义出的结构体不具有安全性,它的默认访问限定符是public。外部代码都可以访问结构体中的变量。class定义出的类具有安全性,它的默认访问限定符是private。外部代码无法访问被private修饰的成员。
如何在类外访问私有成员?
1.通过公有的方法
class A{
private :
int a;
public:
int Geta()
{
return a;
}
};
在类中定义一个公有的方法,这个方法可以作用于私有成员变量。
2.指针访问
class A
{
public:
int a;
private:
int b;
int c;
};
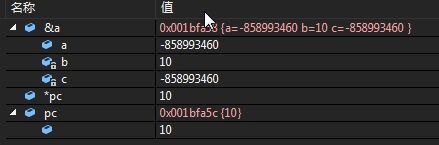
int main()
{
A a;
A *pa = &a;
int *pc = (int *)((int)&a + 4);
*pc = 10;
system("pause");
return 0;
}
假定获取了一个成员变量的地址,在这个地址上加上相对位置的偏移量就可以修改private 成员。
类的作用域
如何证明定义了一个类,将相当于定义了一个作用域?
初级方案:在类中定义一个变量,在主函数定义一个同名变量能不能调用它。
class Test
{
private:
int _t;
};
int main()
{
int _t = 2;
cout << _t << endl;
return 0;
}
打印结果是2,而不是随机数。以上说明类自成一体,类的范围就是作用域的范围。
高级方案:
namespace N
{
int t = 10;
void TestFunc()
{
cout << "TestFunc" << endl;
}
}
class Test
{
public:
void TestFunc(int t)//1.当参数的名字和类中成员变量的名字一样是谁传给谁?
{
t = t;
}
void print()
{
cout << t << endl;
}
private:
int t;// 2.声明为什么能放在最后面?
};
void TestFunc(int t)
{
cout << "TestFunc(int t)" << endl;
}
int main()
{
int t = 40;
cout << N::t << endl;
Test tt;
tt.TestFunc(20);
tt.print();
system("pause");
return 0;
}
1.当参数的名字和类中成员变量的名字一样是谁传给谁?
TestFunc(int t)的参数自己传给自己。因为参数t在函数的作用域的优先级最高。在TestFunc(int t)作用域中 int t的优先级高所以会一直调用 本函数的参数进行操作。
2.声明为什么能放在最后面?
因为在类中声明具有全局属性,即在一处声明定义,可以在整个类中处处被使用。类是按照整体来被观测的,而不是按照C中一步一步被观测的。
归结:1.避免函数成员的参数与成员变量同名。2.类中声明的变量具有全局属性
对象的大小
在C语言中由于没有函数成员,所以按照内存对其就可以得到一个struct类型变量的大小。
#define _CRT_SECURE_NO_WARNINGS 1
#include在 student 类中 对于成员变量,根据内存对其规则它的大小是 28。整个类型的大小也是28,也就是说没有发现类中成员函数的大小。所以有以下推断。

类创建的对象时,只创建了对象的成员变量。没有创建函数成员。多个对象可能公用一个类的函数。
class Test
{};
struct test
{};
int main()
{
Test t;
struct test T;
cout << "sizeof(t):" << sizeof(t) << endl;
cout << "sizeof(T):" << sizeof(T) << endl;
system("pause");
return 0;
}
问题:为什么空类和空的结构体实例化出的对象 占了一个字节?
设定一个空的类和一个空的结构体,测试他们的大小,发现他们两个的大小都是 1。为什么对于一个空的对象,或者空的结构体变量的大小是一个1字节。原因可能是即使没有属性的类,它实例出的对象也是有区别的,每个对象 独一无二 所以要加一个字节区分。另外如果在内存当中创建了一个对象,如果不加一个字节区分的话,那么就相当于,多个变量公用一个存储单元。
this指针
问题:如果调用的是同一个函数,那么编译器是怎么知道吧变量放在不同对象的成员变量里?
class student
{
private:
char _name[20];
char _gender[4];
int _age;
public:
void SetstudentInfo(char *name, char *gender, int age);
void PrintstudentInfo();
};
void student::SetstudentInfo(char *name, char *gender, int age)
{
strcpy(_name, name); // 将 name 放给谁的_name里,是 d1._name 还是 d2._name 还是d3._name
strcpy(_gender, gender);
_age = age;
}
void student::PrintstudentInfo()
{
cout << _name << " " << _gender << "" << _age << " " << endl;
}
int main()
{
student d1, d2, d3;
d1.SetstudentInfo("John", "man", 17);
d2.SetstudentInfo("Brown", "man", 27);
d3.SetstudentInfo("Mike", "man", 37);
system("pause");
return 0;
}
为什么编译器能够识别不同对象调用其公有的类成员函数?原因是编译器默认,在类成员函数中调用了一个 this 指针。this 代表着正在使用这个类成员函数的对象。通过这个this指针可以区别不同对象。
d1.SetstudentInfo("John", "man", 17);
00EC5C38 push 11h
00EC5C3A push 0ECCC7Ch
00EC5C3F push 0ECCC88h
00EC5C44 lea ecx,[d1]
00EC5C47 call student::SetstudentInfo (0EC1230h)
编译器在调用函数的时候先使用了语句 lea ecx,[d1] 将这个对象的地址线保存起来,然后才调用SetstudentInfo函数。
void student::PrintstudentInfo()
//void student::PrintstudentInfo(student const *this)
{
cout << this->_name << " " << this->_gender << "" << this->_age << " " << endl;
}
编译器在编译过程当中,将类成员函数进行修改,将this添加进入函数。这样就可以识别不同对象的不同参数。this 指针存放在 ecx 寄存器,this指针不为空,因为是自动调用。
__cdecl 和 __thiscall
微软的定义:
__cdecl是默认调用约定的 C 和 c + + 程序。 由调用方清理堆栈,因为它可以执行vararg函数。 __Cdecl调用约定创建更大的可执行文件比__stdcall,因为它要求每个函数调用包括堆栈清理代码。 以下列表显示此调用约定的实现。
__thiscall 调用预定用于成员函数,且是 C++ 成员函数的默认调用约定,不使用可变参数。 在 __thiscall下,被调用方清理堆栈,对于 vararg 功能是不可能的。 参数从右向左被推入堆栈,与此同时,this 指针通过寄存器 ECX 传递到 x86 结构上而不是堆栈上。
简单来说,__cdecl 是执行可变参数列表 ,他的函数参数入栈必须从右往左 。__thiscall 主要处理类的成员函数,他的参数入栈是从左往右。另外,如果在类中使用可变参数列表,那么它会按照 __cdecl 来处理。