matlab BP神经网络 机器学习 函数逼近
1、BP网络构建
(1)生成BP网络
:由维的输入样本最小最大值构成的维矩阵。
:各层的神经元个数。
:各层的神经元传递函数。
:训练用函数的名称。
(2)网络训练
(3)网络仿真
{'tansig','purelin'},'trainrp'
BP网络的训练函数
| 训练方法 |
训练函数 |
| 梯度下降法 |
traingd |
| 有动量的梯度下降法 |
traingdm |
| 自适应lr梯度下降法 |
traingda |
| 自适应lr动量梯度下降法 |
traingdx |
| 弹性梯度下降法 |
trainrp |
| Fletcher-Reeves共轭梯度法 |
traincgf |
| Ploak-Ribiere共轭梯度法 |
traincgp |
| Powell-Beale共轭梯度法 |
traincgb |
| 量化共轭梯度法 |
trainscg |
| 拟牛顿算法 |
trainbfg |
| 一步正割算法 |
trainoss |
| Levenberg-Marquardt |
trainlm |
BP网络训练参数
| 训练参数 |
参数介绍 |
训练函数 |
| net.trainParam.epochs |
最大训练次数(缺省为10) |
traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlm |
| net.trainParam.goal |
训练要求精度(缺省为0) |
traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlm |
| net.trainParam.lr |
学习率(缺省为0.01) |
traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlm |
| net.trainParam.max_fail |
最大失败次数(缺省为5) |
traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlm |
| net.trainParam.min_grad |
最小梯度要求(缺省为1e-10) |
traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlm |
| net.trainParam.show |
显示训练迭代过程(NaN表示不显示,缺省为25) |
traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlm |
| net.trainParam.time |
最大训练时间(缺省为inf) |
traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlm |
| net.trainParam.mc |
动量因子(缺省0.9) |
traingdm、traingdx |
| net.trainParam.lr_inc |
学习率lr增长比(缺省为1.05) |
traingda、traingdx |
| net.trainParam.lr_dec |
学习率lr下降比(缺省为0.7) |
traingda、traingdx |
| net.trainParam.max_perf_inc |
表现函数增加最大比(缺省为1.04) |
traingda、traingdx |
| net.trainParam.delt_inc |
权值变化增加量(缺省为1.2) |
trainrp |
| net.trainParam.delt_dec |
权值变化减小量(缺省为0.5) |
trainrp |
| net.trainParam.delt0 |
初始权值变化(缺省为0.07) |
trainrp |
| net.trainParam.deltamax |
权值变化最大值(缺省为50.0) |
trainrp |
| net.trainParam.searchFcn |
一维线性搜索方法(缺省为srchcha) |
traincgf、traincgp、traincgb、trainbfg、trainoss |
| net.trainParam.sigma |
因为二次求导对权值调整的影响参数(缺省值5.0e-5) |
trainscg |
| net.trainParam.lambda |
Hessian矩阵不确定性调节参数(缺省为5.0e-7) |
trainscg |
| net.trainParam.men_reduc |
控制计算机内存/速度的参量,内存较大设为1,否则设为2(缺省为1) |
trainlm |
| net.trainParam.mu |
的初始值(缺省为0.001) |
trainlm |
| net.trainParam.mu_dec |
的减小率(缺省为0.1) |
trainlm |
| net.trainParam.mu_inc |
的增长率(缺省为10) |
trainlm |
| net.trainParam.mu_max |
的最大值(缺省为1e10) |
trainlm |
2、BP网络举例
举例1、
%traingd
clear;
clc;
P=[-1 -1 2 2 4;0 5 0 5 7];
T=[-1 -1 1 1 -1];
%利用minmax函数求输入样本范围
net = newff(minmax(P),[5,1],{'tansig','purelin'},'trainrp');
net.trainParam.show=50;%
net.trainParam.lr=0.05;
net.trainParam.epochs=300;
net.trainParam.goal=1e-5;
[net,tr]=train(net,P,T);
net.iw{1,1}%隐层权值
net.b{1}%隐层阈值
net.lw{2,1}%输出层权值
net.b{2}%输出层阈值
sim(net,P)
举例2、利用三层BP神经网络来完成非线性函数的逼近任务,其中隐层神经元个数为五个。
样本数据:
| 输入X |
输出D |
输入X |
输出D |
输入X |
输出D |
| -1.0000 |
-0.9602 |
-0.3000 |
0.1336 |
0.4000 |
0.3072 |
| -0.9000 |
-0.5770 |
-0.2000 |
-0.2013 |
0.5000 |
0.3960 |
| -0.8000 |
-0.0729 |
-0.1000 |
-0.4344 |
0.6000 |
0.3449 |
| -0.7000 |
0.3771 |
0 |
-0.5000 |
0.7000 |
0.1816 |
| -0.6000 |
0.6405 |
0.1000 |
-0.3930 |
0.8000 |
-0.3120 |
| -0.5000 |
0.6600 |
0.2000 |
-0.1647 |
0.9000 |
-0.2189 |
| -0.4000 |
0.4609 |
0.3000 |
-0.0988 |
1.0000 |
-0.3201 |
解:
看到期望输出的范围是,所以利用双极性Sigmoid函数作为转移函数。
程序如下:
clear;
clc;
X=-1:0.1:1;
D=[-0.9602 -0.5770 -0.0729 0.3771 0.6405 0.6600 0.4609...
0.1336 -0.2013 -0.4344 -0.5000 -0.3930 -0.1647 -.0988...
0.3072 0.3960 0.3449 0.1816 -0.312 -0.2189 -0.3201];
figure;
plot(X,D,'*'); %绘制原始数据分布图(附录:1-1)
net = newff([-1 1],[5 1],{'tansig','tansig'});
net.trainParam.epochs = 100; %训练的最大次数
net.trainParam.goal = 0.005; %全局最小误差
net = train(net,X,D);
O = sim(net,X);
figure;
plot(X,D,'*',X,O); %绘制训练后得到的结果和误差曲线(附录:1-2、1-3)
V = net.iw{1,1}%输入层到中间层权值
theta1 = net.b{1}%中间层各神经元阈值
W = net.lw{2,1}%中间层到输出层权值
theta2 = net.b{2}%输出层各神经元阈值所得结果如下:
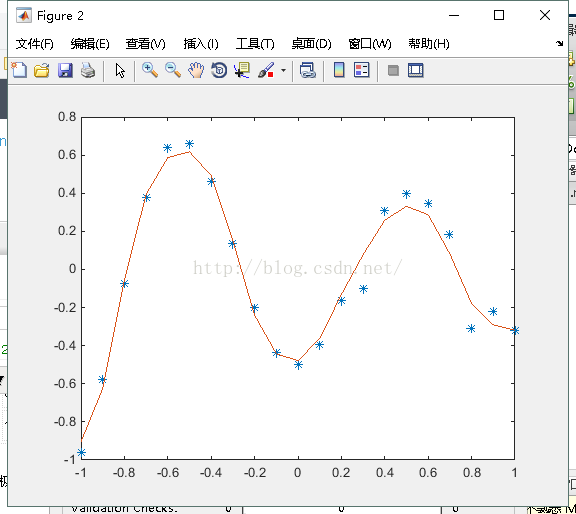
举例3、利用三层BP神经网络来完成非线性函数的逼近任务,其中隐层神经元个数为五个。
样本数据:
| 输入X |
输出D |
输入X |
输出D |
输入X |
输出D |
| 0 |
0 |
4 |
4 |
8 |
2 |
| 1 |
1 |
5 |
3 |
9 |
3 |
| 2 |
2 |
6 |
2 |
10 |
4 |
| 3 |
3 |
7 |
1 |
|
|
解:
看到期望输出的范围超出,所以输出层神经元利用线性函数作为转移函数。
程序如下:
clear;
clc;
X = [0 1 2 3 4 5 6 7 8 9 10];
D = [0 1 2 3 4 3 2 1 2 3 4];
figure;
plot(X,D,'*'); %绘制原始数据分布图
net = newff([0 10],[5 1],{'tansig','purelin'})
net.trainParam.epochs = 100;
net.trainParam.goal=0.005;
net=train(net,X,D);
O=sim(net,X);
figure;
plot(X,D,'*',X,O); %绘制训练后得到的结果和误差曲线(附录:2-2、2-3)
V = net.iw{1,1}%输入层到中间层权值
theta1 = net.b{1}%中间层各神经元阈值
W = net.lw{2,1}%中间层到输出层权值
theta2 = net.b{2}%输出层各神经元阈值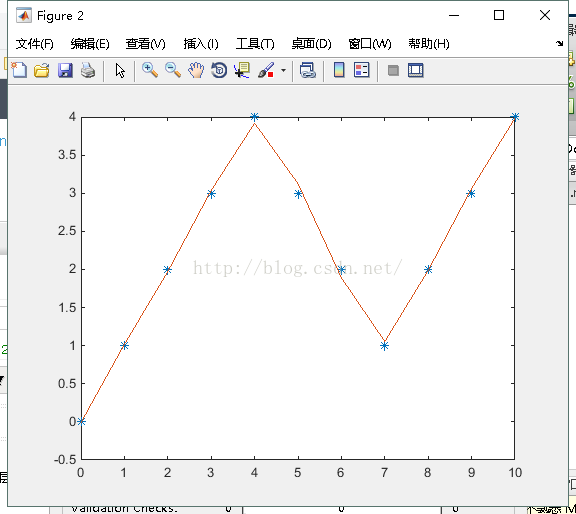
问题:以下是上证指数2009年2月2日到3月27日的收盘价格,构建一个三层BP神经网络,利用该组信号的6个过去值预测信号的将来值。
| 日期 |
价格 |
日期 |
价格 |
| 2009/02/02 |
2011.682 |
2009/03/02 |
2093.452 |
| 2009/02/03 |
2060.812 |
2009/03/03 |
2071.432 |
| 2009/02/04 |
2107.751 |
2009/03/04 |
2198.112 |
| 2009/02/05 |
2098.021 |
2009/03/05 |
2221.082 |
| 2009/02/06 |
2181.241 |
2009/03/06 |
2193.012 |
| 2009/02/09 |
2224.711 |
2009/03/09 |
2118.752 |
| 2009/02/10 |
2265.161 |
2009/03/10 |
2158.572 |
| 2009/02/11 |
2260.822 |
2009/03/11 |
2139.021 |
| 2009/02/12 |
2248.092 |
2009/03/12 |
2133.881 |
| 2009/02/13 |
2320.792 |
2009/03/13 |
2128.851 |
| 2009/02/16 |
2389.392 |
2009/03/16 |
2153.291 |
| 2009/02/17 |
2319.442 |
2009/03/17 |
2218.331 |
| 2009/02/18 |
2209.862 |
2009/03/18 |
2223.731 |
| 2009/02/19 |
2227.132 |
2009/03/19 |
2265.761 |
| 2009/02/20 |
2261.482 |
2009/03/20 |
2281.091 |
| 2009/02/23 |
2305.782 |
2009/03/23 |
2325.481 |
| 2009/02/24 |
2200.652 |
2009/03/24 |
2338.421 |
| 2009/02/25 |
2206.572 |
2009/03/25 |
2291.551 |
| 2009/02/26 |
2121.252 |
2009/03/26 |
2361.701 |
| 2009/02/27 |
2082.852 |
2009/03/27 |
2374.44 |
load data3_1.txt;
[m,n]=size( data3_1);
tsx = data3_1(1:m-1,1);
tsx=tsx';
ts = data3_1(2:m,1);
ts=ts';
[TSX,TSXps]=mapminmax(tsx,1,2);
[TS,TSps]=mapminmax(ts,1,2);
TSX=TSX';
figure;
plot(ts,'LineWidth',2);
title('到杭旅游总人数(1999.01.01-2009.12.31)','FontSize',12);
xlabel('统计年份(1990.12.19-2009.08.19)','FontSize',12);
ylabel('归一化后的总游客数/万人','FontSize',12);
grid on;
% 生成BP网络、利用minmax函数求输入样本范围
net_1=newff(minmax(TS),[10,1],{'tansig','purelin'},'traincgf')
% 设置训练参数
net_1.trainParam.show = 50; %显示训练迭代过程(NaN表示不显示,缺省25)
net_1.trainParam.lr = 0.025; %学习率(缺省0.01)
net_1.trainParam.mc = 0.9; %动量因子(缺省0.9)
net_1.trainParam.epochs = 10000; %最大训练次数
net_1.trainParam.goal = 0.001; %训练要求精度
inputWeights=net_1.IW{1,1} %输入层权值
inputbias=net_1.b{1} %输入层阈值
layerWeights=net_1.LW{2,1} %输出层权值
layerbias=net_1.b{2} %输出层阈值
TS',TSX
% 网络训练
[net_1,tr]=train(net_1,TS,TSX);