Unicode字符串和非Unicode字符串
什么是Unicode?
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
字符串?
字符串或串(String)是由数字、字母、下划线组成的一串字符。一般记为 s=“a1a2···an”(n>=0)。它是编程语言中表示文本的数据类型。在程序设计中,字符串(string)为符号或数值的一个连续序列,如符号串(一串字符)或二进制数字串(一串二进制数字)。
UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码,由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码Unicode字符。用在网页上可以统一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
当我们弄清楚已上三种的的区别,相信很多人应该都懂了Unicode字符串和非Unicode字符串的区别吧!
最通俗的讲Unicode字符串和就是将普通字符串给标准化了,它为 每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
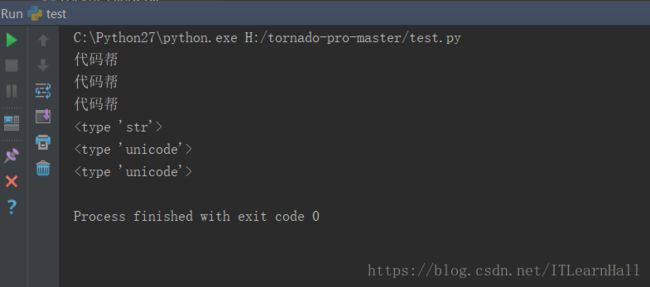
通过以下Python代码,希望大家能理解:
# -*- coding: utf-8 -*-
#!/usr/bin/env python
# @Time : 2018/7/3 10:03
# @Desc :
# @File : test.py
# @Software: PyCharm
if __name__ == '__main__':
#定义一般字符串
str="代码帮"
#字符串前面加u,定义标准unicode字符串
unicodestr=u"代码帮"
#将一般字符串转化为标准unicode字符串
unicodestrs = unicode(str, "utf-8")
print str
print unicodestr
print unicodestrs
print type(str)
print type(unicodestr)
print type(unicodestrs)