sharding-jdbc源码阅读之Adapter
15年做搜索的时候,业务那边对一些大的mysql表做了分表,记得好像是video表,给了我一个公式:vid%16。好在搜索业务对mysql表只是读取操作,改动还是比较简单,我在原来的读取类上,做了一层wrapper,在between 1 to 5000的情况下,计算该去哪张表读取。后面出来面试,也被问到分库分表这种概念,但手动去做,总是很坑。于是去了解了一下这一块的开源项目:
- **jdbc版:阿里的TDDL(未开源就不说了),当当的Sharding-JDBC
- **proxy版:Cobar和360的Atlas
首先聊一下这两种轻重方案的区别,引用sharding-jdbc作者张亮的话:
JDBC驱动版的优点:
1. 轻量,范围更加容易界定,只是JDBC增强,不包括ha,事务以及数据库元数据管理。
2. 开发的工作量较小,无需关注nio,各个数据库协议等。
3. 运维无需改动,无需关注中间件本身的HA。
4. 性能高,JDBC直连数据库,无需二次转发。
5. 可支持各种基于JDBC协议的数据库,如:MySQL,Oralce,SQLServer。
Proxy版的优点:
1. 可以负责更多的内容,将数据迁移,分布式事务等纳入Proxy的范畴。
2. 更有效的管理数据库的连接。
3. 整合大数据思路,将OLTP和OLAP分离处理。
因此两种方式互相可以互补,建议使用java的团队,且仅OLTP的互联网前端操作,又可能会使用多种数据库的情况,可以选择JDBC层的中间件;如果需要OLAP和OLTP混合,加以重量级的操作,如数据迁移,分布式事务等,可以考虑Proxy层的中间件。但目前开源的数据迁移和分布式事务的完善解决方案还不常见。NewSQL这种改变数据库引擎的方式就不在这里讨论了。
Shariding-JDBC以当前的定位来说,没有遇到不可解决的问题,但如果想做的更多(前面提到的数据迁移,分布式事务,元数据管理等),则需要向Proxy的方式靠拢。Shariding-JDBC想提供两种不同的使用方式,给使用者更自由的选择。
作为开发角度,自然是倾向于jdbc版本,于是前段时间,试用了一下sharding-jdbc,发现确实很方便,我们这边上线的一个分表业务目前也OK,于是就读了读sharding-jdbc源码。
Adapter
首先从架构图上看
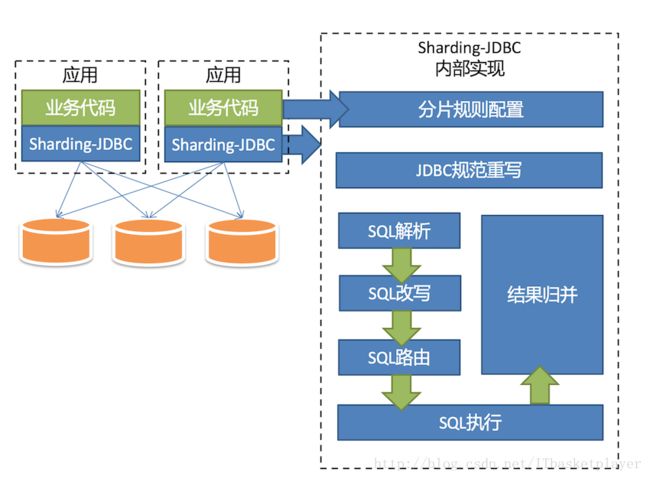
JDBC规范重写,是sharding-jdbc关键,至于SQL解析,目前还是用的Druid的Parser,分片规则也不是核心。我的思路是,先过一遍核心jdbc规范重写,然后再看一下它里面主从、分布式事务的实现。
jdbc操作mysql,几个重要概念是DataSource、Connection、Statement、PreparedStament,sharding-jdbc通过Adapter设计模式,包装了自己的ShardingDataSource、ShardingConnection、ShardingStatement、ShardingPreparedStament。在sharding-jdbc-core模块中,有个adapter包,里面分别有对应的adapter类。
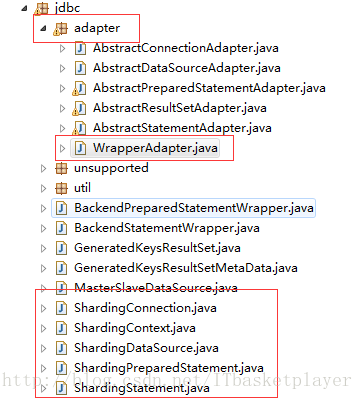
比如ShardingConnection实现了AbstractConnectionAdapter
首先从最外层ShardingConnection类进入,2个成员变量
@Getter(AccessLevel.PACKAGE)
private final ShardingContext shardingContext;
private final Map connectionMap = new HashMap<>(); ShardingContext 是个bean类,包含上下文环境3个重要的类
private final ShardingRule shardingRule;//分库分表规则配置对象,获取表分片策略、通过逻辑表查找分片规则等
private final SQLRouteEngine sqlRouteEngine;//路由引擎,根据sql解析结果,产生sql路由结果
private final ExecutorEngine executorEngine;//多线程执行引擎,采用guava的ListeningExecutorService跟elasticsearch多线程框架来讲,比较单一connectionMap只是一个内存缓存map,key是dataSourceName,value是原始的Connection。可以看出原始的Connection和ShardingConnection基本上n-1的关系。ShardingConnection重写了Connection
基本方法,比如:
@Override
public PreparedStatement prepareStatement(final String sql, final int[] columnIndexes) throws SQLException {
return new ShardingPreparedStatement(this, sql, columnIndexes);
}接下来重点是AbstractConnectionAdapter
里面重点封装的是Connection的事务相关操作
setAutoCommit
commit
rollback
close
操作对象是对外层开放的一个Connection集合
protected abstract Collection getConnections();
由此可以看出,ShardingConnection是Connection的一个代理者,实现方式是在ShardingConnection的父父级类WrapperAdapter中包装了2个反射方法
/**
* 记录方法调用.
*
* @param targetClass 目标类
* @param methodName 方法名称
* @param argumentTypes 参数类型
* @param arguments 参数
*/
protected final void recordMethodInvocation(final Class targetClass, final String methodName, final Class[] argumentTypes, final Object[] arguments) {
try {
jdbcMethodInvocations.add(new JdbcMethodInvocation(targetClass.getMethod(methodName, argumentTypes), arguments));
} catch (final NoSuchMethodException ex) {
throw new ShardingJdbcException(ex);
}
}
/**
* 回放记录的方法调用.
*
* @param target 目标对象
*/
protected final void replayMethodsInvocation(final Object target) {
for (JdbcMethodInvocation each : jdbcMethodInvocations) {
each.invoke(target);
}
}setReadOnly、setTransactionIsolation、setAutoCommit3个方法调用逻辑是,
一开始getConnections真实Connection为空的时候,只是把操作存起来,等真正有Connection的时候,,执行replayMethodsInvocation方法
比如ShardingConnection getConnection方法,ShardingPreparedStatement的routeSQL方法等,
AbstractConnectionAdapter类
@Override
public final void setReadOnly(final boolean readOnly) throws SQLException {
this.readOnly = readOnly;
if (getConnections().isEmpty()) {
recordMethodInvocation(Connection.class, "setReadOnly", new Class[] {boolean.class}, new Object[] {readOnly});
return;
}
for (Connection each : getConnections()) {
each.setReadOnly(readOnly);
}
}
ShardingConnection类
/**
* 根据数据源名称获取相应的数据库连接.
*
* @param dataSourceName 数据源名称
* @param sqlStatementType SQL语句类型
* @return 数据库连接
*/
public Connection getConnection(final String dataSourceName, final SQLStatementType sqlStatementType) throws SQLException {
Connection result = getConnectionInternal(dataSourceName, sqlStatementType);
replayMethodsInvocation(result);
return result;
}