第一个爬虫实验总结
工作室的第一个实验:
我需要完成的任务是使用 python 完成简单的爬虫项目:
网站:https://bbs.pku.edu.cn/v2/thread.php?bid=690
- 爬取每一个帖子内的标题、心理咨询师的回复(没有回复的只爬取标题)
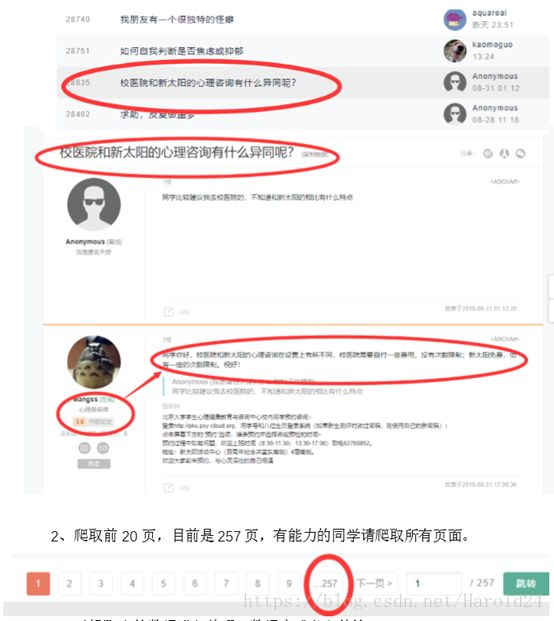
2、爬取前 20 页,目前是257页,有能力的同学请爬取所有页面。
3、对提取出的数据进行整理,数据库或者文件等。
完全0基础,除了大一学的那可怜的简单的C语言和数据结构外,真的是一无所知,好在坚持就是胜利,不懂就放弃和不懂就学,幸运的是我选择了后者。
既然是用python完成实验,第一步必须得看得懂python…而最简单的方法就是向前辈们问一些实用的学习资料,有助于提高效率。这里推荐一个网站http://www.runoob.com/【菜鸟教程】。拿到这个网址后,我花了整整一个晚上,看完了有关python的所有内容,虽然有点烧脑,但至少让我在之后的学习中,能读懂python了。
看完后第一感觉,啊,看完了,怎么写…从一脸到百脸懵逼。
只能继续找资料。帖吧,论坛,到处搜吧。不得不说CSDN真的帮我省了很多事。语言关过后,我选择直接把关键点定到爬虫。问题在于大多帖子并不适合初学者阅读,淘了大半天,找到了一个记录作者第一次做爬虫的帖子:
https://blog.csdn.net/Yvonne_Lu7/article/details/81097787 感谢博主的分享,让我少走了许多弯路。
基本是我需要用的模板了.ok模板有了,那就开始搭环境。天真的我以为和C语言一样,一个VS就可以搞定,后来…整整一天都在不断的搭环境中,编译器其实很好解决,最麻烦的是在不断的报错中,引入需要的库。
Python最新源码,二进制文档,新闻资讯等可以在Python的官网查看到:
Python官网:https://www.python.org/

编译工具我选择了Pycharm。下载地址:
https://www.jetbrains.com/pycharm/download/#section=windows
右边免费那就右边。
先把原帖作者的源码拷贝下来,无数个错误,根据编译器的提示信息,开始一个个改正:
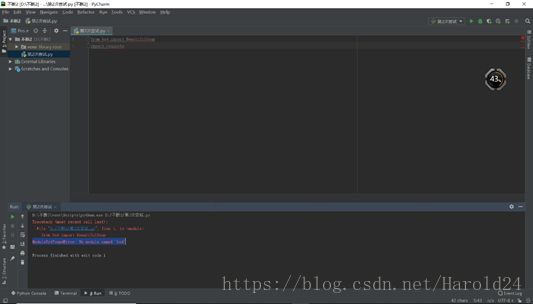
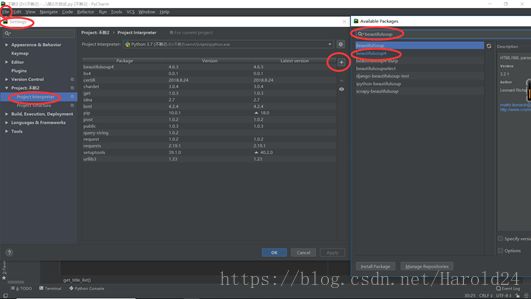
按照编译器的报错一个个解决,这里就不再赘述。
完成这些内容后,整体环境已经搭完,接下来的问题是程序中的参数我不知道是从哪来的,在不断的百度与谷歌中,发现自己还缺少对网页的基本认识,于是又花了一天的时间补充了网页知识。依旧推荐【菜鸟教程】和【CSDN】。
检查网页,教程和网页结合,更便于理解教程的内容:
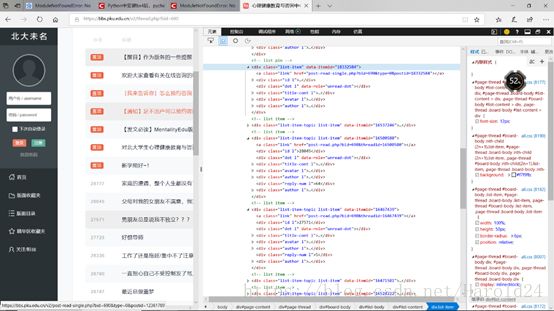
基本的知识补充完毕后,可以开始正式的完成实验:
首先对网页解析,爬取基本的网页信息。最开始我使用的Microsoft Edge浏览器,但这个浏览器没有CSS selector的选择。后来换成火狐后,只有CSS选择器,并不符合所需要的路径,实在没办法咨询了学长,换成了Google Chrome。--论浏览器的重要性
实现的过程:
首先引入库:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import requests
用request发起请求,并用BeautifulSoup对网页解析,将请求的信息解析成txt格式:
url = "https//bbs.pku.edu.cn/v2/"+str(T)
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text, "html.parser")检查网页元素,每个帖子的标签为
,将所以内容爬下,选择出文字部分,并打印:
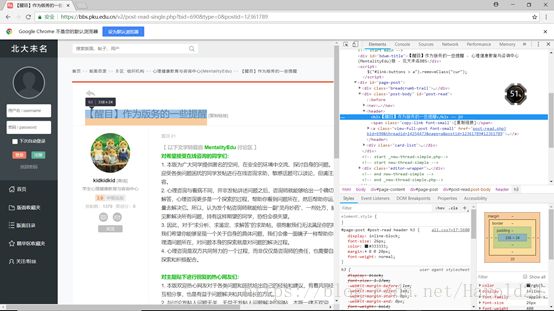
title_list = soup.select("h3")
title = title_list[0].text对筛选出心理咨询师的回复,将帖子的名称和心理咨询师回复写入指定的txt文本中,然后将函数封装。由此得到取出一个帖子内容的函数。
Tip:在这个页面中使用“Ctrl+F”可以弹出搜索页面,如果是标签+class=“xxx“的格式,用”.“替换class,复制xxx到搜索框,也可以快速找到我们筛选的内容:
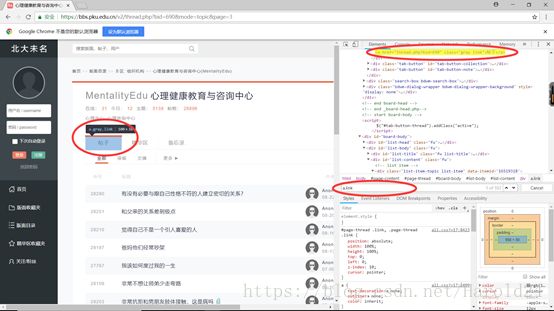
例如上述选取帖子标题:
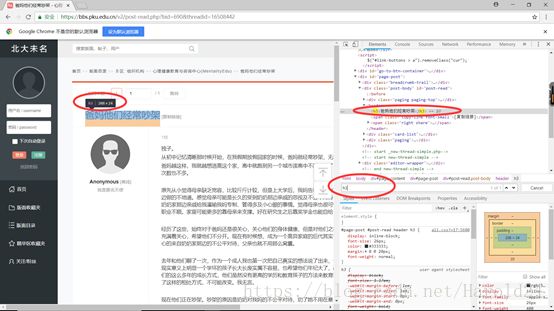
下一步我需要选取到每个帖子的链接,以便于我可以打开每一个帖子:
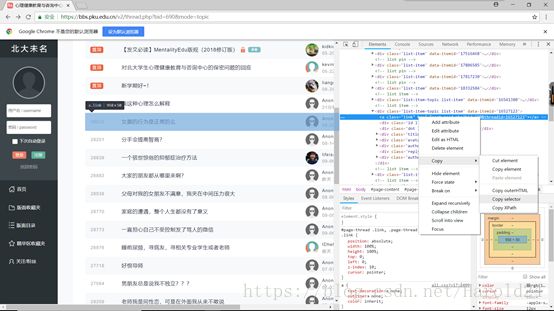
通过对比,我们可以很容易发现:
#list-content > div:nth-child(9) > a
#list-content > div:nth-child(12) > a
每一页的标题中只是括号内的数字又差别,且每一页的帖子为20个,由此我们只需要做一个循环,便可以选到每个帖子的链接,再调用之前我们封装好的函数即可。
需要注意的是,这里我使用的是select,区别于find,在select中,不能用nth-child,需要修改为nth-of-type。
取网页链接的时候还碰都过一个难点就是,要取到“href”的内容:
问题:
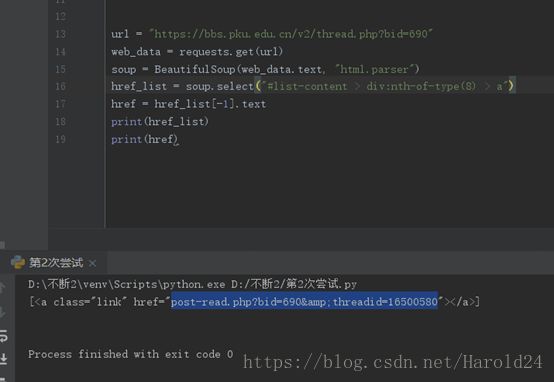
解决:
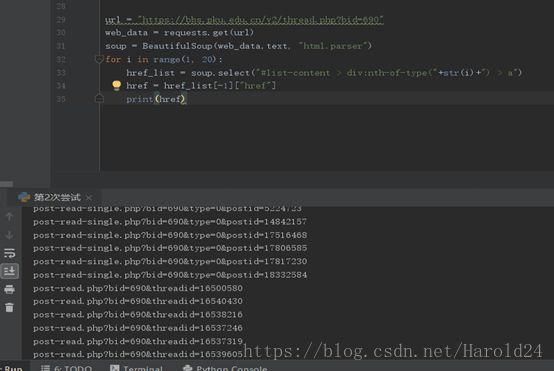
最终函数源码如下:
def get_title_list(url):
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text, "html.parser")
for i in range(1, 20):
href_list = soup.select("#list-content > div:nth-of-type(" + str(i) + ") > a")
href = href_list[-1]["href"]
get_reply(href)
f.writelines("============\n")
最后为了爬取多页的内容,需要一个选取页数的函数,我们点击每一页,观察地址:

![]()
![]()
![]()
规律还挺显然的,接下来完成取页数的函数:
def getPage():
pagelist = []
basic_page = 'https://bbs.pku.edu.cn/v2/thread.php?bid=690&mode=topic&page='
for i in range(1, 255):
new_page = basic_page + str(i)
pagelist.append(new_page)
return pagelist封装好,最后调用我们做好的三个函数就可以了。
所有源码如下:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import requests
def getPage():
pagelist = []
basic_page = 'https://bbs.pku.edu.cn/v2/thread.php?bid=690&mode=topic&page='
for i in range(1, 257):
new_page = basic_page + str(i)
pagelist.append(new_page)
return pagelist
def get_reply(T):
url = "https://bbs.pku.edu.cn/v2/"+str(T)
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text, "html.parser")
title_list = soup.select("h3")
title = title_list[0].text
f.writelines(title+'\n')
name_list = soup.findAll('p', {'class': 'nickname text-line-limit'})
for name in name_list:
if name.text == '心理咨询师':
postcard = name.parent.parent
bsn = BeautifulSoup(str(postcard), 'html.parser')
answer = bsn.find('div', {'class': 'body file-read image-click-view'}).p
reply = '心理咨询师回复:' + str(answer.get_text()) + '\n'
f.writelines(reply)
def get_title_list(url):
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text, "html.parser")
for i in range(1, 20):
href_list = soup.select("#list-content > div:nth-of-type(" + str(i) + ") > a")
href = href_list[-1]["href"]
get_reply(href)
f.writelines("============\n")
filename = '测试3.txt'
f = open(filename, 'w', encoding='utf-8')
for page in getPage():
get_title_list(page)
爬取结果如下:


需要改进的地方:
通过观察,可以发现每一页的帖子为20个,所以在循环的设定中每一页只爬了20个帖子,但是第一页置顶了7个帖子,所以第一页是27个,置顶的帖子元素中存在一个single,它同时影响到了后面的数字,单纯的修改“i”值会在后面的请求中会出现无响应的情况。