《ElasticStack从入门到实践》学习笔记10
十、Logstash入门与运行机制
1.介绍:
1)Logstash,ElasticStack中的数据收集处理引擎,可以视作一个ETL工具,是一个开源的数据收集引擎,它具有备实时数据传输能力,可统一过滤来自不同源的数据,并按照开发者的制定的规范输出到目的地。输入插件从数据源获取数据,过滤器插件根据用户指定的数据格式修改数据,输出插件则将数据写入到目的地。其工作流程主要分三个阶段:
①input;
②filter;
③output。
2)架构简介
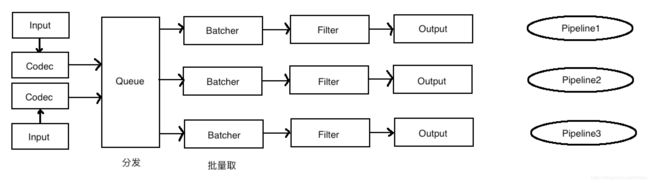
Pipeline
①input——filter——output的三阶段处理流程
②队列管理
③插件生命周期管理
Logstash Event(实际是一个Java Object)
①内部流转的数据表现形式
②原始数据在input被转换成event,在output中event被转换成目标格式数据
③在配置文件中可对event中属性进行增删改查

6.x版本整体架构
2.一个配置文件实例
codec.conf:
#codec.conf
input{
stdin{
codec => line
}
}
output{
stdout{
codec => json
}
}3.Queue
1)分类
A、In Memory 在内存中
无法处理进程Crash、机器宕机等情况,会导致数据丢失。
B、Persistent Queue In Disk 持久化队列,基于磁盘,记录操作
可处理进程Crash、机器宕机等情况,保证数据不丢失,确保数据至少被消费一次。(充当缓冲区,类似Kafka)
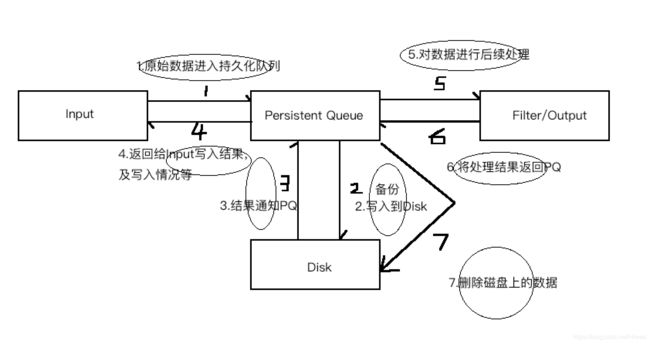
二者在性能上,相差约5%左右,一般情况建议打开Persistent Queue。
A、queue.type:persitsted。默认memory
B、queue.max_bytes=4gb。配置队列存储的最大数据量
2)线程
Input Thread 、Pipeline Worker Thread
一般对Logstash调优,调整的就是线程数。(Pipeline Worker Thread)
pipeline.worker / -w指定pipeline线程数,默认是CPU核数
pipeline.batch.size / -b Batch一次处理文档数,默认125。经验上,建议在每次处理的数据在10-20m之间。
pipeline.batch.delay /-u Batch等待的时长,默认50ms,(一般不用改)
4.Logstash配置
1)Logstash设置相关的配置文件。
①logstash.yml:
logstash相关配置,如:node.name、path.data、pipeline.workers、queue.type等,且都可被命令行先关参数覆盖。、
②jvm.options:
修改JVM相关系数,如:heap size等。
2)pipeline配置文件,以.conf结尾,定义数据处理流程的文件。
A、logstash.yml:
使用yml语法,支持层级结构和扁平结构:
#层级结构
pipeline:
batch:
size:125
delay:50
#扁平结构
pipeline.batch.size:125
pipeline.batch.delay:501.node.name.
2.path.data
3.path.config.
4.path.log.
5.pipeline.workers.
6.pipeline.batch.size/delay.
7.queue.type.
8.queue.max_bytes.
B、logstash命令行配置选项:
1.--node.name.
2.--path.config/-f. pipeline路径(文件/文件夹)
3.--path.settings. logstash配置文件夹路径,要包含logstash.yml(单节点上启动多个logstash实例的主要配置)
4.--config.string/-e. 指明pipeline内容,多用于测试
5.--pipeline.workers/-w.
6.--pipeline.batch.size/-b.
7.--path.data.
8.--debug
9.--config.test_and_exit/-t. 测试,检测测试.conf文件,有错则报错。
线上环境,推荐采用配置文件的方式来设定logstash的相关配置,可减少犯错机会,且文件便于进行版本化管理。而命令行形式多用于进行快速的配置测试、验证和检查。
5.logstash多实例运行方式:
#单节点启动多logstash实例的方式
#1.复制根目录下config文件夹,如命名为instance1,instance2。
cp -r config/ instance1
cp -r config/ instance2
#2.修改两个文件夹中的logstash.yml文件,修改path.data,同时制定pipeline文件位置
path.data=instance1
path.config=test/test1.conf
path.data=instance2
path.config=test/test2.conf
#3.配合两个不同的pipeline文件
test1.conf
test2.conf
#4.启动两个实例
bin/logstash --path.settings instance1
bin/logstash --path.settings instance26.Pipeline配置:
用于配置input、filter、output插件,配置语法:
1)主要有一下数据类型:
A、布尔类型Boolean isFaild => true、false
B、数值类型Number port => 33
C、字符串类型String name => "hello world"
D、数组Array/List uses => [{id => 1,name => bob},{id => 2,name => jame}]
E、哈希类型Hash match{
"field1" => "value1"
"field2" => "value2"
}
F、注释使用#
2)在配置中可饮用logstash event的属性(字段),主要有两种形式:
①直接引用字段值。
②在字符串中以sprintf方式引用。
A、直接引用:
使用[ ]即可,潜逃字段使用多层[ ] :
if [request] = ~ "index"{...}
if [ua][os] = ~ "windows"{...}
B、sprintf引用:
使用%{ }实现,
req => "request is %{request}"
ua => "ua is %{[ua][os]}"
支持判断与语法,从而扩展了配置的多样性:
if [action] == "login"{...}
if [logLevel] = "ERROR" and [de...]
if [foo] in [foobar]{...}
if [foo] in "foo"{...}
if "hello" in [greeting]{...}
if [foo] inf ["hello","world","foo"]{...}
if !("foo" in ["hello","world"]){...}
表达式主要包含如下操作符:
| 1.比较 | ==、!=、<、>、<=、>= |
| 2.正则是否匹配 | =~、!~ |
| 3.包含(字符串/数组) | in、not in |
| 4.布尔操作符 | and、or、nand、xor、! |
| 5.分组操作符 | ( ) |