算法学习-KMP算法
KMP算法是解决字符串查找问题的,给定文本串text和模式串pattern,从文本串text中找出模式串pattern第一次出现的位置。
最基本的字符串匹配算法是暴力求解,时间复杂度为O(m*n)
KMP算法是一种线性时间复杂度的字符串匹配算法,他是对暴力算法的改进。
记:文本串长度为N,模式串长度为M,那么暴力算法的时间复杂度为O(M*N),空间复杂度为O(1),KMP算法的时间复杂度为O(M+N),空间复杂度为O(M)
先给出暴力求解算法,比较简单,如下
// 查找s中首次出现p的位置
int BruteForceSearch(const char* s, const char* p)
{
int i = 0;// 当前匹配到的原始串收尾
int j = 0;// 模式串的匹配位置
int size = (int)strlen(p);
int nLast = (int)strlen(s) - size;
while((i <= nLast) && (j < size))
{
if (s[i + j] == p[j])// 若匹配,则模式串匹配位置后移
{
j++;
}
else // 不匹配,则对比下一个位置,模式串回溯到位首
{
i++;
j = 0;
}
}
if (j >= size)
{
return i;
}
return -1;
}KMP分析
先看一个图,改图表示了当匹配到黄色和绿色失配的情况下KMP的处理过程我们可以不用将j不用移到串首,而是移动到串的某个位置

我们为什么可以这样做呢,可以看下图,下图是上面移动的过程的放大图
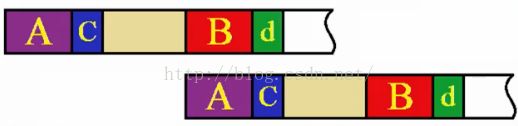
如果我们要这样做,必定有个前提,A和B肯定是相同的。那么我们只需要找到d以前的相等的最长前缀串和最长后缀串,下面看一下怎么得到这个前缀串
有如下例子

如:j=5时,考察字符串“abaab”的最大相等k前缀和k后缀如下图

显然最大且相等的是ab,所以如果匹配到c的位置发现不匹配,这个时候i就不需要动了,j就可以回溯到next[j]也就是2,然后模式串从2,文本串从i继续匹配,最好的情况恰好是next[j]=0的时候,因为他们没有相同的前缀和后缀,所以我们可以知道在i和j中间怎么移动都不会有匹配了,所以直接将向后移动j位,j回溯到0就可以了,这样滑动是最快的,相反next[j]越大滑动越慢,注意理解i的移动和暴力算法下的区别,解释完毕。
那么现在比较重要的应该是怎么去获得这个next数组了,P为模式串,如下图
对于模式串的位置j,有next[j]=k,即:P0P1...Pk-1=Pj-kPj-k+1...Pj-2Pj-1则,对于模式串的位置j+1,考察Pj:
若P[k]==P[j]
则next[j+1]=next[j]+1
若P[k]!=P[j],那么我们知道A和B是相等的,我们需要在B中找所以
记h=next[k](next[k]肯定是已经求出来了),如果P[h]==P[j],则next[j+1]=h+1,为什么呢,因为A=B,1=3,所以1=2,所以可以的到上面结论,否则重复此过程。

分析完毕,给出求next的代码
void GetNext(char* p, int next[]) { int nLen = (int)strlen(p); next[0] = -1; int k = -1; int j = 0; while (j < nLen - 1) { // 此刻,k即next[j-1],且p[k]表示前缀,p[j]表示后缀 // 住:k==-1表示未找到k前缀与k后缀相等,首次分析可先忽略 if (k == -1 || p[j] == p[k]) { ++j; ++k; next[j] = k; } else // p[j]与p[k]失配,则继续递归计算前缀p[next[k]] { k = next[k]; } } }
接下来给出KMP的代码char* g_s = "dsaqeabaabcabaffd"; char* g_pattern = "abaabcaba"; int KMP() { int ans = -1; int i = 0; int j = 0; int pattern_len = strlen(g_pattern); int g_next[100] = {0}; GetNext(g_pattern, g_next); while (i < strlen(g_s)) { if (j == -1 || g_s[i] == g_pattern[j]) { ++i; ++j; } else { j = g_next[j]; } if (j == pattern_len) { ans = i - pattern_len; break; } } return ans; }分析BF与KMP的区别
- 假设当前文本串text匹配到i位置,模式串pattern匹配到j位置。
- BF算法中,如果当前字符串匹配成功,即text[i+j]==pattern[j],令j++,继续匹配下一个字符。若适配,即text[i+j]!=pattern[j],令i++,j=0,即匹配失败是,模式串pattern相当于文本串向右移动了一位。
- KMP算法中,若当前字符串匹配成,即text[i+j]==pattern[j],令j++,继续匹配下一个字符。若失配,即text[i+j]!=pattern[j],令j=next[j](next[j]<=j-1),即模式串pattern相对于文本串text向右移动至少一位(实际移动位数为:j-next[j]>=1)
到这里感觉可以松口气了,但是告诉你,还没完呢,不要气馁,继续前进吧
进一步分析next
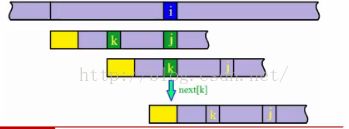
- 文本串匹配到i,模式串匹配到j,此刻,若text[i] != pattern[j],即失配的情况:
- 若next[j]=k,说明模式串应该从j滑动到k位置
- 若此时满足pattern[j]==pattern[k],因为next[i]!=pattern[j],所以,text[i]!=pattern[k]
- 即i和k没有匹配,应该继续滑动next[k]。
- 换句话说:在原始的next数组中,若next[j]=k并且pattern[j]==pattern[k],next[j]可以直接等于next[k]。
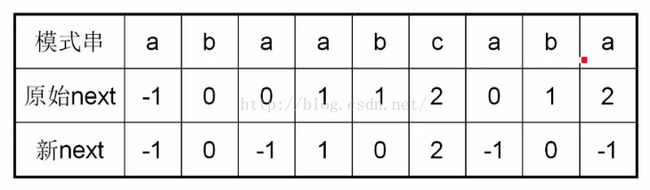
以最后一个a为例,它的原始next为2,但是P[2]是跟他相等的,所以这时候再去匹配P[2]肯定也不行,那么直接就把原来的next更新为2下面的next,应该很好理解的,因为值越小效率月快,所以变种后的比较优,那么下面给出变种后的next代码
void GetNext(char* p, int next[])
{
int nLen = (int)strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < nLen - 1)
{
// 此刻,k即next[j-1],且p[k]表示前缀,p[j]表示后缀
// 住:k==-1表示未找到k前缀与k后缀相等,首次分析可先忽略
if (k == -1 || p[j] == p[k])
{
++j;
++k;
if (p[j] == p[k])
{
next[j] = next[k];
}
else
{
next[j] = k;
}
}
else // p[j]与p[k]失配,则继续递归计算前缀p[next[k]]
{
k = next[k];
}
}
}理解KMP的时间复杂度
我们考察模式串的“串头”和主串的对应位置(也就是暴力算法中的i);
不匹配:穿透后移,保证尽快结束算法
匹配:穿透保持不动(仅仅是i++、j++,但穿透和主串对应位置没变,但一旦发现不匹配,会跳过一赔过的字符(next[j]))。
最坏的情况,当穿透鱼尾N-M的位置,算法结束
因此,匹配的时间复杂度为O(N),算上next的O(M),整体时间复杂度为O(M+N)。
下面给出一个KMP算法的应用PowerString周期串
给定一个长度为n的字符串S,如果存在一个字符转T,重复若干次T能够得到S,那么,S叫作周期串,T叫做S的一个周期
如:字符串abababab是周期串,abab、ab都是它的周期,其中,ab是它的最小周期。
设计一个算法,计算S的最小周期。如果S不存在周期,返回空串。

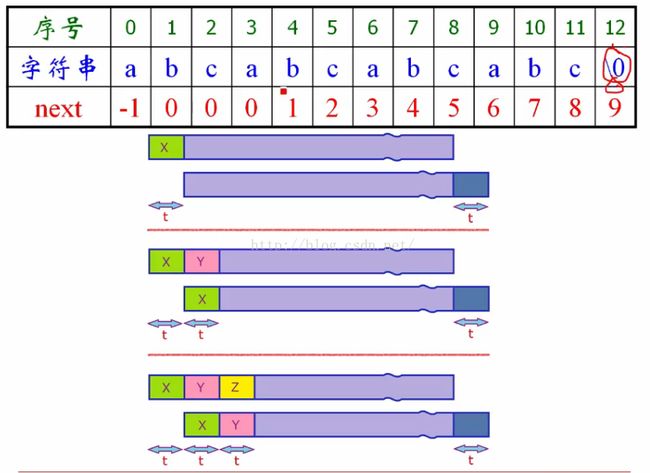
对于下面三个条带图我们从第一个开始分析,他是最长前缀和最长后缀,从图中的得到的信息是中间部分相等,为什么他们相等呢,其实这个问题我思考了好长时间,最后恍然大悟,他们是重合的,所以就相等了,呵呵,那我们依次向后同时取t长度,则得出上下对应相等,又因为前提是len-k可以被t整除,所以得出一共有t个串,所以t是他的周期了。
最后一个题目不是特别理解,就理解到这里吧,估计应付面试应该没问题了。