Spark中DataFrame版的相关系数计算——DataFrameStatFunctions,Spark线性回归pipline
文章目录
- 前言:
- 代码
- 注意
- Spark线性回归pipline
- 参考
前言:
很多人还在实用RDD的相关API,为跟上“未来”,咱讨论下DataFrame版的相关API。
MLlib 的基于 RDD 的 API 现在处于维护状态。
从 Spark 2.0 开始, spark.mllib 包中的基于 RDD 的 API 已经进入了维护模式。Spark 的主要的机器学习 API 现在是 spark.ml 包中的基于 DataFrame 的 API 。
有什么影响?
MLlib 仍将支持基于 RDD 的 API ,在 spark.mllib 中有 bug 修复。
MLlib 不会为基于 RDD 的 API 添加新功能。
在 Spark 2.x 发行版本中, MLlib 将向基于 DataFrames 的 API 添加功能,以达到与基于 RDD 的 API 的功能奇偶校验。
在达到功能奇偶校验(大概估计为 Spark 2.3 )之后,基于 RDD 的 API 将被弃用。
预计将在 Spark 3.0 中删除基于 RDD 的 API 。
为什么 MLlib 切换到基于 DataFrame 的 API ?
DataFrames 提供比 RDD 更加用户友好的 API 。 DataFrames 的许多好处包括 Spark Datasources,SQL/DataFrame 查询,Tungsten 和 Catalyst 优化以及跨语言的统一 API 。
用于 MLlib 的基于 DataFrame 的 API 为 ML algorithms (ML 算法)和跨多种语言提供了统一的 API 。
DataFrames 便于实际的 ML Pipelines (ML 管道),特别是 feature transformations (特征转换)。有关详细信息,请参阅 Pipelines 指南 。
##正文
在将数据“喂”给模型之前,预处理中很重要的一步是去除冗余数据。
关于计算相关系数前是否需要将数据标准化:
大部分人表示“可以不用,因为相关系数本身就是一个标准化的统计量,协方差可以用来表示变量间共同变化的程度,而相关系数是协方差标准化后得到的统计量。”
我还没求证,等放上几天,我再比较不同结果得下结论。
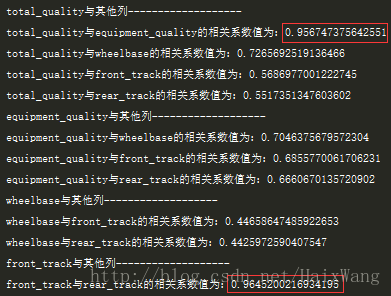
- 想想含有n个特征的数据集,计算一个n X n的相关系数矩阵【我只计算了对角线的一侧,因为X与Y和Y与X的相关系数是相等的】,并将结果保存在Double二维数组中。可以看到,部分列之间的相关性确实很高。但别急,现在还不能删,因为我们还不知道删除哪一个变量更为合理。
- 对数组中的数处理为绝对值之后复制一份,对副本进行排序(NaN之前已经被处理为0),每次取复制的数组中的第一个值(前提是大于阈值0.8);在二维数组中找到对应的两个变量记为indexX和indexY
- 计算indexX和其他所有变量的相关系数的绝对值之和,记为sumX;同理,对indexY,记为sumY。比较,删除sum值较大的那一个变量(对于DataFrame删)
- 重复2-3步骤,直到处理完复制的数组中的所有大于阈值的值
- 保存清洗过后的数据
代码
其实不想贴代码,因为代码不“漂亮”,有较多的for循环。一方面是对scala还不能灵活运用,一方面没找到DataFrame中直接对变量矩阵进行运算得出相关系数矩阵的方法。所以就自己用for循环造了。
package main.scala.firstput
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* @author 王海[https://github.com/AtTops]
* package main.scala.firstput
* description 计算相关性矩阵,将大于阈值0.8的挑选删除
* Date 2018/1/2 9:35
* Version V1.0
*/
object GetCorrelationMartix {
var myTrainCsvPath: String = "yourpath"
var secondTrainCsvPath: String = "yourpath"
/**
* 使用DataFrameStatFunctions中的API
* TODO:参考mlib中的correlationExample.scala,修改为矩阵运算
*/
def correlationAndCleanAgain_w(columnNames: Array[String], dataFrame: DataFrame): DataFrame = {
// 计算一个n X n的相关系数矩阵【我只计算了对角线的一侧】,并将结果保存在Double二维数组中
val storeCorrsMatrix = Array.ofDim[Double](columnNames.length, columnNames.length) // 使用ofDim创建二维数组
var tempDf: DataFrame = dataFrame
for (i <- 0 until columnNames.length - 1) { // 我们仅计算矩阵对角线一侧就行
// println(f"${columnNames(i)}%5s 与其他列-------------------------------------------") // 这里的f插值没有起作用
for (j <- i + 1 until columnNames.length) {
var corrValue: Double = dataFrame.stat.corr(columnNames(i), columnNames(j))
if (corrValue < 0)
corrValue = corrValue.abs // 处理为绝对值
else if (corrValue.isNaN)
corrValue = 0 // NaN处理为0
/* if (corrValue > 0.8)
println(s"${columnNames(i)}与${columnNames(j)}的相关系数值为:$corrValue") // s字符串插值器,scala2.10添加*/
storeCorrsMatrix(i)(j) = corrValue
}
}
println("它应该是0:" + storeCorrsMatrix(5)(5) + " ;它应该是0.9645:" + storeCorrsMatrix(22)(23)) // 简单验证
val corrsMatrixClong: Array[Double] = storeCorrsMatrix.flatten.sortWith(_ > _) // 二维数组按行拼接为一维数组,然后从小到大排序
// storeCorrsMatrix.copyToArray(corrsMatrixClong, 0)
/*println("storeCorrs数组的长度为:" + storeCorrs.length) // 276(23+22+21+...1)
println("front_track与rear_track的相关系数值为:" + storeCorrs(storeCorrs.length-1))*/
// println(corrsMatrixClong.mkString(" "))
println(corrsMatrixClong.length) // 576=24*24
// 每次取复制的数组中的第一个值(前提是大于阈值0.8);在二维数组中找到对应的两个变量的位置记为valueX和valueY
// 为了简便,我取的下标,因为我这里就8个大于阈值0.8的数
for (i <- 0 to 7) {
val indexArray: Array[Int] = findIndexByValue_w(storeCorrsMatrix, corrsMatrixClong(i))
val indexX = indexArray(0)
val indexY = indexArray(1)
var sumX: Double = 0.0
var sumY: Double = 0.0
// 计算sumX
for (m <- 0 to indexX) { // 为避免indexX=0,这里没使用until(因为对角线上的值都为0,让它加吧)
sumX += storeCorrsMatrix(m)(indexX)
}
if (indexX != 23) {
for (n <- indexX + 1 to 23) {
sumX += storeCorrsMatrix(indexX)(n)
}
}
// 计算sumY
for (m <- 0 until indexY) {
sumY += storeCorrsMatrix(m)(indexY)
}
if (indexY != 23) {
for (n <- indexY + 1 to 23) {
sumY += storeCorrsMatrix(indexY)(n)
}
}
// 删除sumX和sumY中较大的对应的变量(indexX或indexY对应的变量)
if (sumX > sumY) {
tempDf = tempDf.drop(columnNames(indexX))
println(s"删除掉: ${columnNames(indexX)}")
}
else {
tempDf = tempDf.drop(columnNames(indexY))
println(s"删除掉: ${columnNames(indexY)}")
}
}
// 返回清理完选择出的变量之后的DataFrame
tempDf
}
/**
* 在原相关系数矩阵中找给定的相关系数值的对应的2个变量
* return: 返回二维数组的下标(就是对应的2个变量的位置)
* TODO:corr值不唯一怎么办?极小概率事件吧?
*/
def findIndexByValue_w(storeCorrsMatrix: Array[Array[Double]], corrValue: Double): Array[Int] = {
val corrIndex: Array[Int] = new Array[Int](2)
var flag: Boolean = true
for (i <- 0 to 22) {
for (j <- i + 1 to 23 if flag) {
if (storeCorrsMatrix(i)(j) == corrValue) { // Scala没有三目运算符,对break跳出循环的支持也不太“优美”(抛出异常)
corrIndex(0) = i
corrIndex(1) = j
println(s"$corrValue index_i is $i ,index_j is $j")
flag = false
}
}
}
corrIndex
}
/**
* 计算相关系数的主要函数
*/
def correlationForEach_w(csvPath: String, spark: SparkSession): Unit = {
// 获取数据
val rawTrainDf: DataFrame = spark.read.format("csv").option("header", true).option("inferSchema", true).load(myTrainCsvPath)
// rawTrainDf.printSchema()
// rawTrainDf.show()
// 设置哪些是特征,哪个是标签,但是还没有开始转换
/* val assembler = new VectorAssembler()
.setInputCols(Array(""))
.setOutputCol("features")
// 开始转换
val output = assembler.transform(rawTrainDf)
output.select("features", "sale_quantity").show*/
val columnNames: Array[String] = rawTrainDf.columns
// 计算相关系数
val cleanAgainDf = correlationAndCleanAgain_w(columnNames, rawTrainDf)
rawTrainDf.printSchema()
println("======================================================================")
cleanAgainDf.printSchema()
cleanAgainDf.coalesce(1)
.write
.mode("overwrite")
.option("header", true)
.format("csv")
.save(secondTrainCsvPath)
println("训练集保存完毕,保存路径————————:" + secondTrainCsvPath)
spark.close()
}
def main(args: Array[String]): Unit = {
// 避免大量INFO信息干扰,必须设置在开头
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val spark = SparkSession.builder()
.master("local")
.appName("SomeStatistics")
.config("spark.some.config.option", "some-value")
.getOrCreate()
correlationForEach_w(myTrainCsvPath, spark)
}
}
注意
- 如果你想单独测试DataFrame版相关系数的使用,除了以上方法。你可能还会使用ml.stat.Correlation中的corr,但是这个方法是Spark2.2.0中才添加的。所以开发时最好使用和你的Spark集群版本一样的Spark
- ML目前只支持Pearson计算相关系数。对于Spearman,请考虑使用MLlib中基于的RDD方法。
- 以上只考虑了特征两两之间的相关性,忽视了多个变量之间的相关性,所以具体问题还需要具体对待,没有确定的标准做法。
Spark线性回归pipline
package main.scala.firstput
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.param.ParamMap
import org.apache.spark.ml.regression.LinearRegression
import org.apache.spark.ml.tuning.{CrossValidator, ParamGridBuilder}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
/**
* @author 王海
* package main.scala.firstput
* description 这是第一个版本,没有结合字符串类型(使用StringIndexer);
* 没有处理分类变量(使用VectorIndexer(向量类型索引化));也没有使用独热编码OneHotEncoder;
* Date 2018/1/4 20:40
* Version V1.0
*/
object LrPipline {
val myTrainCsvPath: String = "E:\\tianchi\\yanc_car\\46m\\my_train_2\\part-00000-da20454d-07fc-4613-bccf-3c9e01c67466.csv"
val myCVPath: String = "E:\\tianchi\\yanc_car\\46m\\Models\\cvmodel"
val myTestCsvPath: String = "E:\\tianchi\\yanc_car\\46m\\mytest.csv"
val resultsPath: String = "E:\\tianchi\\yanc_car\\46m\\results"
/**
* 目前可以使用CrossValidator和TrainValidationSplit这两种方式调整参数,前者慢后者快,
* 但是后者在数据集小时表现得可能不好(TrainValidationSplit只对一次参数的每个组合进行评估,而在CrossValidator的情况下则为k次。)
*
* @param spark
*/
def piplineWithCrossValidator(spark: SparkSession): Unit = {
var rawTrainDf: DataFrame = spark.read.format("csv").option("header", true).option("inferSchema", true).load(myTrainCsvPath)
rawTrainDf = rawTrainDf.withColumnRenamed("sale_quantity", "label").na.drop().drop("type_id").drop("department_id").drop("emission_standards_id").drop("if_MPV_id").drop("if_luxurious_id")
rawTrainDf.printSchema()
rawTrainDf.createOrReplaceTempView("rawdata")
val myTrainDf: DataFrame = spark.sql("SELECT * FROM rawdata WHERE sale_date > 201609.0")
// 将多个特征变量合并成一个特征变量,以用于输入之后的模型
// 该方法可以将原始特征和不同特征transformers(转换器)生成的特征合并为单个特征向量
val calArray = Array("sale_date", "class_id", "brand_id", "compartment", "TR", "displacement", "driven_type_id", "cylinder_number", "engine_torque", "car_length", "car_height", "total_quality", "rear_track")
val assembler = new VectorAssembler() // 设置哪些是特征,剩下的是标签,但是还没有开始转换
.setInputCols(calArray)
.setOutputCol("features")
val output = assembler.transform(myTrainDf)
output.select("features", "label").show
// 初步建立线性回归模型
val lr = new LinearRegression()
// .setFeaturesCol("features") // 也可以不这样做,因为之前的assemble人已经指明了哪些是特征列。后面的setStages(Array(lr))用setStages(Array(assembler,lr))代替
// .setLabelCol("sale_quantity") // 所有数值类型会自动转为double型(所以不用自己去处理为double型)
// .fit(output)
// 使用ParamGridBuilder构建参数网格
val paramMap = new ParamGridBuilder() // 这些参数可以在LinearRegression类中的Parameters找到
.addGrid(lr.regParam, Array(0.1, 0.005, 0.01)) // 正则化参数,默认0.0
.addGrid(lr.elasticNetParam, Array(0.1, 0.25, 0.5, 0.75, 0.9)) // 给L1、L2正则化的结合版设置3种需要尝试的参数(默认0.0,仅L2正则)
.addGrid(lr.maxIter, Array(10, 20))
.build()
// 构建管道,把各个阶段连接在一起(这里就一个)
val pipeline = new Pipeline()
.setStages(Array(assembler, lr))
// 模型评估以及选择
val cv = new CrossValidator()
.setEstimator(pipeline)
.setEvaluator(new RegressionEvaluator)
.setEstimatorParamMaps(paramMap)
.setNumFolds(4)
val cvModel = cv.fit(rawTrainDf)
// 打印模型相关参数
println("extractParamMap=============================")
val params: ParamMap = cvModel.extractParamMap() // 打印“冻结”的所有参数
params.toSeq.foreach {
print
}
// cvModel.getDefault()
println("extractParamMap.length=============================")
println(cvModel.getEstimatorParamMaps.length)
println("foreach=============================")
cvModel.getEstimatorParamMaps.foreach {
println
} // 参数组合的集合
println(cvModel.getEvaluator.isLargerBetter) // 评估的度量值是大的好,还是小的好
// 测试集准备
var rawTestDf: DataFrame = spark.read.format("csv").option("header", true).option("inferSchema", true).load(myTestCsvPath)
rawTestDf = rawTestDf.drop("sale_quantity").na.drop().drop("type_id").drop("department_id").drop("emission_standards_id").drop("if_MPV_id").drop("if_luxurious_id")
// 测试并且打印结果
println("开始测试===================")
val results: DataFrame = cvModel.transform(rawTestDf)
println("打印预测结果===================")
results.select("class_id", "prediction")
.collect()
.foreach { case Row(id: Double, prediction: Double) =>
println(s"$id ----------> prediction=$prediction")
}
val save: DataFrame = results.select("class_id", "prediction") // 不转换一下的话,报错说csv数据源类型错误
save.coalesce(1)
.write
.mode("overwrite")
.option("header", true)
.format("csv")
.save(resultsPath)
println(s"预测结果保存完毕,保存路径————————>:$resultsPath")
// 保存模型
cvModel.write.overwrite().save(myCVPath)
spark.stop()
}
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val spark = SparkSession.builder()
.master("local")
.appName("SomeStatistics")
.getOrCreate()
piplineWithCrossValidator(spark)
}
}
参考
- ApacheCN
- 孙亮、黄倩《实用机器学习》P85:通过相关系数删除冗余数据
- DataFrameStatFunctions官方doc
- Scala API doc