Hive实战:将xml文件处理为txt文件,并用Hive进行微博数据分析
-
- 一 -xml文件处理
- 1. 文件简述
- 2. xml处理代码
- 3. 遇见的问题及解决过程
- (i) - 之类的字符无法解析
- (ii) -0xc,0x11之类的字符无法解析
- (iii) -java.lang.OutOfMemoryError: Java heap space
- 二 -写到txt
- file工具代码(io版)
- 五 -建表加载数据
- 加载数据:
- 报错:要加载的数据格式与目标表的格式不同
- 查询报错:apps/hive/warehouse/db_wh_test.db/weibo2/weibo_3500014.txt is not a Parquet file.
- 最终建表的SQL语句:
- 加载数据:
- 六 -相关统计结果分析
- 七 -参考
- 八、 -备注:
- 一 -xml文件处理
一 -xml文件处理
1. 文件简述
源文件来自NLPIR微博博主语料库。数据是xml文件
文件解压后389MB,将近1100万行数据,每个人的数据由14个节点组成
其他(见本文末尾:关于文件)
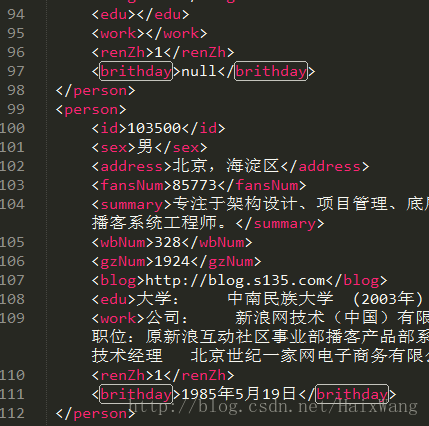
2. xml处理代码
package per.wanghai;
/**
* @author 王海[https://github.com/AtTops]
* @version V1.0
* @package per.wanghai
* @Description
* @Date 2017/10/20 20:50
*/
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.IOException;
import java.util.Iterator;
import java.util.List;
public class XmlTxt {
private String TXT_FLIENAME = "weibo_3500014.txt";
String XML_FLIENAME = "D:/JavaStudy/myudf/src/main/weibo_3500014.xml";
// 对程序运行时间进行记录
long startTime = System.currentTimeMillis();
// 调用同一个包中的WriteToFile类的createFlies方法,返回file
File file_return = WriteToFile.createFile(TXT_FLIENAME);
// 调用WriteToFile类的BufferedWriter方法,返回buffWriter
BufferedWriter buffWriter = WriteToFile.openBufferedWriter(file_return);
/**
* @throws Exception
*/
private void test() throws Exception {
// 创建SAXReader对象
SAXReader reader = new SAXReader();
// 读取文件,转换成Document
Document document = reader.read(new File(XML_FLIENAME));
// 获取根节点元素对象
Element root = document.getRootElement();
/* elementiterator() 方法获取是该节点的孩子节点。
但某个孩子节点还有子节点,这些子节点并不在这个方法获取的节点中
(也就是说这里我们获取所有的节点)
*/
Iterator iterator = root.elementIterator();
while (iterator.hasNext()) {
Element node = iterator.next();
// 同时迭代当前节点下面的所有一级子节点(我们这里person节点的子节点再无子节点)
List listElement = node.elements();
for (Element e : listElement) {
// 获取该节点下的信息
getMassages(e);
}
// 一个person节点读取完毕,文件换行。然后读取下一个节点的信息
buffWriter.newLine();
}
// 所有节点读取并写入完毕
buffWriter.flush();
buffWriter.close();
long consumed_time = (System.currentTimeMillis() - startTime) / 1000;
System.out.println("程序运行完毕!,共消耗" + consumed_time + "秒!!!");
}
private void getMassages(Element node) throws IOException {
/* 测试用
System.out.println("当前节点的名称:" + node.getName());
*/
if (!(node.getTextTrim().equals(""))) {
// 如果当前节点内容不为空,则输出;否则输出“null”
// 为了避免在hive分割字符串时出错,我用 (`) 作分隔符
String str1 = node.getText() + "`";
buffWriter.write(str1);
} else {
String str2 = "null" + "`";
buffWriter.write(str2);
}
}
public static void main(String[] args) {
XmlTxt xmlTxt;
xmlTxt = new XmlTxt();
try {
xmlTxt.test();
} catch (Exception e) {
e.printStackTrace();
}
}
}
3. 遇见的问题及解决过程
(i) - 之类的字符无法解析
解决办法:在根节点PERSONS前加上:(转义符的原因,markdown中表示有误,就上图了)
参考自:参考1(见末尾参考目录)

(ii) -0xc,0x11之类的字符无法解析
- 解析xml文件的过程中,每隔几万行(总共近1100万行)就会出现0xc,0x11之类dom4j无法解析的字符
- 解决过程:是的,我是运行一次,找一次,删除一次。。。
(iii) -java.lang.OutOfMemoryError: Java heap space
- 删除无法解析的字符几十次时,运行好久没有再报错误,以为搞定了。又来了个JVM错误
- 参考原因:JVM中如果98%的时间是用于GC且可用的, Heap size不足2%的时候将抛出此异常信息。
JVM堆的设置是指java程序运行过程中JVM可以调配使用的内存空间的设置.JVM在启动的时候会自动设置Heap size的值,其初始空间(即-Xms)是物理内存的1/64,最大空间(-Xmx)是物理内存的1/4。
可以利用JVM提供的-Xmn -Xms -Xmx等选项可进行设置。Heap Size 最大不要超过可用物理内存的80%,一般的要将-Xms和-Xmx选项设置为相同,而-Xmn为1/4的-Xmx值。
Heap size的 -Xms -Xmn 设置不要超出物理内存的大小。否则会提示“Error occurred during initialization of VM Could not reserve enough space for object heap”。- 尝试解决办法:IDEA中安装目录bin目录下有个idea64.exe.vmoptions文件,修改-Xmx值
但是修改后依然报错,也没看见IDEA界面右下角的数值占用多大
最终解决办法:实在无奈,我把文件切割了,最后只用了 3500014条数据,
也就是25万条数据
二 -写到txt
- 查看部分数据:sed -n “3500010,3500019p” NLPIR微博博主语料库.xml
- 将前3500014条数据写入到新的文件:head -n 3500014 NLPIR微博博主语料库.xml > /usr/wanghai/7z/weibo_3500014.xml
- 在文件尾部添加PERSONS节点:echo ” < PERSONS>” >> /usr/wanghai/7z/weibo_3500014.
- 查看下新文件的末尾数据:tail /usr/wanghai/7z/weibo_3500014.xml
- 在IDEA中重新运行,解析数据
- 数据查看:
- 流编辑器sed命令补充示例:
1、删除文档的第一行
sed -i ‘1d’ /filepath(1可以替换为任意数字,可实现删除任意一行数据)
2、删除文档的最后一行
sed -i ‘$d’ /filepath
3、在a文件的第n行插入”add”
sed -i “niecho “add”” /filepath
4、more:http://man.linuxde.net/sed

file工具代码(io版)
package per.wanghai;
import java.io.*;
/**
* @author 王海[https://github.com/AtTops]
* @version V1.0
* @package per.wanghai
* @Description
* @Date 2017/10/21 10:12
*/
// 缺省class:package-private
class WriteToFile {
/**
* @param str
* @return file
*/
static File createFile(String str){
File file=new File("D:/JavaStudy/myudf/src/main",str);
if(file.exists()){
file.delete();
System.out.println("文件已刪除");
try {
file.createNewFile();
} catch (IOException e) {
System.out.println(e+"删除后再创建出错");
}
System.out.println("删除后文件已创建");
}
else{
try{
file.createNewFile();
System.out.println("文件已创建");
}catch(Exception e){
e.printStackTrace();
}
}
//FileOutputStream out=new FileOutputStream(“d:/myjava/write.txt ");
return file;
}
/**
* @param file
* @return BufferedWriter
*/
static BufferedWriter openBufferedWriter(File file){
// 用BufferedWriter来写,它写入的是字符,所以不会仅写入一个字节,不会出现乱码(在处理字符流时涉及了字符编码的转换问题).
OutputStreamWriter outputStream = null;
try {
outputStream = new OutputStreamWriter(new FileOutputStream(file));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
// 自定义缓冲区大小4096B
BufferedWriter buffWriter = new BufferedWriter(outputStream,4096);
return buffWriter;
}
}
五 -建表加载数据
加载数据:
报错:要加载的数据格式与目标表的格式不同
解决过程:
1.看是不是每条数据的最后一个“`”导致了问题(删除后仍旧报错,排除)
2.改分隔符(仍旧报错,排除)
3.所有字段改为STRING(仍旧报错,排除)
4.所有字段加上“”(仍旧报错,排除)
5.改存储格式(OK,排除前4点的错误)
6.修改为TEXTFILE格式和PARQUET都能成功加载数据
查询报错:apps/hive/warehouse/db_wh_test.db/weibo2/weibo_3500014.txt is not a Parquet file.
解决过程:
- 将数据重新复制到本地。。。:sudo -u hdfs hadoop fs -get apps/hive/warehouse/db_wh_test.db/weibo2/weibo_3500014.txt /usr/wanghai
- 重新加载数据为TEXTFILE格式
最终建表的SQL语句:
- CREATE TABLE IF NOT EXISTS db_wh_test.weibo1(
id INT COMMENT “innal ip”,
sex STRING,
address STRING,
fansNum INT,
summary STRING,
wbNum INT COMMENT “number of weibo”,
ationNum INT COMMENT “number of personal attention”,
blogaddr STRING COMMENT “address of weibo”,
edu STRING,
work STRING,
authentication TINYINT COMMENT “1 for authentication and 0 for unauthorized”,
brithday STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘`’
STORED AS TEXTFILE;- 查看表结构:desc formatted weibo1;
- (查看表大小发觉之前存储的parquet格式的表与TEXTFILE格式的大小一样,都是46.6M,这也是没有成功存储为parquet格式文件的信号吧?
)
- 查询以验证数据:select count(*) count_num from weibo1;成功,共25万条数据
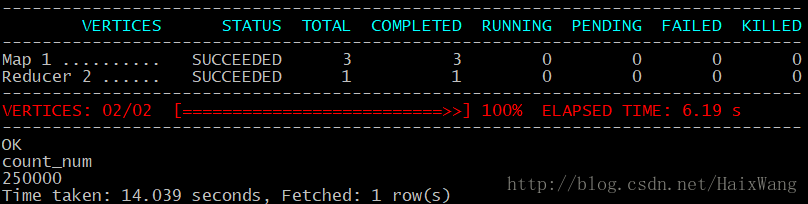
六 -相关统计结果分析
林子大了。用户写的什么样的数据都有。。。
注:以下信息仅仅为本人(菜鸟)出自学习目的,对部分微博数据做出的简单分析,不代表官方意见,不保证真实有效!!!
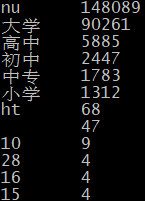
- 教育经历:
除近15万人没有填写外,接受高等教育的程度与相应人数成正比:
- 发文数量与粉丝数量没什么正比关系,粉丝超千万的有两位,原以为第二位也会是女的,结果不然。去微博主页一看,是李开复老师。。。
- 年龄分布:大部分为80后,90以及00后较少,
90后中最多的是分别是90:6327人;91:2981人;92:2119人- 按地区分类:
注册人数最多的两地:北京 55662 ; 广东 34220
其中:
北京总发文数:4655万余次;粉丝总数28109万余人
广东总发文数:3317万余次;粉丝总数9522万余人(相比之下,北京文章好像“性价比”高一些)
注册人数最少的两地:澳门 2;西藏 2- 男士:129611 ; 女: 70389 (看来当年微博注册必须填写性别,且只有两选项)
- 等等
七 -参考
- 关于文件:
1.NLPIR微博博主语料库由北京理工大学网络搜索挖掘与安全实验室张华平博士,通过公开采集与抽取从新浪微博、腾讯微博中获得。为了推进微博计算的研究,现通过自然语言处理与信息检索共享平台(www.nlpir.org)予以公开共享其中的100万条数据(目前已有数据接近1亿,已经剔除了大量的冗余与机器粉丝)
2.本语料库在公开过程中,已经最大限度地采用技术手段屏蔽了用户真实姓名和url,如果涉及到的用户需要全面保护个人隐私的,可以Email给张华平博士[email protected]予以删除,对给您造成的困扰表示抱歉,并希望谅解;
3.只适用于科研教学用途,不得作为商用;引用本语料库,恭请在软件或者论文等成果特定位置表明出处为:NLPIR微博语料库,出处为自然语言处理与信息检索共享平台(http://www.nlpir.org/)。- 参考1
- io(csdn博客)
- jvm常用参数
- 正则表达式速查表
- 刚接触到的一个不错的工具网站(http://www.sojson.com/regex/generate)
八、 -备注:
1.待做:搞清楚为什么用别的存储格式会失败,使用别的存储格式分别有什么前提条件
2.遗憾:本想用大一点的文件,使用别的存储格式以及压缩格式,以探索所谓的是否可split,由于各种原因,没能实现。