【算法周】PCA教你如何化繁为简(下)
欢迎关注哈希大数据微信公众号《哈希大数据》
3. PCA算法流程
从上面两节我们可以看出,求样本x(i)的n'维的主成分其实就是求样本集的协方差矩阵XXT的前n'个特征值对应特征向量矩阵W,然后对于每个样本x(i),做如下变换z(i)=WTx(i),即达到降维的PCA目的。
输入:n维样本集D=(x(1),x(2),...,x(m)),要降维到的维数n'.
输出:降维后的样本集D′
1) 对所有的样本进行中心化:
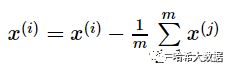
2) 对矩阵XXT进行特征值分解
3)取出最大的n'个特征值对应的特征向量(w1,w2,...,wn′), 将所有的特征向量标准化后,组成特征向量矩阵W。
4)对样本集中的每一个样本x(i),转化为新的样本z(i)=WTx(i)
5) 得到输出样本集D′=(z(1),z(2),...,z(m))
有时候,我们不指定降维后的n'的值,而是换种方式,指定一个降维到的主成分比重阈值t。这个阈值t在(0,1]之间。假如我们的n个特征值为λ1≥λ2≥...≥λn,则n'可以通过下式得到:
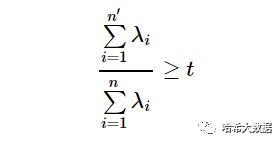
4. PCA实例
下面举一个简单的例子,说明PCA的过程。
假设我们的数据集有10个二维数据(2.5,2.4), (0.5,0.7), (2.2,2.9), (1.9,2.2), (3.1,3.0), (2.3, 2.7), (2, 1.6), (1, 1.1), (1.5, 1.6), (1.1, 0.9),需要用PCA降到1维特征。
首先我们对样本中心化,这里样本的均值为(1.81, 1.91),所有的样本减去这个均值后,即中心化后的数据集为(0.69, 0.49), (-1.31, -1.21), (0.39, 0.99), (0.09, 0.29), (1.29, 1.09), (0.49, 0.79), (0.19, -0.31), (-0.81, -0.81), (-0.31, -0.31), (-0.71, -1.01)。
现在我们开始求样本的协方差矩阵,由于我们是二维的,则协方差矩阵为:
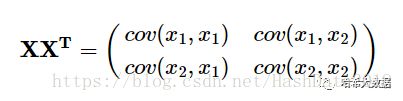
对于我们的数据,求出协方差矩阵为:

求出特征值为(0.490833989, 1.28402771),
对应的特征向量分别为:
(0.735178656,0.677873399)T
(−0.677873399,−0.735178656)T,由于最大的k=1个特征值为1.28402771,对于的k=1个特征向量为
(−0.677873399,−0.735178656)T. 则我们的
W=(−0.677873399,−0.735178656)T
我们对所有的数据集进行投影z(i)=WTx(i),得到PCA降维后的10个一维数据集为:
(-0.827970186, 1.77758033, -0.992197494, -0.274210416, -1.67580142, -0.912949103, 0.0991094375, 1.14457216,
0.438046137, 1.22382056)
5. 核主成分分析KPCA介绍
在上面的PCA算法中,我们假设存在一个线性的超平面,可以让我们对数据进行投影。但是有些时候,数据不是线性的,不能直接进行PCA降维。这里就需要用到和支持向量机一样的核函数的思想,先把数据集从n维映射到线性可分的高维N>n,然后再从N维降维到一个低维度n', 这里的维度之间满足n' 使用了核函数的主成分分析一般称之为核主成分分析(Kernelized PCA, 以下简称KPCA。假设高维空间的数据是由n维空间的数据通过映射ϕ产生。 则对于n维空间的特征分解: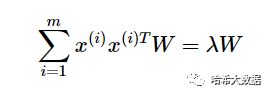
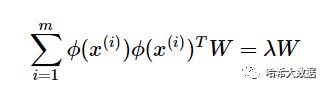
7. PCA算法总结
这里对PCA算法做一个总结。作为一个非监督学习的降维方法,它只需要特征值分解,就可以对数据进行压缩,去噪。因此在实际场景应用很广泛。为了克服PCA的一些缺点,出现了很多PCA的变种,比如第六节的为解决非线性降维的KPCA,还有解决内存限制的增量PCA方法Incremental PCA,以及解决稀疏数据降维的PCA方法Sparse PCA等。
PCA算法的主要优点有:
1)仅仅需要以方差衡量信息量,不受数据集以外的因素影响。
2)各主成分之间正交,可消除原始数据成分间的相互影响的因素。
3)计算方法简单,主要运算是特征值分解,易于实现。
PCA算法的主要缺点有:
1)主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
2)方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。