Hadoop从入门到精通系列之--2.本地模式和伪分布模式
目录
一 Hadoop本地模式和伪分布式模式概述
二 Hadoop伪分布式环境搭建
2.1步骤分析
2.2配置集群
2.3启动集群
2.4 配置YARN
2.5启动集群(带YARN)
2.6查看YARN
三 在集群上运行第一个程序
3.1 准备wordcount程序
3.2历史服务器配置
一 Hadoop本地模式和伪分布式模式概述
安装了Hadoop环境之后,只是搭建了一台服务器,也就是说只是在虚拟机中安装了一台Linux服务器,在大数据集群中,像这样的服务器有几千台甚至几万台,对于Hadoop的学习,也是从1到多的过程。Hadoop的本地模式和伪分布式模式都是在一台服务器上实现的,而真正的大数据环境叫完全分布式环境,至少需要三台服务器,这个后面再说。
本地模式:无需了解
伪分布式模式:在一台服务器上模拟出多台服务器的情况,所以这个伪的由来就是在一台服务器上可以模拟出多台服务器同时运作的情况,其实这个也不是很重要,但是对于后面完全分布式模式的搭建还是很有帮助的。
二 Hadoop伪分布式环境搭建
2.1步骤分析
在分析步骤之前还是回顾一下Hadoop框架,首先Hadoop框架的2大特点:存储和计算,所以这个实验也是围绕这两点,怎么存储(HDFS的增删改查)和怎么计算(WordCount案例)这个地方结合这两个案例搭建这个环境。
- 配置集群
- 启动集群,测试集群,HDFS案例
- 在集群上进行计算,WordCount案例
2.2配置集群
这里配置三处:
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
为什么要配置这三个文件呢?第一个是配置Hadoop中的jdk位置,因为Hadoop的运行依靠jdk;第二处需要指定Hadoop运行过程中产生的文件的存储位置;第三处需要指定HDFS副本的数量,什么是副本呢,是这样的,HDFS之所以用来存储大数据,有一个重要的特点就是它上面的数据不止一份,而是很多份,这就叫副本。
(1)定位到hadoop目录
cd /opt/module/hadoop-2.7.2/

(2)进入hadoop配置文件夹
文件夹的位置在etc/hadoop下,cd etc/hadoop

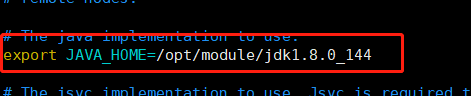
(3)获取jdk路径并配置hadoop-env.sh
echo $JAVA_HOME

vim hadoop-env.sh修改和下图一样
(4)配置core-site.xml
vim core-site.xml至下图一样

(5)配置hdfs-site.xml
vim hadfs-site.xml

2.3启动集群
(1)第一次启动需要格式化namenode,以后不要随便格式化
bin/hadoop namenode -format
既然是格式化NameNode,还记得NameNode吗?HDFS的成员之一,存的是元数据,还有印象吗?既然是对集群的具体操作,那么命令就在bin下面。
之前在解释hadoop目录时说到过,bin目录中是操作集群具体操作的命令
sbin中是启动关闭集群的命令,对初学者来说分清楚这两个这是很重要的
![]()
(2)启动NameNode
sbin/hadoop-daemon.sh start namenode
既然是启动集群,那么命令在sbin下面,这里启动NameNode干什么呢?还记得吗?HDFS的三大成员:分别是NameNode,DataNode,SecondaryNameNode。下图中jps是查看进程的意思。

(3)启动DataNode
sbin/hadoop-daemon.sh start datanode

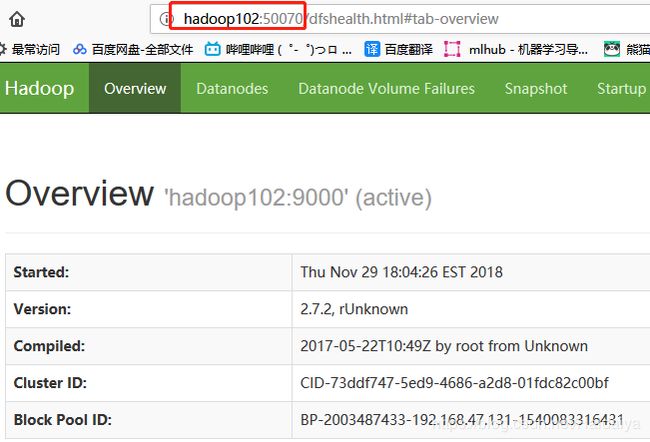
(4)查看集群启动情况
可以使用jps查看,也可以在windows浏览器上输入http://hadoop101:50070查看,如下图所示则你的Hadoop运行健康,记住50070这个端口号
(5)往集群上存储一个自己的文件吧
bin/hdfs dfs -mkdir -p /user/wanglei/input
这个命令解释一下,首先是对集群的操作,所以命令在bin中,因为是对hdfs的操作,所以是hdfs,后面的就是在Linux上创建文件夹的命令。



见到上图表示成功。
(6)上传文件
bin/hdfs dfs -put wcinput/input.txt /user/wanglei/input
这个命令还是值得讲的,这时候脑袋里估计有点乱了,因为涉及到了两个路径,前面一个是我们电脑上的地址,是我们想要上传的源文件,后面一个地址是我们集群的文件系统,是我们上传的位置。


这里顺便把其他的一些命令也一并讲解一下把
上传 bin/hdfs dfs -put wcinput/input.txt /user/wanglei/input
下载 bin/hdfs dfs -get /user/wanglei/input
查看 bin/hdfs dfs -cat /user/wanglei/input
删除 bin/hdfs dfs -rm -r /user/wanglei/input
2.4 配置YARN
刚刚体验了HDFS,现在体验一下Hadoop的另一个部分YARN,YARN的配置需要配置4个文件
- yarn-env.sh
- yarn-site.xml
- mapred-env.sh
- mapred-site.xml
前面两个都比较好理解,yarn的环境变量和核心配置,后面的mapred是什么呢?在介绍YARN这个部分的时候,它的组成有四个:ResourceManager,NodeManager,ApplicationMaster,Container。其实更重要的是Hadoop的计算MapReducer是基于YARN计算的,这个怎么说呢?YARN的四大组件都是各种管家,资源分配,这些组建都在为集群上的任务做服务,所以想要启动YARN,是需要配置MapReducer的
(1)配置yarn-env.sh
配置如下:

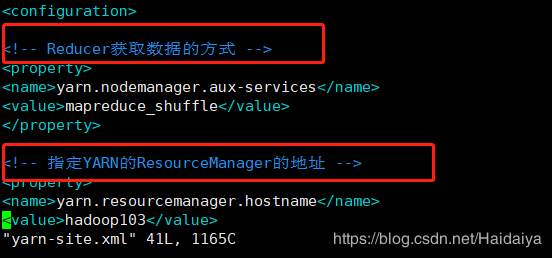
(2)配置yarn-site.xml
配置如下:
(3)配置mapred-env.sh
配置如下

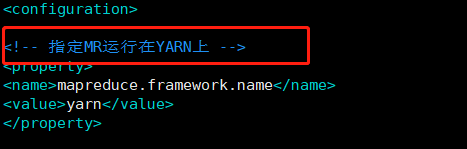
(4)配置mapred-site.xml
2.5启动集群(带YARN)
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
这两个命令应该很好理解,启动YARN中的两大管家,ResourceManager和NodeManager

2.6查看YARN
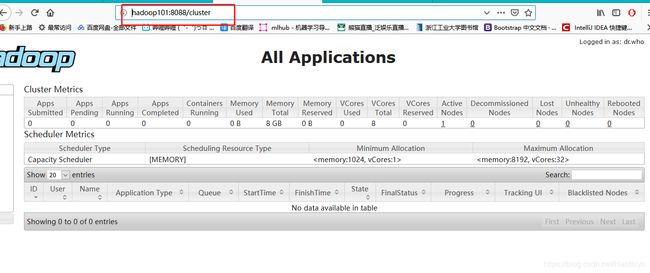
浏览器输入http://hadoop101:8088 查看,可以看到这个集群上的任务情况。这里声明一下,YARN可以看作资源调度器,或者说这个大数据计算的调度器,如下图,All Application表示所有的任务。
三 在集群上运行第一个程序
3.1 准备wordcount程序
wordcount程序就是统计一个文件中单词个数的程序。
(1)上传一个文件到集群上
这个文件中都是单词
![]()

(2)运行程序

(3)在yarn上查看这个程序

上图显示SUCCEEDED表示运行成功了即可。上图红框圈出的那一块History点进去是没有用的,需要在配置文件中配置。
3.2历史服务器配置
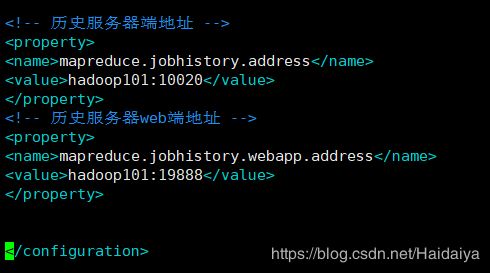
(1)配置mapred-site.xml文件

(2)配置如下图
(3)启动历史服务器
sbin/mr-jobhistory-daemon.sh start historyserver

(4)查看历史服务器
