JAVA类集(1)简单操作
本博文将简单简单讲解JAVA类集的使用.
在整个JAVA类集中,最常用的类集接口是:
Collection,List,Set,Map,Iterator,ListIterator,Enmueration,SortedSet,SortedMap,Queue,Map.Entry

这些接口的继承关系如下:
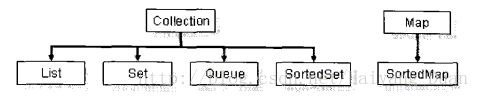
提示:SortedXX接口都是可排序的接口.
一. Collection接口
collection是单值存储的最大父接口


在开发中,往往很少直接使用Collection接口,而是使用其子接口,其子接口有:List,Set,Queue,SortedSet
List:可以存放重复内容
Set:不能存放重复内容,重复对象需使用hashCode()和equals()方法
Queue:队列接口
SortedSet:可以对集合中的数据进行排序
二. List接口
List是Collection的子接口,保存了许多重复的内容,但List也扩展了Collection接口,定义了更多的方法.
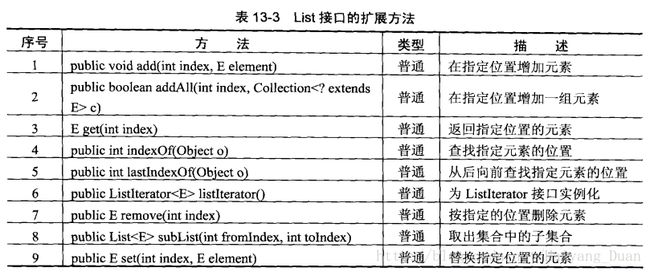
List也是一个接口,要想使用List,必须使用其子类进行实例化.
2.1 子接口—ArrayList
ArrayList是List的接口,可以直接使用ArrayList为List接口实例化.
向集合中增加元素:
//Collection的方法
public boolean add(E o);
public boolean addAll(Collection c);
//也可以直接使用List特有的方法
public void add(int index,E element); 删除元素:
//Collection的方法
public boolean remove(Object o);
public boolean removeAll(Collection c);
//也可以直接使用List特有的方法
public E add(int index);注意:
如果自定义的类使用上述方法进行删除元素,则必须覆写Object类的equals()和hashCode()方法.
输出List中的内容:
//使用两个方法在配合for循环可以遍历List的输出
//collection中的size()
//List中的get(int index)将集合变为对象数组
//Collection的toArray()方法2.2 Vector
从JAVA的整个发展历程来看,Vector是一个元老级的类,在JDK1.0就 已经存在.到了JAVA2之后,重点强调了集合框架的概念,所以定义了很多新的接口,但是考虑到一部分人已经习惯了使用vector,所以就让其实现了List接口,将其保留了下来.
如果直接使用Vector实例化List,那么其使用与ArrayList没没有太大差别,但是Vector由于出现比较早,其自身也有一些List没有的方法.
ArrayList与Vector的区别:

2.3 LinkedList接口与Queue接口
LinkedList表示链表类,Queue表示的是队列操作,采用先进先出(FIFO)的方式操作.
定义如下:

可以看出,不但实现了List接口,还实现了Queue接口
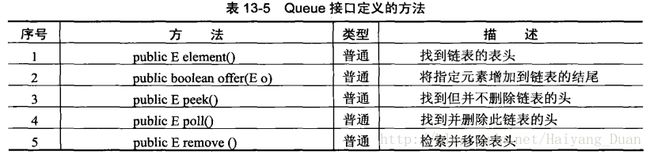
LinkedList除了具有上述队列的方法之外,还具有以下链表的操作方法:

三. Set接口
Set也是Collection的子接口,但是Set并未对Collection进行扩展,只是比Collection接口的要求更加严格了,不能增加重复元素.
此外,Set不能像List那样进行双向输出,因为此接口没有像List接口的get(int index)方法.
3.1 HashSet
HashSet特点:元素不重复,散列存储没有顺序,集合的输出顺序并不是集合的保存顺序
3.2 TreeSet
TreeSet特点:元素不重复,有序存储,向集合中插入时无序,但输出时有序
3.3 关于TreeSet的排序说明
如果自定义的类要对TreeSet中的元素进行排序,因为TreeSet中的元素是有序排放的,所以对于一个对象必须指定其排序规则,且TreeSet每个对象所在的类都必须实现Comparable接口才能正常使用.
自定义Person1类:
class Person1 implements Comparable<Person1>{
private String name;
private int age;
public Person1(){}
public Person1(String name , int age){
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "姓名:" + this.name + " 年龄:" + this.age;
}
@Override
public int compareTo(Person1 p) {
if(this.age > p.age)
return 1;
else if(this.age < p.age)
return -1;
else
return this.name.compareTo(p.name);
}
}package cn.mysql;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
public class CollectionDemo {
public static void main(String[] args) {
Set tree = new TreeSet();
tree.add(new Person2("张三",26));
tree.add(new Person2("李四",25));
tree.add(new Person2("王五",20));
tree.add(new Person2("马六",26));
tree.add(new Person2("张三",26));
tree.add(new Person2("王五",27));
tree.add(new Person2("赵七",26));
System.out.println(tree);
}
} 以上代码可以去掉重复元素,但是靠Comparable实现的,如果换成hashSet则还会出现重复的内容,如果要想真正去掉重复元素,必须深入研究Object类.
要想去掉重复元素,必须首先进行对象是否重复的判断,而要想进行这样的判断,就必须覆写Object类的equals()方法,才能完成对象是否相等的判断,而且只覆写equals()是不够的,还要覆写hashCode()方法,以求出不会重复的哈希码值.
自定义Person2类:
class Person2{
private String name;
private int age;
public Person2(){}
public Person2(String name , int age){
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "姓名:" + this.name + " 年龄:" + this.age;
}
@Override
public boolean equals(Object p) {
if(this == p)
return true;
if(!(p instanceof Person2))
return false;
Person2 pp = (Person2)p;
if(this.name.equals(pp.name) && this.age == pp.age)
return true;
else
return false;
}
@Override
public int hashCode() {
return this.name.hashCode() * this.age;
}
}
package cn.mysql;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
public class CollectionDemo {
public static void main(String[] args) {
Set tree = new HashSet();
tree.add(new Person2("张三",26));
tree.add(new Person2("李四",25));
tree.add(new Person2("王五",20));
tree.add(new Person2("马六",26));
tree.add(new Person2("张三",26));
tree.add(new Person2("王五",27));
tree.add(new Person2("赵七",26));
System.out.println(tree);
}
} $$ : 一个完整的类,最好覆写Object类的toString(),hashCode()和equals()方法