Django模型基础二: 常用查询及表关系的实现
常用查询
每一个django模型类,都有一个默认的管理器,objects

QuerySet表示数据库中对象的列表。它可以有0到多个过滤器。过滤器通过给定参数,缩小查询范围(filter)
QuerySet等同于select语句,过滤器是一个限制子句,比如where,比如 limit。
查询方法

- all() 获取所有
Student.objects.all() # 返回的是queryset
- 获取第一个条
Student.objects.first() # 返回的是对象
- 获取最后一条
Student.objects.last() # 返回的是对象
-
get(**kwargs)根据给定的条件获取一个对象,如果符合多个,或没有就会报错
-
fitler(**kwargs)过滤,根据参数提供的条件,获取一个过滤器后的QuerySet,多个条件等同于
select子句使用and连接,关键字参数的形参必须是模型中的字段名。
In [13]: Student.objects.filter(name='小华').filter(age='19')
Out[13]: <QuerySet [<Student: 小华>]>

- exclude(**kwargs), 用法和filter一样,作用相反,它是排除。
In [14]: Student.objects.exclude(age='18')
Out[14]: <QuerySet [<Student: 小华>]>

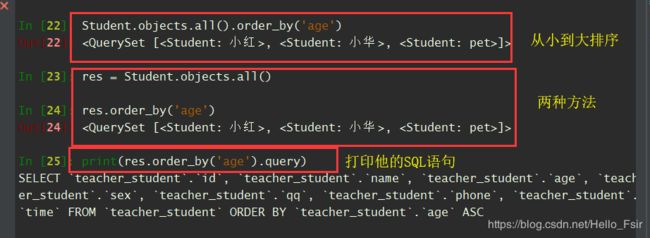
- order_by(*fields),根据给定的字段排序。
In [22]: Student.objects.all().order_by('age')
Out[22]: <QuerySet [<Student: 小红>, <Student: 小华>, <Student: pet>]>
In [23]: res = Student.objects.all()
In [24]: res.order_by('age')
Out[24]: <QuerySet [<Student: 小红>, <Student: 小华>, <Student: pet>]>
In [25]: print(res.order_by('age').query)
SELECT `teacher_student`.`id`, `teacher_student`.`name`, `teacher_student`.`age`,
`teacher_student`.`sex`, `teacher_student`.`qq`, `teacher_student`.`phone`,
`teacher_student`.`time` FROM `teacher_student` ORDER BY `teacher_student`.`age` ASC

多条件:有先后顺序

倒序
In [28]: print(res.order_by('-age','name').query) # 默认asc,-age 代表反向排序

- 切片 使用列表的切片语法操作query,除了不能用负索引,其他的都可以,它等价于LIMIT与OFFSET子句

1.数据库数据计算是从0开始的
2.offset X是跳过X个数据,limit Y是选取Y个数据
3.limit X,Y 中X表示跳过X个数据,读取Y个数据


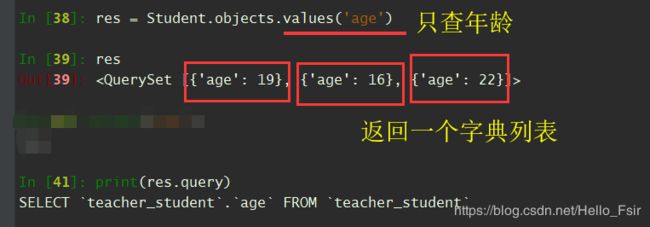
- values(*fields)返回queryset, 这个queryset返回的是一个字典列表。参数fields指定了select中我们想要限制查询的字段。返回的
字典列表中,只会包含我们指定的字段。如果不指定,包含所有字段。
In [38]: res = Student.objects.values('age')
In [39]: res
Out[39]: <QuerySet [{'age': 19}, {'age': 16}, {'age': 22}]>

- only(*fields)返回一个queryset,跟values一样,区别在于这个queryset是对象列表,only一定包含主键。
In [44]: s = Student.objects.only('name')
In [45]: s
Out[45]: <QuerySet [<Student: 小华>, <Student: 小红>, <Student: pet>]>
In [46]: print(s.query)
SELECT `teacher_student`.`id`, `teacher_student`.`name` FROM `teacher_student`

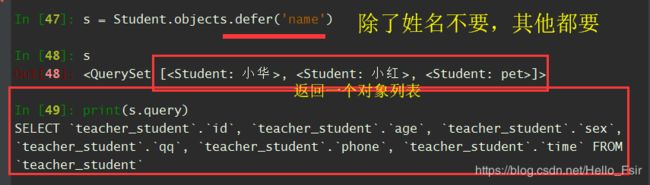
- defer(fields) 用法与only相反(除了fields这个字段不要之外,其他的都要)
In [47]: s = Student.objects.defer('name')
In [48]: s
Out[48]: <QuerySet [<Student: 小华>, <Student: 小红>, <Student: pet>]>
In [49]: print(s.query)
SELECT `teacher_student`.`id`, `teacher_student`.`age`, `teacher_student`.`sex`, `teacher_student`.`qq`, `teacher_student`.`phone`, `teacher_student`.`time` FROM `teacher_student`
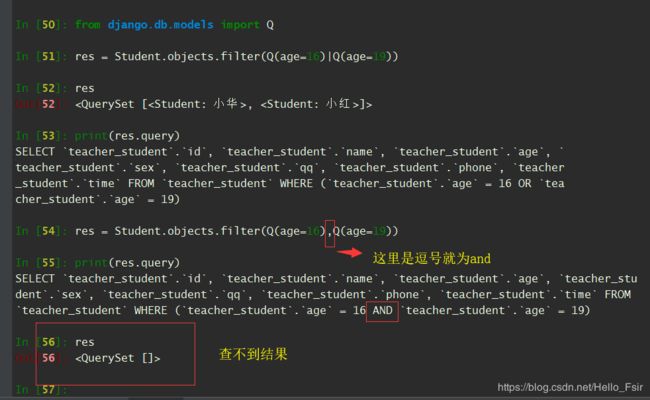
- 多条件OR连接,需要实现OR条件,我们要使用Q对象。
In [50]: from django.db.models import Q
In [51]: res = Student.objects.filter(Q(age=16)|Q(age=19))
In [52]: res
Out[52]: <QuerySet [<Student: 小华>, <Student: 小红>]>
In [53]: print(res.query)
SELECT `teacher_student`.`id`, `teacher_student`.`name`, `teacher_student`.`age`, `teacher_student`.`sex`, `teacher_student`.`qq`, `teacher_student`.`phone`, `teacher_student`.`time` FROM `teacher_student` WHERE (`teacher_student`.`age` = 16 OR `teacher_student`.`age` = 19)

查询条件
语法都是field__conditon 是 两个下划线

-
exact (精确匹配,相当于等于)
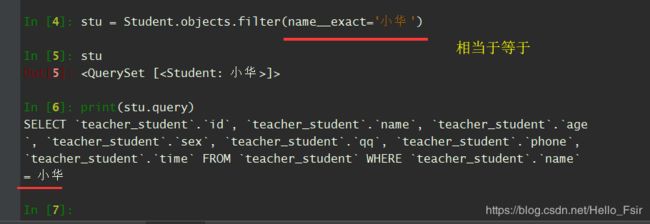
-
iexact ( 忽略大小写)
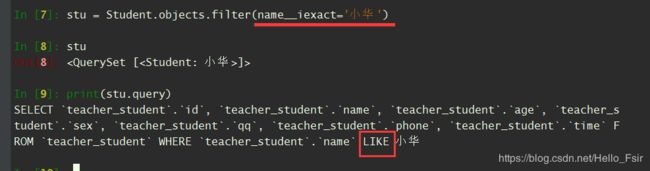
-
contains (包含)
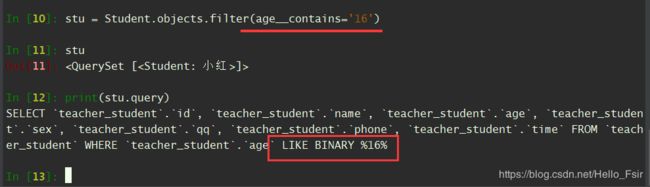
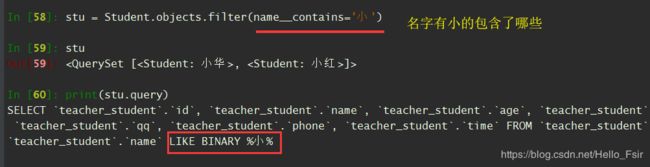
-
icontains (忽略大小写)

-
in (是否包含在范围内)
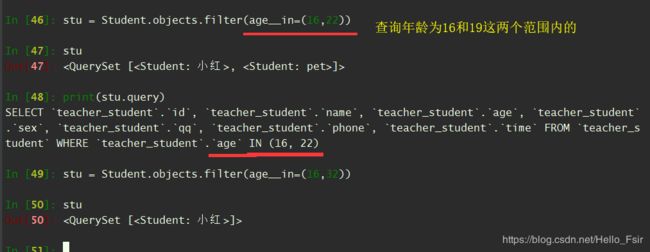
-
gt (大于)

-
gte (大于等于)
-
lt (小于)
-
lte (小于等于)
-
startswith (以什么什么开始)

-
istartswith (忽略大小写)
-
endswith (以什么什么结尾)

-
iendswith (忽略大小写)
-
range ( 范围区间)
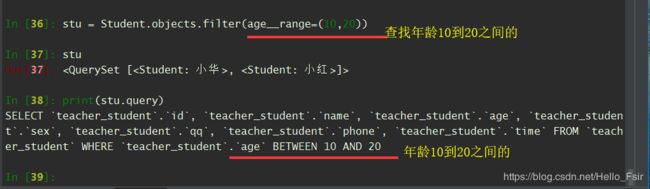
-
isnull (判断是否为空)
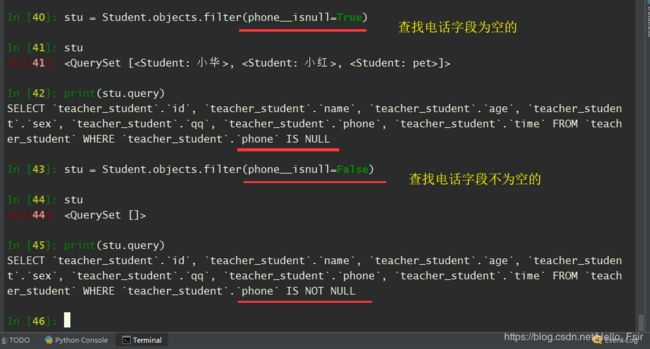
-
count() (统计数量 (返回queryset的长度))

聚合函数
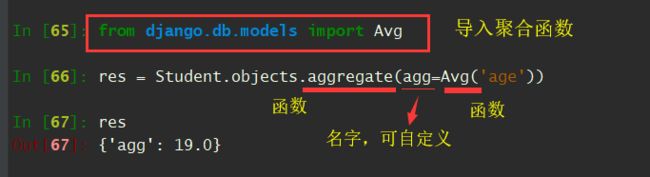
- Avg 平均值
# 计算同学们的年龄平均值
In [65]: from django.db.models import Avg
In [66]: res = Student.objects.aggregate(agg=Avg('age'))
In [67]: res
Out[67]: {'agg': 19.0}
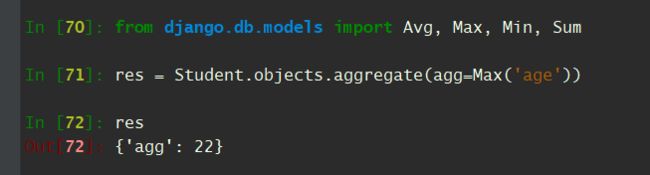
- Max 最大值
# 找到最大的年龄
In [70]: from django.db.models import Avg, Max, Min, Sum
In [71]: res = Student.objects.aggregate(agg=Max('age'))
In [72]: res
Out[72]: {'agg': 22}
- Min 最小值
# 找到最小的年龄
In [73]: res = Student.objects.aggregate(agg=Min('age'))
In [74]: res
Out[74]: {'agg': 16}

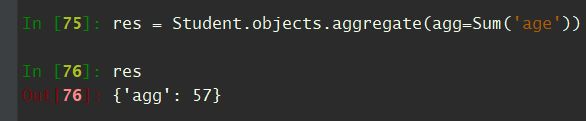
- Sum求和
# 计算同学们的年龄和
In [75]: res = Student.objects.aggregate(agg=Sum('age'))
In [76]: res
Out[76]: {'agg': 57}
分组聚合查询
聚合,分组需要结合 values , annotate 和聚合方法
看下面的案例
语法:
values(‘分组字段’).annotate(别名=聚合函数(‘字段’)).filter(聚合字段别名条件).values(‘取分组字段’, ‘取聚合字段别名’)
规则:
1.values(…).annotate(…)为分组组合,values控制分组字段,annotate控制聚合字段
2.values可按多个字段分组values(‘分组字段1’, …, ‘分组字段n’),??如果省略代表按操作表的主键分组
3.可以同时对多个字段进行聚合处理annotate(别名1=聚合函数1(‘字段1’), …, 别名n=聚合函数n(‘字段n’))
4.分组后的的filter代表having判断,只对聚合字段进行条件判断,可以省略(对非聚合字段或分组字段进行条件判断代表where判断)
5.取字段值values(…)省略默认取所有分组字段与聚合字段,也可以自主取个别分组字段及聚合字段(取字段的values中出现了非分组或非聚合字段,该字段自动成为分组字段)
# 查询男生女生分别有多少人
In [81]: from django.db.models import Avg, Max, Min, Sum, Count
In [82]: res = Student.objects.values('sex').annotate(Count('sex'))
In [83]: res
Out[83]: <QuerySet [{'sex': 0, 'sex__count': 1}, {'sex': 1, 'sex__count': 2}]>

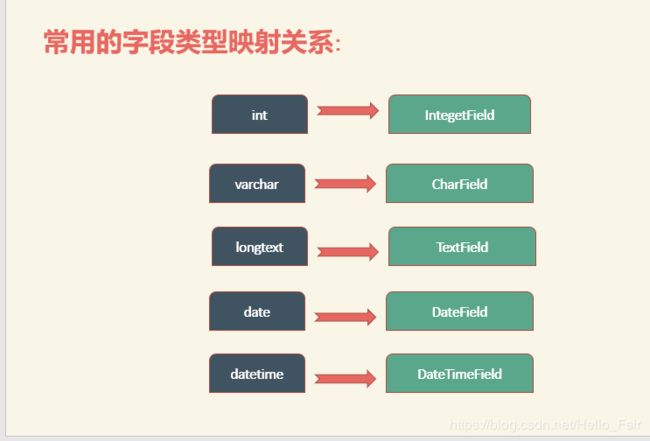
常用模型字段类型
官方文档https://docs.djangoproject.com/en/2.1/ref/models/fields/#field-types


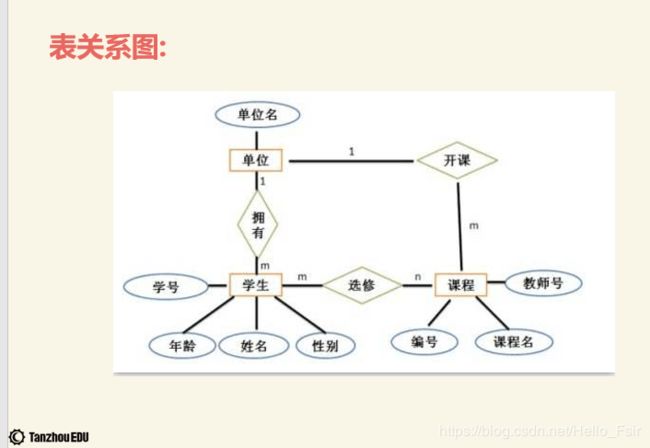
表关系实现
django 中,模型通过特殊的字段进行关系连接


-
一对一



-
一对多

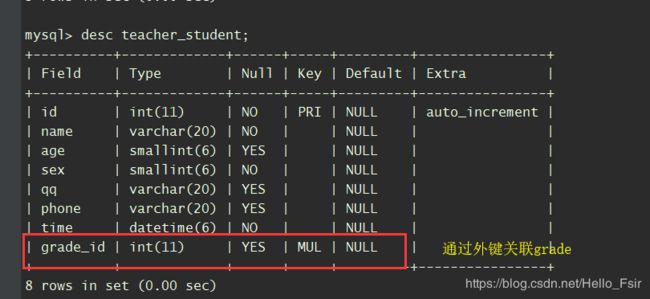
-
多对多



注:在多对多表关系中,如果我们有而外字段的情况下需要手动创建第三张表。


所有我们需要手动指定第三张表

