sklearn中的Logistic Regression
Logistic regression,这名字听上去像一种回归算法,但实际上它是一种分类算法。Logistic回归函数也被称为对数几率函数,常与最大熵模型作比较,二者都是对数线性模型。
在 sklearn 中,逻辑斯特回归函数来自于Logistic Regression这个类,适用于拟合0-1类,多分类(OvR),多项逻辑斯特回归(即y的值是多项的,可以是(0,1,2, )),可用L1和L2正则项来优化模型。
在优化问题上,使用L2正则项的话,逻辑斯特回归的损失函数为
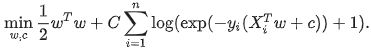
类似的,如果使用L1正则项的话,逻辑斯特回归的损失函数为
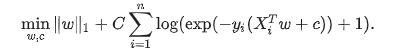
注意,在上式中,假设 y i y_{i} yi的取值为-1或1.
在Logistic Regression这个类中最优化方法有“liblinear”,“newton-cg”,“lbfgs”,"sag"和“saga”.
“liblinear”是一个C++库的名字,实际上它采用的是坐标下降法(coordinate descent, 简称CD)。在这个库里的CD算法,并不能真正的学习一个多分类模型(或多项逻辑斯特回归),它才用的是OvR拆分策略。该最优化算法支持L1正则项,可以得到稀疏的系数C。
在西瓜书上,如果不失一般性,考虑N个类别。OvR是每次将一个类的样例作为正例,所有其他类的样例作为反例来训练N个分类器。在测试时若仅有一个分类器预测为正类,则对应的类别标记作为最终分类结果。若有多个分类器预测为正类,则通常考虑各分类器的预测置信度,选择置信度最大的类别标记作为分类结果。
像"lbfgs",“sag"和"newton-cg”,库里给出的这三个优化算法则只支持L2正则项,并且他们在一些高维数据中可以收敛的更快。将属性“multi_class”设置为"multinomial"的话,他们可以学习到一个真正的多分类模型,这意味着他们在多分类问题上表现的更好,准确率更高。
“sag”指的是随机平均梯度下降,如果数据量很大的情况下的话(样本和特征的数量都很大),速度是最快的。
“saga”是“sag”的一种变形,它也支持不平滑正则项(non-smooth penalty),L1正则项。所以,如果想获得稀疏的多分类逻辑斯特回归,可以选择“saga”。
“lbfgs”近似于“Broyden–Fletcher–Goldfarb–Shanno algorithm”,是拟牛顿法的一种,适用于小数据集的情况,如果是大数据集的话,就会很灾难。
总结一下,就是
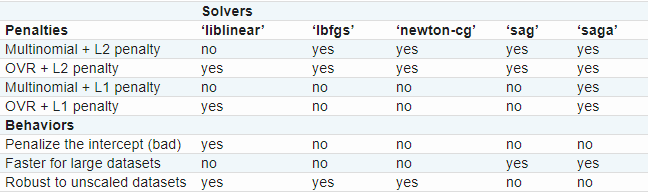
因为"lbfgs"算法的鲁棒性,所以它是默认的选择。如果是大数据的话,请选择“saga”,你也可以考虑用SGDClassifier配套上“log”损失函数,这一个方案更快,但是需要微调一下。
上述内容来自:https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
接下来将讲述对类中的各个参数的作用
class sklearn.linear_model.LogisticRegression(penalty=’l2’, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver=’warn’, max_iter=100, multi_class=’warn’, verbose=0, warm_start=False, n_jobs=None)
penalty:字符型,正则项,默认为L2正则项,可更改为’l1’
dual:bool型,默认是False。对偶或原始方法。Dual只适用于liblinear l2正则项情况下。如果是n_sample>n_features情况下,dual=False更为合适。
tol:float型,默认是1e-4。迭代终止判断的误差范围。
C:float型,默认是1.0。正则项系数的倒数,一定要是一个正数。与SVM一样,越小的数值越大的惩罚。
fit_intercept:bool型,默认是True.明确是否需要加一个偏差(或截距)进决策函数。
intercept_scaling:float型,默认为1。只有在优化器为"liblinear"并且self.fit_intercept设为True时才有用。在这种情况下,x变成了[x,self.intercept_scaling]。例如,一个有连续值的合成特征等于intercept_scaling加在了实例向量的后面。截距变成了intercept_scaling*合成特征的权重。注意,合成特征的向量同样受l1/l2正则项所限制。为了减小正则化对截距的影响,intercept_scaling要增加。
class_weight:dict型或’balanced’,默认为’balanced’。类的权重,以{class_label:weight}给出。如果没有给出的话,所有类的默认权重是1。如果是“balanced”模式的话,自动调节权重为n_samples/(n_classes * np.bincount(y))
random_state:当solver=='sag’或‘liblinear’时使用。int型,RandomState实例或None,可选,默认为None. 指定伪随机数生成器的种子,用来打乱数据。如果是int型的话,random_state就是随机数生成器使用的种子;如果给的是RandomState的实例的话,那么random_state就是随机数生成器;如果None的话,随机数生成器就是np.random。
solver:字符型,{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’},默认为“lbfgs”。用于优化问题的算法。
- 对于小数据集,'liblinear’是一个很好的选择,对于大数据集,'sag’和‘saga’更快。
- 对于多分类问题,只有’newton-cg’,‘sag’,'saga’和‘lbfgs’处理多项损失(multinomial loss),‘liblinear’对于多分类问题采取的是OvR拆分法
- ‘newton-cg’,'lbfgs’和‘sag’只能才用L2正则项,而‘liblinear’和‘saga’则可才用L1正则项
注意:‘sag’和‘saga’的快速收敛需要特征归一化。可以通过sklearn.preprocessing来实现特征归一化。
max_iter:int型,默认为100。只有solvers为{newton-cg,sag,lbfgs}有用。最大的迭代次数。
multi_class:字符型,{‘ovr’,‘multinomial’,‘auto’},默认为‘auto’。如果选择’ovr’,则代表这是一个0-1分类问题。如果选择’multinomial’的话,损失最小化就是整个概率分布的多项损失,包括数据是二分类的情况,如果solver=‘liblinear’,不存在这个选项。‘auto’的话,如果是二分类自动选择’ovr‘,如果solver=‘liblinear’或者其他情况,自动选择’multinomial’.
verbose:int型,默认为0。日志冗长度。对于solvers='liblinear’或‘lbfgs’,将verbose设置为任意整数用于显示信息。0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
warm_start:bool型,默认为False.当设置为True时,重新利用之前的结果来初始化,否则的话,清除之前的结果。如果是solver='liblinear’的话,该参数无效。
n_jobs:int型或None,可选(默认为None)。当multi_class='ovr’时CPU并行使用的数量。如果solver='liblinear’的话,该参数被无视。-1表示利用所有的处理器。
属性
classes_:array,shape(n_classes,),类的标签的列表
coef_: array, shape (1, n_features) or (n_classes, n_features),在决策函数中各特征的系数。如果是二分类问题的话,shape(1,n_features)。特别是,当multi_class='multinomial’时,coef_ 代表结果为1(True)的情况,-coef代表结果为0(False)的情况。
intercept:array,shape(1,)or(n_classes,)。在决策方程中的截距。如果fit_intercept为0的话,截距就为0。
n_iter:array,shape(n_classes,) or (1,)。所有类别的实际迭代次数。如果是二分类或是多项分类的话,返回一个元素。如果是solver=liblinear,只返回所有累呗的最大迭代次数。
方法
decision_function(X): 返回样本距离超平面的距离。
desify():将参数转换为np.ndarray形式输出
fit(X,y,sample_weight=None):训练
get_params(deep=True):获得参数
predict(X):预测
predict_log_proba(X):返回样本对于每一类的对数概率
predict_proba(X):返回样本对于每一类的概率
score(X, y[, sample_weight]):返回给出的测试数据和标签的平均准确率
set_params(**params):改变参数
sparsify():将参数转换为稀疏的格式