0674-5.16.2-如何在CDH5中使用Phoenix4.14.1
Fayson的github: https://github.com/fayson/cdhproject
推荐关注微信公众号:“Hadoop实操”,ID:gh_c4c535955d0f
1 文档编写目的
Apache Phoenix是Apache HBase上一个高效的SQL引擎,很多公司都在使用它,比如Salesforce,它开源了这个项目,并将该项目贡献到社区。很早也已经是顶级项目了。大家知道HDP中一直都包含Phoenix,老的CDH源生是不包含Phoenix的,但是Apache Phoenix社区对于C5的各个版本其实都有发布Parcel,但是这个不受Cloudera官方支持,参考Fayson之前的文章《0308-如何在CDH5.14.2中安装Phoenix4.14.0》。现在Cloudera和Hortonworks合并以后,两边的产品也进行了合并,如之前介绍的CFM,CEM集成到CDH,现如今Phoenix也包含到了CDH中,Cloudera官方会提供支持。本文Fayson会对Phoenix做一个简单介绍后,然后介绍如何在CDH5.16.2中安装和使用Phoenix。
测试环境
1.RedHat7.4
2.CDH5.16.2
3.Phoenix4.14.1
4.集群已启用Kerberos
2 什么是Apache Phoenix
首先Phoenix是HBase之上的SQL工具, Phoenix旨在通过标准的SQL语法来简化HBase的使用,并可以使用标准的JDBC连接HBase,而不是通过HBase的Java客户端APIs。它可以让你执行所有的CRUD和DDL操作,比如创建一张表,插入数据以及查询数据。SQL和JDBC可以大大减少用户代码的开发,当然它也提供一些性能优化的手段,通过SQL和JDBC,你可以更方便的将HBase集成到你现有的系统或者工具。
当Phoenix接收到SQL查询后,它会在本地编译成HBase的API,然后推到集群进行分布式的查询或计算。它自动创建了一个元数据库用来存储HBase的表的元数据信息。因为Phoenix是直接调用的HBase的API,coprocessors和自定义的filters,所以对于大量小查询可以实现毫秒级返回,千万级别的数据实现秒级返回。
3 使用场景
Phoenix非常适合HBase的随机访问,它的二级索引特性同时可以让你实现非主键查询的快速返回,而不需要进行全表扫描。它可以让你像传统数据库表的方式创建和管理HBase中的表,同时Phoenix也支持复合主键。
Phoenix可以给Rowkey加盐,从而避免因为简单递增的Rowkey引起的RegionServer热点问题。通过指定不同的租户连接实现数据访问的隔离,从而实现多租户,租户只能访问属于他的数据。
虽然Phoenix有这么多优势,但是它依旧无法替代RDBMS。比如它还有以下限制:
-
Phoenix不支持跨行的事务
-
查询优化和join机制比大多数RDBMS要简陋
-
二级索引是通过索引表实现的,主表和索引表的同步会存在问题,虽然只是在一段很短的时间内。所以索引无法完全满足ACID
-
多租户功能比较简单
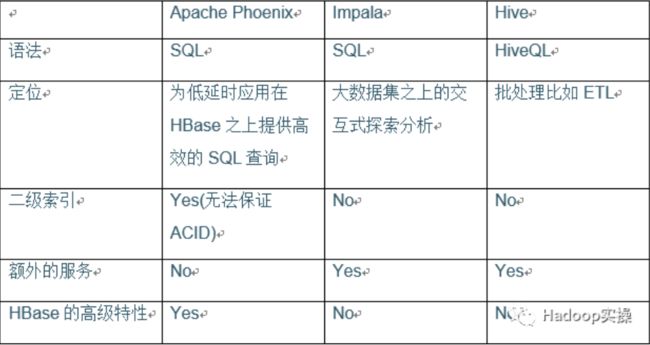
4 与Hive/Impala的比较
Hive/Impala也可以作为HBase之上的SQL工具。包括Phoenix这3个工具在很多功能上都有一些重叠,比如它们都提供SQL执行以及JDBC驱动
不像Impala和Hive,Phoenix与HBase结合更加紧密,从而可以更好的利用HBase的一些特性,比如coprocessors和skip scans。
-
Phoenix的目标是在HBase之上提供一个高效的类关系型数据库的工具,定位为低延时的查询应用。Impala则主要是基于HDFS的一些主流文件格式如文本或Parquet提供探索式的交互式查询。Hive类似于数据仓库,定位为需要长时间运行的批作业。
-
Phoenix很适合需要在HBase之上使用SQL实现CRUD,Impala则适合Ad-hoc的分析类工作负载,Hive则适合批处理如ETL。
-
Phoenix非常轻量级,因为它不需要额外的服务。
-
Phoenix还支持一些高级功能,比如多个二级索引,flashback查询等。无论是Impala还是Hive都无法提供二级索引支持。
以下是比较:
5 安装Phoenix4.14.1
1.首先下载Phoenix的Parcel包
-rw-r--r-- 1 root root 4631 Jul 18 07:41 manifest.json
-rw-r--r-- 1 root root 368936960 Jul 18 07:43 PHOENIX-4.14.1-cdh5.16.2.p0.1216424-el7.parcel
-rw-r--r-- 1 root root 89 Jul 18 07:41 PHOENIX-4.14.1-cdh5.16.2.p0.1216424-el7.parcel.sha1

2.将Phoenix4.14.1的安装包发布到http服务
[root@ip-172-31-13-38 ~]# mv phoenix4.14.1/ /var/www/html/
3.在Cloudera Manger中配置Phoenix4.14.1的Parcel地址。
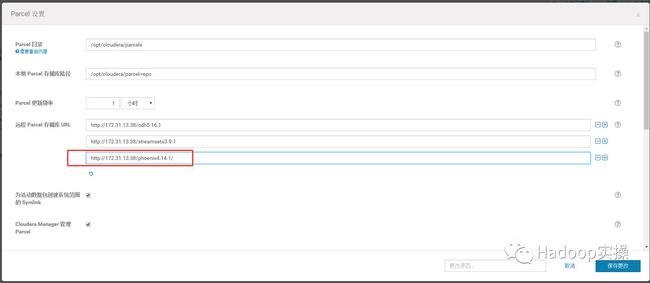
保存更改
4.然后下载->分配->激活
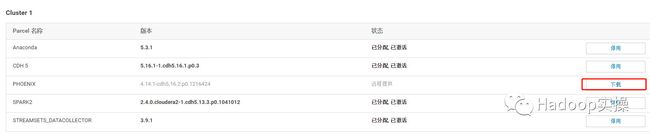

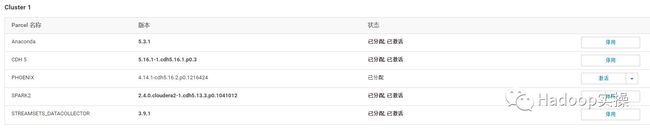
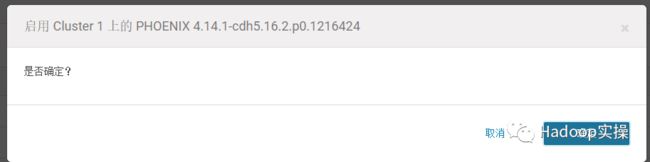
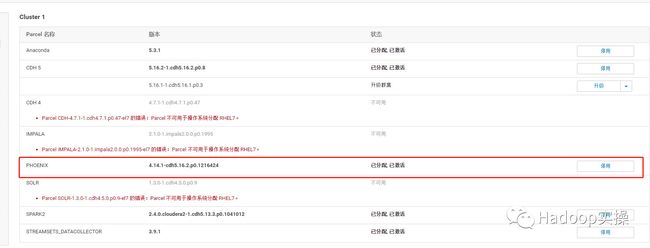
5.回到主页发现HBase服务要部署客户端配置并重启。
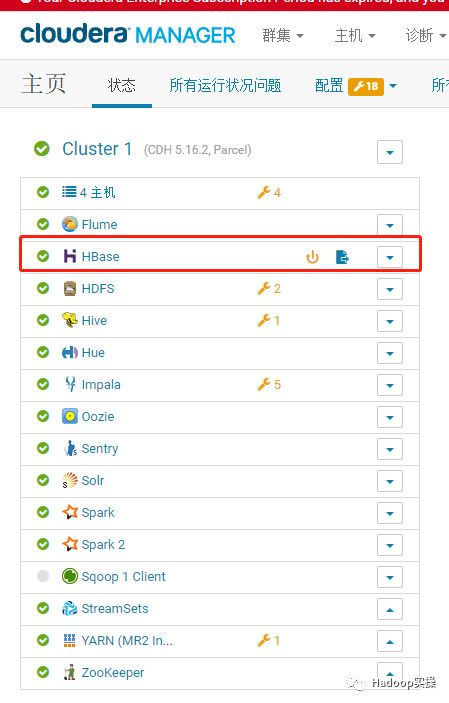
按要求重启服务,过程略。
6 Phoenix4.14.1的基本操作
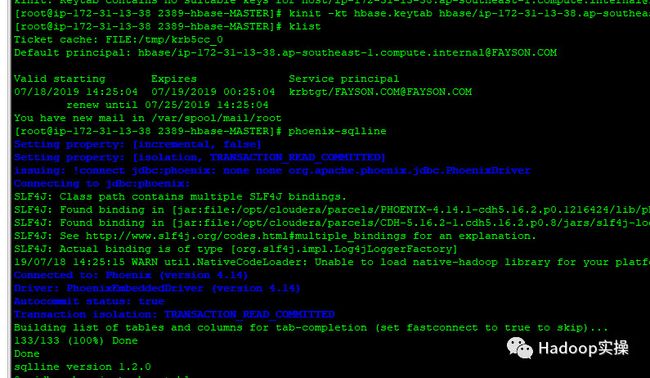
1.连接到Phoenix的终端,在Phoenix中建表hbase_test
[root@ip-172-31-13-38 2389-hbase-MASTER]# kinit -kt hbase.keytab hbase/[email protected]
[root@ip-172-31-13-38 2389-hbase-MASTER]# phoenix-sqlline
create table hbase_test
(
s1 varchar not null primary key,
s2 varchar,
s3 varchar,
s4 varchar,
s5 varchar,
s6 varchar,
s7 varchar,
s8 varchar,
s9 varchar,
s10 varchar,
s11 varchar
);
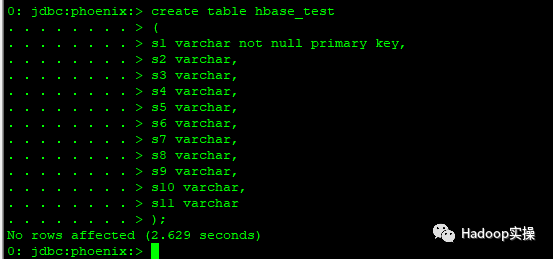
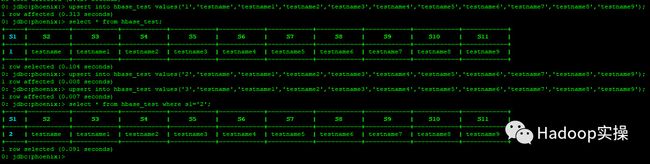
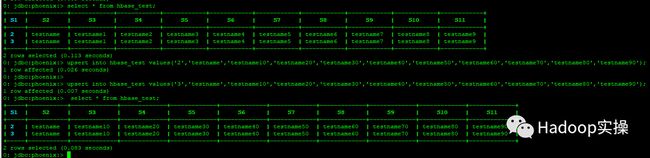
2.插入一条数据,然后进行查询。注意:Phoenix中没有insert语法,用upsert代替。
upsert into hbase_test values('1','testname','testname1','testname2','testname3','testname4','testname5','testname6','testname7','testname8','testname9');
select * from hbase_test;
upsert into hbase_test values('2','testname','testname1','testname2','testname3','testname4','testname5','testname6','testname7','testname8','testname9');
upsert into hbase_test values('3','testname','testname1','testname2','testname3','testname4','testname5','testname6','testname7','testname8','testname9');
select * from hbase_test where s1='2';
3.在hbase shell中进行检查
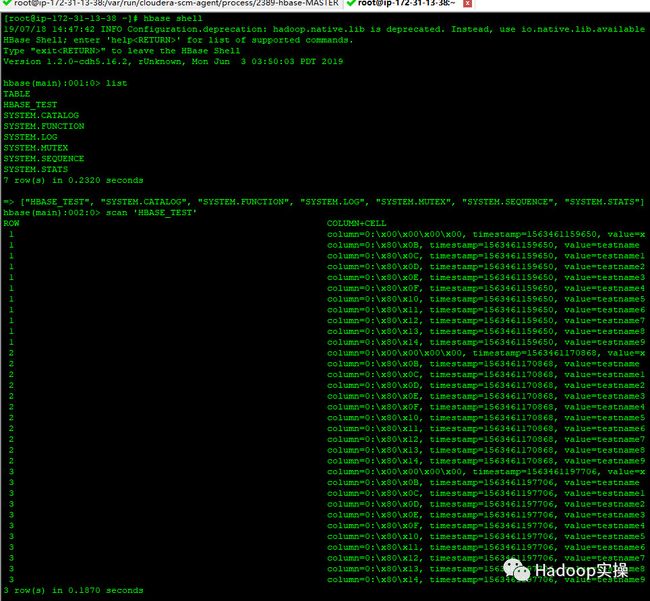
可以发现之前通过Phoenix创建的hbase_test表存在,并且插入的3条数据也显示正常。
4.Delete测试。
0: jdbc:phoenix:> delete from hbase_test where s1='1';
1 row affected (0.009 seconds)
0: jdbc:phoenix:> select * from hbase_test;
+-----+-----------+------------+------------+------------+------------+------------+------------+------------+------------+------------+
| S1 | S2 | S3 | S4 | S5 | S6 | S7 | S8 | S9 | S10 | S11 |
+-----+-----------+------------+------------+------------+------------+------------+------------+------------+------------+------------+
| 2 | testname | testname1 | testname2 | testname3 | testname4 | testname5 | testname6 | testname7 | testname8 | testname9 |
| 3 | testname | testname1 | testname2 | testname3 | testname4 | testname5 | testname6 | testname7 | testname8 | testname9 |
+-----+-----------+------------+------------+------------+------------+------------+------------+------------+------------+------------+
2 rows selected (0.113 seconds)
0: jdbc:phoenix:>

5.更新数据测试,注意Phoenix中没有update语法,用upsert代替。插入多条数据需要执行多条upsert语句,没办法将所有的数据都写到一个“values”后面。
upsert into hbase_test values('2','testname','testname10','testname20','testname30','testname40','testname50','testname60','testname70','testname80','testname90');
upsert into hbase_test values('3','testname','testname10','testname20','testname30','testname40','testname50','testname60','testname70','testname80','testname90');
7 Phoenix4.14.1的bulkload
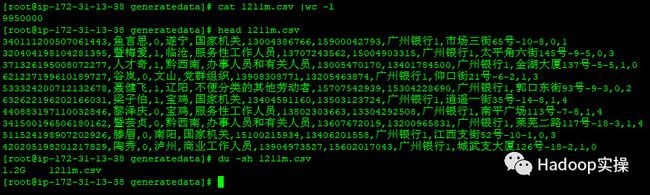
1.准备一个测试csv文件用来导入Phoenix的表中,Fayson这里准备一个1.2GB,995W行,11个字段的数据文件。
[root@ip-172-31-6-83 generatedata]# cat hbase_data.csv | wc -l
9950000
[root@ip-172-31-6-83 generatedata]# du -sh hbase_data.csv
1.2G hbase_data.csv
[root@ip-172-31-6-83 generatedata]# head hbase_data.csv
340111200507061443,鱼言思,0,遂宁,国家机关,13004386766,15900042793,广州银行1,市场三街65号-10-8,0,1
320404198104281395,暨梅爱,1,临沧,服务性工作人员,13707243562,15004903315,广州银行1,太平角六街145号-9-5,0,3
371326195008072277,人才奇,1,黔西南,办事人员和有关人员,13005470170,13401784500,广州银行1,金湖大厦137号-5-5,1,0
621227199610189727,谷岚,0,文山,党群组织,13908308771,13205463874,广州银行1,仰口街21号-6-2,1,3
533324200712132678,聂健飞,1,辽阳,不便分类的其他劳动者,15707542939,15304228690,广州银行1,郭口东街93号-9-3,0,2
632622196202166031,梁子伯,1,宝鸡,国家机关,13404591160,13503123724,广州银行1,逍遥一街35号-14-8,1,4
440883197110032846,黎泽庆,0,宝鸡,服务性工作人员,13802303663,13304292508,广州银行1,南平广场113号-7-8,1,4
341500196506180162,暨芸贞,0,黔西南,办事人员和有关人员,13607672019,13200965831,广州银行1,莱芜二路117号-18-3,1,4
511524198907202926,滕眉,0,南阳,国家机关,15100215934,13406201558,广州银行1,江西支街52号-10-1,0,3
420205198201217829,陶秀,0,泸州,商业工作人员,13904973527,15602017043,广州银行1,城武支大厦126号-18-2,1,0
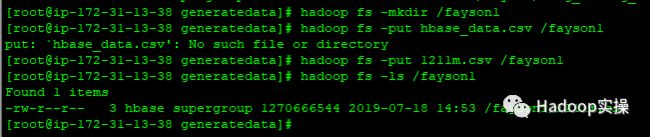
2.将准备好的csv文件put到HDFS,然后通过Phoenix自带的bulkload工具将准备好的csv文件批量导入到Phoenix的表中。
[root@ip-172-31-13-38 generatedata]# hadoop fs -mkdir /fayson1
[root@ip-172-31-13-38 generatedata]# hadoop fs -put 1211m.csv /fayson1
[root@ip-172-31-13-38 generatedata]# hadoop fs -ls /fayson1
HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH/lib/hbase/hbase-protocol-1.2.0-cdh5.16.2.jar:/opt/cloudera/parcels/CDH/lib/hbase/conf hadoop jar /opt/cloudera/parcels/PHOENIX/lib/phoenix/phoenix-4.14.1-cdh5.16.2-client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool -t hbase_test -i /fayson1/1211m.csv -z ip-172-31-11-232,ip-172-31-13-166,ip-172-31-11-9:2181
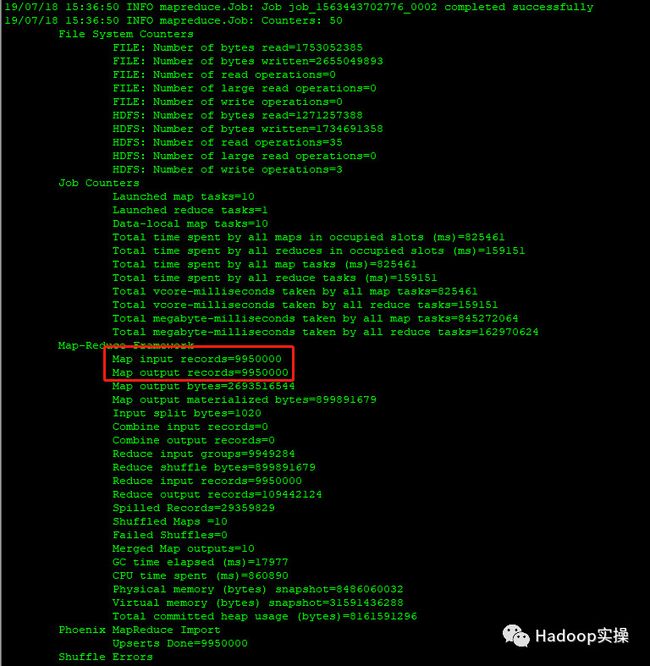
3.在Phoenix和hbase shell中分别查询确认数据入库成功。
select * from HBASE_TEST limit 10;
select count(*) from HBASE_TEST;
scan 'HBASE_TEST',{LIMIT => 1}
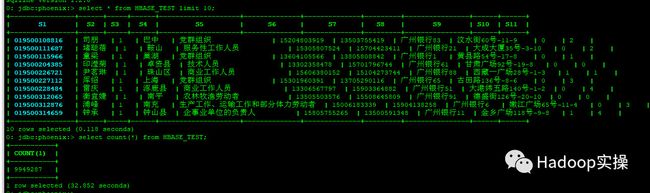
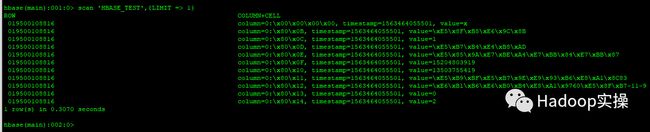
可以发现查询数据正常,入库条数也正确。
8 常见问题
1.Fayson的环境开启了Kerberos,使用普通用户kinit后执行phoenix-sqlline命令会报错如下:
Error: ERROR 1012 (42M03): Table undefined. tableName=SYSTEM.CATALOG (state=42M03,code=1012)
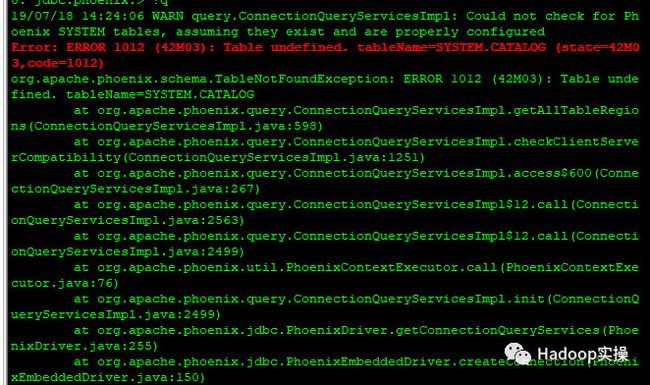
应该是普通用户没有权限建立Phoenix需要的系统表,解决方法是使用hbase的keytab登录。
2.执行bulkload导入csv文件的时候,直接使用以下命令
hadoop jar /opt/cloudera/parcels/PHOENIX/lib/phoenix/phoenix-4.14.1-cdh5.16.2-client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool -t hbase_test -i /fayson1/1211m.csv -z ip-172-31-11-232,ip-172-31-13-166,ip-172-31-11-9:2181
报错如下:
Thu Jul 18 15:25:50 UTC 2019, null, java.net.SocketTimeoutException: callTimeout=60000, callDuration=68620: row 'SYSTEM:CATALOG,,' on table 'hbase:meta' at region=hbase:meta,,1.1588230740, hostname=ip-172-31-13-166.ap-southeast-1.compute.internal,60020,1563444687845, seqNum=0
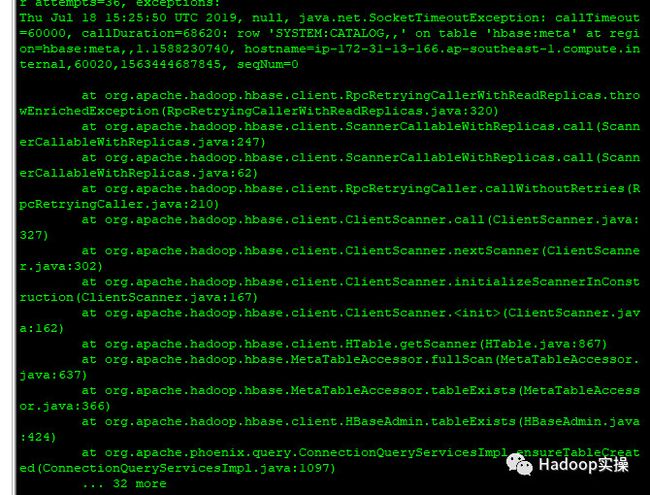
执行命令时引入HBase的环境变量解决问题:
HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH/lib/hbase/hbase-protocol-1.2.0-cdh5.16.2.jar:/opt/cloudera/parcels/CDH/lib/hbase/conf hadoop jar /opt/cloudera/parcels/PHOENIX/lib/phoenix/phoenix-4.14.1-cdh5.16.2-client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool -t hbase_test -i /fayson1/1211m.csv -z ip-172-31-11-232,ip-172-31-13-166,ip-172-31-11-9:2181
9 总结
1.使用Cloudera提供的Phoenix Parcel,可以很方便的安装Phoenix,而且Cloudera会提供正式的官方支持。
2.使用Phoenix可以对HBase进行建表,删除,更新等操作,都是以大家熟悉的SQL方式操作。
3.Phoenix提供了批量导入/导出数据的方式。批量导入只支持csv格式,分隔符为逗号。
4.Phoenix中的SQL操作,可以马上同步到HBase,通过hbase shell检查都成功
5.Phoenix提供的SQL语法较为简陋,没有insert/update,一律用upsert代替。
6.使用upsert插入数据时,只能一条一条插入,没法将全部字段值写到一个“values”后面。