【机器学习+python(9)】回归决策树
欢迎关注哈希大数据微信公众号《哈希大数据》
上次分享我们简单介绍了分类决策树的基本原理和算法实现。决策树算法是在全部数据集中通过迭代的方式选择最佳属性进行不断切分,直至切分后的小数据集中目标属于同一类,或者到满足停止切分条件时完成数据划分。
在分类树切分数据时,主要是对单个离散目标值进行概率统计后用gini指数值来衡量某一属性的数据集纯度,进而选择使gini值最小的属性特征作为划分结点。但是这种方式,是无法直接处理连续型目标值的数据特征。
因此在本节中,我们将以波士顿房价数据为例生成二叉回归树(房价本身是一个连续变化的目标值),其中使用CART算法中的最小平方误差(最小二乘法原理)准则来选择特征,处理连续型目标数据。
回归树的基本原理
回归树与分类树不同之处在于回归树符合“物以类聚”的特点,比如人的风格是一个连续分布,但是又能“群分”成高冷、文艺、普通和逗B四个类别,利用回归树可以返回一个具体值来判断一个人是文艺还是逗B,虽然不能度量他有多高冷或者多逗B,但是更进一步设置返回关于类别的一个概率函数,就能度量他的高冷程度了。
总之,回归树要求目标值是连续分布的,但又是可以划分类别的,也就是类别之间有比较鲜明的区别。也就是每个类别内部具有相似的连续分布特征,而类别之间分布特征是不同的。可以保证不同特征值的组合会使目标都属于某一个“类别”,而类别之间会存在相对鲜明的“鸿沟”。
从之前的线性回归、逻辑回归学习中,可知回归就是为了处理预测值是连续分布的情景,而回归树的叶子结点返回值理论上应该是一个具体的预测值,但在实际处理中,会以一系列数的均值作为回归树的预测值。因此从预测值非完全连续这个意义上严格来说,回归树不能称之为“回归算法”,算是特殊处理的“分类”算法。也正如此可以利用回归树将复杂的训练数据划分成一个个相对简单的类别,然后在各个子类中结合其他的机器学习模型再进行数据训练。
直接介绍原理可能稍微比较抽象,是不都都被绕晕了,因此接下来我们通过实例来详细看一下回归树的生成过程。
回归树的生成算法
假设数据集的特征为X,连续型决策目标为Y。每一组特征Xi会对应一个目标值Yi。
通过python模拟生成[-0.5-0.5]之间100等分的数据集。
# 生成数据集
nPoints = 100
# 特征x的取值为-0.5-0.5之间的100等分
x = [-0.5+1/nPoints*i for i in range(nPoints + 1)]
目标y的取值:在特征值的基础上加一定的随机值(噪音数据)
# 保证每次随机生成数据与前一次相同
numpy.random.seed(1)
# 随机生成宽度为0.1的标准正态分布的数值
y = [s + numpy.random.normal(scale=0.1) for s in x]
回归树的生成是从特征空间X中,递归遍历所有特征空间,并按照要求将所有特征值依次分为两类,再对应输出子特征空间所对应的目标值。具体过程为:
通过将特征X划分为n个单元:Rn(n取1,2,3…n.),在每个单元中有一个固定的输出值Cn,因此回归树的具体模型可表示为:

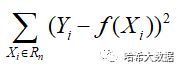
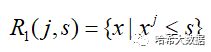 和
和
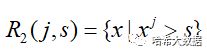
sumSSE = []
for i in range(1, len(x)):
#以x[i]为界,分成左侧数据和右侧数据
r1 = list(x[0:i])
r2 = list(x[i:len(x)]) 其次通过最小化: 来计算获取最优的切分变量j 和最优切分点s 。
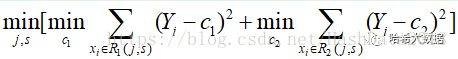
r1Avg = sum(r1) / len(r1)
r2Avg = sum(r2) / len(r2)
#计算每侧的平方和
r1Sse = sum([(s – r1Avg) * (s – r1Avg) for s in r1])
r2Sse = sum([(s – r2Avg) * (s – r2Avg) for s in r2])
#统计总的平方和,即误差和
sumSSE.append(r1Sse + r2Sse)
# 找到使误差和最小的s
minSse = min(sumSSE)
# 产生最小误差和时对应的位置j
idxMin = sumSSE.index(minSse)然后,计算预测结果为特征空间中的目标值均值,即
# 输出最优划分特征空间中的对应数据的预测值
c1pred = sum(r1) / len(r1)
c2pred = sum(r2) / len(r1)回归树的实例
了解了回归树的实现流程,我们通过直接调用sklearn库中的DecisionTreeRegressor()函数实现回归树,获得预测结果。
1、首先对上述模拟数据(-0.5-0.5)进行训练和预测,设置回归树深度为1或2:
#训练数据集,决策树深度为1或2
simpleTree = DecisionTreeRegressor(criterion='mse',max_depth=2)
simpleTree.fit(numpy.array(x).reshape(-1,1), numpy.array(y).reshape(-1,1))
#直接预测数据集x
y_pred = simpleTree.predict(numpy.array(x).reshape(-1,1))
#绘制预测结果
plot.figure()
plot.plot(xPlot, y, label='True y')
plot.plot(xPlot, y_pred, label='Tree Prediction ', linestyle='--')
plot.legend(bbox_to_anchor=(1,0.2))
plot.axis('tight')
plot.xlabel('x')
plot.ylabel('y')
plot.show()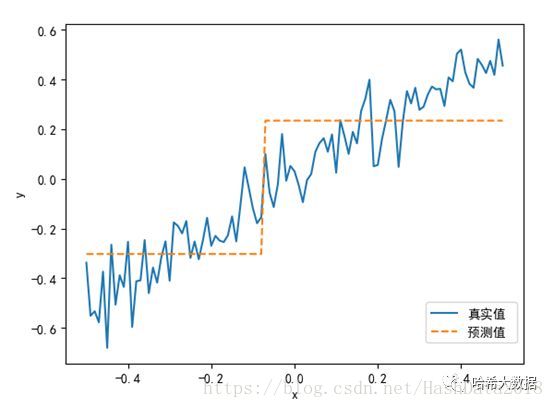
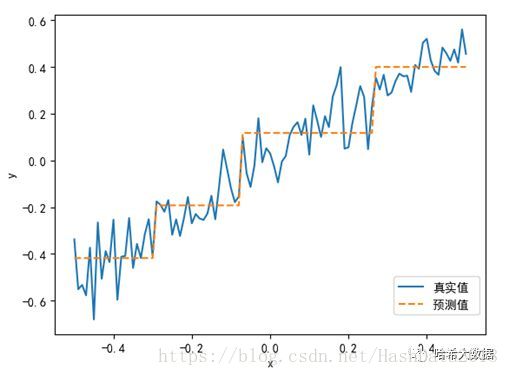
2、回归树实例--进行波士顿房价的预测。
通过限制回归树不同深度来验证比较模型的准确性。
# 导入相关模块
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.datasets import load_boston
import matplotlib.pyplot as plt
import random
'''注:回归树的叶节点的数据类型是连续型,节点的值是‘一系列’数的均值'''
# 导入数据
boston_house_price = load_boston()
boston_house_price_X = boston_house_price.data
boston_house_price_y = boston_house_price.target
# 随机选取25%的数据构建测试样本,剩余作为训练样本
X_train,X_test,y_train,y_test=train_test_split(boston_house_price_X, boston_house_price_y, random_state=0, test_size=0.25)
# 初始化回归树模型
depth = [2,6,10,15]
n = 0
for i in depth:
n = n + 1
decision_i = DecisionTreeRegressor(criterion='mse',max_depth=i)
# 训练回归树模型
decision_i.fit(X_train,y_train)
# 使用测试数据检验回归树结果
y_pre_decision_i = decision_i.predict(X_test)
decision_score = decision_i.score(X_test, y_test)
print('回归树深度为 {} 预测的准确性'.format(i),decision_score)
# 在不同子图中画出决策结果
m = 220
plt.subplot(m+n)
plt.scatter(range(len(y_test)),y_pre_decision_i,label='深度为{}时的预测房价'.format(i),c=random.choice(['cyan','red','blue','green','purple','magenta']))
plt.plot(y_test,label='真实的房价',c=random.choice(['red','yellow','blue']))
plt.legend()
plt.show()


直接使用回归树预测波士顿房价是很方便哒,而且对比【python+机器学习(2)】中线性回归对房价的预测,可以看出回归树预测的准确率更高。