Pytorch学习入门(一)--- 从torch7跳坑至pytorch --- Tensor
为什么入坑pytorch
一般来说,入门一新坑,先会被各种众说纷纭所“迷惑”。于是我看了这些。。
1. ICLR2017的论文现在越来越多用pytorch了,而不是tensorflow了。ICLR-17最全盘点:PyTorch超越TensorFlow,三巨头Hinton、Bengio、LeCun论文被拒,GAN泛滥
2. 2017年1月18日Facebook发行的PyTorch相比TensorFlow、MXNet有何优势?
3. 额,竟然课上老师让一个同学讲实例代码,用的就是pytorch。可以的。
4. 其实另一个原因就是,pytorch的很多函数写法几乎和torch是一致的。所以入坑快啊。
另外,Torch7貌似已经不再进行功能性的更新了,现在只是维护了。
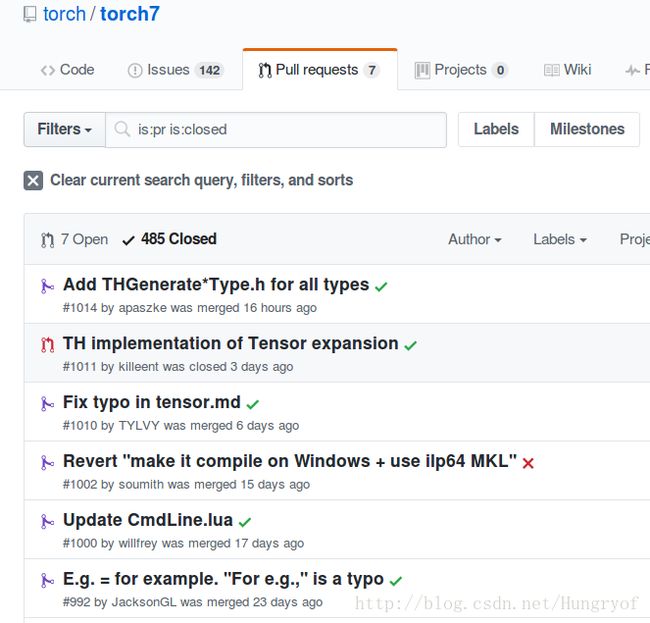
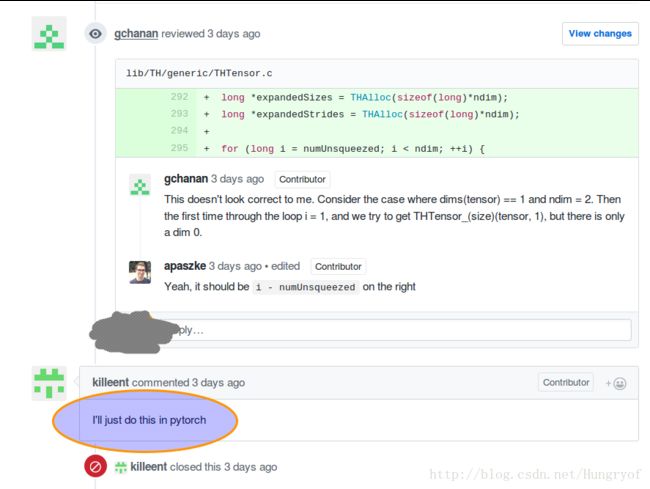
可以看到这些都是非功能性更新啊,唯独第二个TH implementation of Tensor expansion是一个非官方PR,点进去一看。。
再说点其他的,比如pixel2pixel和Cycle-GAN,本来都是torch7写的,然而作者本人也追加了pytorch版本的 pytorch-CycleGAN-and-pix2pix
, 现在 不管怎么说,反正我是准备入坑了。
从torch跳坑至pytorch
关于tensor的五大原则:
I. 从:到.的过度!现在没有所谓的torch.Tensor(3,4):fill(1)了,变成了
torch.Tensor(3,4).fill_(1)。
II. Inplace与Out-of-place, 前者加上后缀_,表示内部直接替换,而后者没有该后缀。
比如
a = torch.Tensor(3,4)
#内部替换值,a值已经被替换为2.5,就是相当于torch的 a:fill(2.5)
a.fill_(2.5)
#a的值没有被替换,相当于 torch的torch.add(a,4.0)
b = a.add(4.0)
# a的值已经全部替换为6.5,相当于torch的 torch.add(a,a,4.0)
c = a.add_(4.0) 可以看到,很多类似这样的torch的函数,内部值的替换与否,取决于参数的多少。一般来说,总共n个参数,第一个参数是可省略的,第一个参数就是存储计算后的值的tensor,比如[result] view([result,] tensor, sizes)。而pytorch则将这个功能更加明确化,通过轻微改变函数名(有无后缀_)来判定。
注意:有些函数比如narrow没有in-place版本,就是说没有.narrow_存在。有些函数比如fill_没有out-of-place存在,就是说没有.fill存在。其实很多通过自己稍微想想也差不多也能猜出,比如narrow取出tensor的某一维度的连续index的“几行/列”,怎么可能存在narrow_,不可能是out-of-place。反正多看文档就行。
III. pytorch既然是基于python接口的,当然是从zero indexing开始的。而且不是camel命名,采用中间下划线的命名方式。
b = a[:, 3:5] # selects all rows, 4th column and 5th column from a
# torch的方式
# b = a[{{},{4,6}}]比如indexAdd现在变成了index_add_, 因为index_add_是inplace函数。稍微解释一下index_add_就是沿着某一维度index,对该维度上的每个元素加一个值(根据给定的加值tensor,下面是z),并且是按照一定的order(一般用torch.LongTensor来构建表示order的tensor)。
x = torch.ones(5, 5)
print(x)
'''
1 1 1 1 1
1 1 1 1 1
1 1 1 1 1
1 1 1 1 1
1 1 1 1 1
[torch.FloatTensor of size 5x5]
'''
z = torch.Tensor(5, 2)
z[:, 0] = 10
z[:, 1] = 100
print(z)
'''
10 100
10 100
10 100
10 100
10 100
[torch.FloatTensor of size 5x2]
'''
#选定x的第二个维度(zero index的)
x.index_add_(1, torch.LongTensor([4, 0]), z)
print(x)
# 可以看到x的第五列(4)加的值是`z`的第一列,
# x的第一列(0)加的值是`z`的第二列。
'''
101 1 1 1 11
101 1 1 1 11
101 1 1 1 11
101 1 1 1 11
101 1 1 1 11
[torch.FloatTensor of size 5x5]
'''IV. Numpy与torch Tensor的相互转换
a_np = a.numpy() #直接这样转
a.add_(1) # 此时 a_np也变了。
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a) #这样numpy转pytorch tensor
np.add(a, 1, out=a)
print(a)
print(b) #a和b的值依旧一样。一句话:pytorch tensor与numpy的相互转换是内存共享的!!
V. 数据转GPU上
以前是:cuda()现在变成.cuda()呗,很一致。
# let us run this cell only if CUDA is available
if torch.cuda.is_available():
# creates a LongTensor and transfers it
# to GPU as torch.cuda.LongTensor
a = torch.LongTensor(10).fill_(3).cuda()
print(type(a)) #附加完整代码:
"""
Tensors
=======
Tensors behave almost exactly the same way in PyTorch as they do in
Torch.
Create a tensor of size (5 x 7) with uninitialized memory:
"""
import torch
a = torch.FloatTensor(5, 7)
###############################################################
# Initialize a tensor randomized with a normal distribution with mean=0, var=1:
a = torch.randn(5, 7)
print(a)
print(a.size())
###############################################################
# .. note::
# ``torch.Size`` is in fact a tuple, so it supports the same operations
#
# Inplace / Out-of-place
# ----------------------
#
# The first difference is that ALL operations on the tensor that operate
# in-place on it will have an ``_`` postfix. For example, ``add`` is the
# out-of-place version, and ``add_`` is the in-place version.
a.fill_(3.5)
# a has now been filled with the value 3.5
b = a.add(4.0)
# a is still filled with 3.5
# new tensor b is returned with values 3.5 + 4.0 = 7.5
print(a, b)
###############################################################
# Some operations like ``narrow`` do not have in-place versions, and
# hence, ``.narrow_`` does not exist. Similarly, some operations like
# ``fill_`` do not have an out-of-place version, so ``.fill`` does not
# exist.
#
# Zero Indexing
# -------------
#
# Another difference is that Tensors are zero-indexed. (In lua, tensors are
# one-indexed)
b = a[0, 3] # select 1st row, 4th column from a
###############################################################
# Tensors can be also indexed with Python's slicing
b = a[:, 3:5] # selects all rows, 4th column and 5th column from a
###############################################################
# No camel casing
# ---------------
#
# The next small difference is that all functions are now NOT camelCase
# anymore. For example ``indexAdd`` is now called ``index_add_``
x = torch.ones(5, 5)
print(x)
###############################################################
#
z = torch.Tensor(5, 2)
z[:, 0] = 10
z[:, 1] = 100
print(z)
###############################################################
#
x.index_add_(1, torch.LongTensor([4, 0]), z)
print(x)
###############################################################
# Numpy Bridge
# ------------
#
# Converting a torch Tensor to a numpy array and vice versa is a breeze.
# The torch Tensor and numpy array will share their underlying memory
# locations, and changing one will change the other.
#
# Converting torch Tensor to numpy Array
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
a = torch.ones(5)
print(a)
###############################################################
#
b = a.numpy()
print(b)
###############################################################
#
a.add_(1)
print(a)
print(b) # see how the numpy array changed in value
###############################################################
# Converting numpy Array to torch Tensor
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a)
np.add(a, 1, out=a)
print(a)
print(b) # see how changing the np array changed the torch Tensor automatically
###############################################################
# All the Tensors on the CPU except a CharTensor support converting to
# NumPy and back.
#
# CUDA Tensors
# ------------
#
# CUDA Tensors are nice and easy in pytorch, and transfering a CUDA tensor
# from the CPU to GPU will retain its underlying type.
# let us run this cell only if CUDA is available
if torch.cuda.is_available():
# creates a LongTensor and transfers it
# to GPU as torch.cuda.LongTensor
a = torch.LongTensor(10).fill_(3).cuda()
print(type(a))
b = a.cpu()
# transfers it to CPU, back to
# being a torch.LongTensor