Adversary Attack(对抗攻击)论文阅读笔记
引言:
最近开始学习Adversary Attack(对抗攻击)有关的内容,于是便从Ian GoodFollow的论文开始读起,后面每篇博客都会列举三篇的阅读笔记,来记录学习的经历。如果有讲得不到位或者您有什么想要补充的话,欢迎留言哦~
接下里将列举3篇论文:
- Explaining and Harnessing Adversarial Examples(ICLR2015)
- Adversarial machine learning at scale(ICLR2017)
- ADVERSARIAL EXAMPLES IN THE PHYSICAL WORLD(ICLR2017)
不过这三篇论文基本讲述的内容都是差不多的。
1. Explaining and Harnessing Adversarial Examples(ICLR2015)
本文主要探究的是对抗样本攻击原理的探究以及利用对抗思想进行训练
针对对抗样本,其往往是在原输入 x x x往其梯度方向进行扰动 η \eta η所达到的
x ~ = x + η \tilde{x} = x+\eta x~=x+η
虽然只是对 x x x进行了细微改动,但当进行计算后,会有
W T x ~ = W T x + W T η W^T\tilde{x}=W^Tx+W^T\eta WTx~=WTx+WTη
一旦 x x x的维度边高, η \eta η维度也会随之线性增加,由此即使是微不足道的改动(即 ∣ ∣ η ∣ ∣ ∞ < ϵ ||\eta||_\infin<\epsilon ∣∣η∣∣∞<ϵ),在进行 W T η W^T\eta WTη计算操作后,也会有比较大的结果,因此会影响模型的预测结果。
作者还发现了一种相比于dropout更有效的正则化方法:
J ~ ( θ , x , y ) = α J ( θ , x , y ) + ( 1 − α ) J ( θ , x + ϵ s i g n ( ▽ x J ( θ , x , y ) , y ) \tilde{J}(\theta, x, y) = \alpha J(\theta, x, y)+(1-\alpha)J(\theta, x+\epsilon sign(\triangledown_x J(\theta,x,y),y) J~(θ,x,y)=αJ(θ,x,y)+(1−α)J(θ,x+ϵsign(▽xJ(θ,x,y),y)
其中 x + ϵ s i g n ( ▽ x J ( θ , x , y ) x+\epsilon sign(\triangledown_x J(\theta,x,y) x+ϵsign(▽xJ(θ,x,y)即为对抗样本。
此外作者还发现即使是low capacity的模型如shallow RBF network
p ( y = 1 ∣ x ) = e x p ( ( x − μ ) T β ( x − μ ) ) p(y = 1|x)=exp((x-\mu)^T \beta (x-\mu)) p(y=1∣x)=exp((x−μ)Tβ(x−μ))
对adversary sample有免疫效果。其原因是针对一个分类模型,其预测结果是根据与 μ \mu μ的距离来确定的,在距离 μ \mu μ较远的地方,则不是本类或者置信度低。
另外作者指出,一个adversary sample在不同的模型上,其预测错误的类别基本一致,这就暴露出现有的模型存在的缺陷。
Summarys:
- 对抗性的例子可以解释为高维点积的一个性质。
它们是模型过于线性的结果,而不是过于非线性的结果。 - 由于对抗性扰动与模型的权向量高度一致,并且不同的模型在训练执行相同任务时学习相似的函数,因此可以解释不同模型间对抗性示例的泛化
- 证明对抗性训练可以进行正规化;甚至比dropout更有效。
- 易于优化的模型更容易受到对抗样本的影响。
- 线性模型缺乏抵抗对抗性扰动的能力;只有具有隐藏层的结构(where the universal approximator theorem applies)才应该被训练来抵抗对抗性扰动。
- 通过对输入分布进行训练的模型无法抵抗对抗样本。
- 集成学习也无法有效抵抗对抗样本。
2. Adversarial machine learning at scale(ICLR2017)
本文主要介绍生成对抗样本的方法和对抗训练的方法
FGSM:
X a d v = x + ϵ s i g n ( ▽ X J ( X , y t r u e ) ) X^{adv}=x+\epsilon sign(\triangledown_X J(X, y_{true})) Xadv=x+ϵsign(▽XJ(X,ytrue))
该方法的优点:易实施且计算高效
缺点:攻击成功率低
one-step target class methods:
X a d v = x − ϵ s i g n ( ▽ X J ( X , y t a r g e t ) ) X^{adv}=x-\epsilon sign(\triangledown_X J(X, y_{target})) Xadv=x−ϵsign(▽XJ(X,ytarget))
其中 y t a r g e t = a r g m i n y p ( y ∣ X ) y_{target}=argmin_y{p(y|X)} ytarget=argminyp(y∣X)即偏离最远的错误类。
Basic iterative method:
X 0 a d v = X , X N + 1 a d v = C l i p X , ϵ ( X N a d v + α s i g n ( ▽ X J ( X N a d v , y t r u e ) ) X_0^{adv}=X,X_{N+1}^{adv}=Clip_{X,\epsilon}(X_N^{adv}+\alpha sign(\triangledown_X J(X_N^{adv}, y_{true})) X0adv=X,XN+1adv=ClipX,ϵ(XNadv+αsign(▽XJ(XNadv,ytrue))
其中 C l i p x , ϵ ( A ) Clip_{x,\epsilon}(A) Clipx,ϵ(A)denots element-wise clipping A, with A i , j A_{i,j} Ai,jclipped to the r a n g e [ X i , j − ϵ , X i , j + ϵ ] range[X_{i,j}-\epsilon, X_{i,j}+\epsilon] range[Xi,j−ϵ,Xi,j+ϵ]
Iterative least-likely class method:
X 0 a d v = X , X N + 1 a d v = C l i p X , ϵ ( X N a d v − α s i g n ( ▽ X J ( X N a d v , y t a r g e t ) ) X_0^{adv}=X,X_{N+1}^{adv}=Clip_{X,\epsilon}(X_N^{adv}-\alpha sign(\triangledown_X J(X_N^{adv}, y_{target})) X0adv=X,XN+1adv=ClipX,ϵ(XNadv−αsign(▽XJ(XNadv,ytarget))
迭代方式是one-Step的"升级版"
疑惑点:总感觉迭代的 C l i p x , ϵ ( A ) Clip_{x,\epsilon}(A) Clipx,ϵ(A)不是论文中所写的 with A i , j A_{i,j} Ai,jclipped to the r a n g e [ X i , j − ϵ , X i , j + ϵ ] range[X_{i,j}-\epsilon, X_{i,j}+\epsilon] range[Xi,j−ϵ,Xi,j+ϵ]
采用的损失函数为
L o s s = 1 ( m − k ) + λ k ( ∑ i ∈ C L E A N L ( X i ∣ y i ) + λ ∑ i ∈ A D V L ( X i a d v ∣ y i ) ) Loss=\frac{1}{(m-k)+\lambda k}(\displaystyle\sum_{i\in CLEAN}{L(X_i|y_i})+\lambda \displaystyle\sum_{i\in ADV}{L(X_i^{adv}|y_i)}) Loss=(m−k)+λk1(i∈CLEAN∑L(Xi∣yi)+λi∈ADV∑L(Xiadv∣yi))
算法为

Label Leaking:
其现象为model可以正确分类通过 y t r u e y_{true} ytrue产生的adversary sample但不能正确分类通过 y t a r g e t y_{target} ytarget产生的adversary sample。其表达的实验结果为:

其中Step 1.1表示Iterative least-likely class method。从中可以看出,出现Lable Leaking后这些one-step算法在有adversary images上准确率反而会提高。作者给出的解释为one-step算法通过 y t r u e y_{true} ytrue所使用的变换简单以至于被网络给学习到了,所以才会出现这种结果。因此作者建议,FGSM或者其他方式不要通过 y t r u e y_{true} ytrue产生adversary sample,建议不要直接接触 y t r u e y_{true} ytrue,因此 y t a r g e t y_{target} ytarget是一个比较好的备选。
transfer rate:
采用iterate方式建立的adversary sample在不同的模型上的attack效果不及one-step

其中transfer rate表示在source model上成功attack的adversary sample与在target model上成功的sample数目之比。所以要想攻击一个黑盒模型,最佳的攻击样本建议为one-step建立的样本。
3. ADVERSARIAL EXAMPLES IN THE PHYSICAL WORLD(ICLR2017)
文章大体上与上述两篇文章一致,只是多了一些拓展说明。
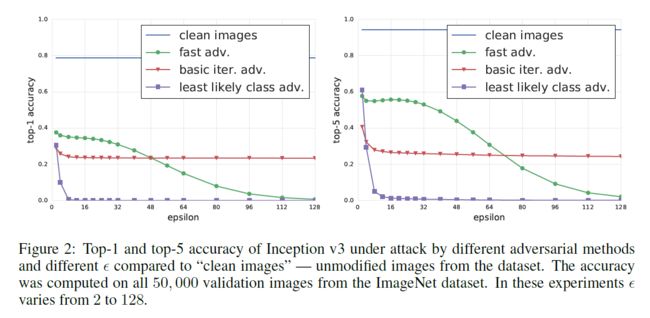
- basic iter方式提高 ϵ \epsilon ϵ带来的收益不大,且当 ϵ \epsilon ϵ超过一定阈值后,继续提高不会带来明显作用
- least likely class方式能够在 ϵ \epsilon ϵ比较小的情况下就能达到有效的攻击结果
- fast方式会随着 ϵ \epsilon ϵ的增加而逐渐提高攻击性能,但相比与least likely class方式而言,其提高性能的根本原因是在于破坏了原始图片的大部分信息,如下图.
Photo Transform:
突发奇想地提出了一种叫做Photo Tranform的黑盒变换,其实其变换的本质只是将origin image打印出来,作为一种transform。

首先考虑不加任何人为选择的随机采样结果
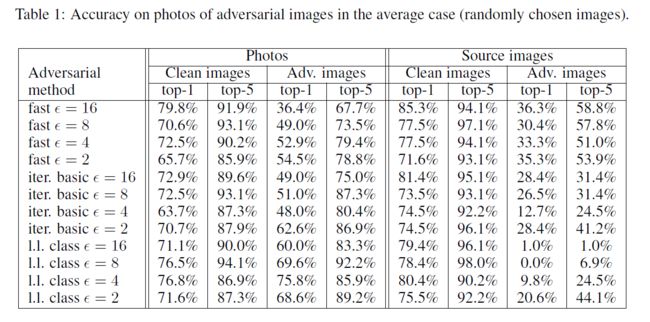
[Note]:这个table看起来有点难懂,按我自己的理解在,左边的 ϵ \epsilon ϵ针对的是Adv. images而Clean images是没有受到扰动的。
从table中可以看出,观察Adv. images对应的那2列(Photos和Source images),使用fast方法产生的Adv. images在进行Photo Transform时,准确率变化不明显,而其他iter方法产生的结果则差异较大,可以发现,当进行Photo Transform后,其准确率反而提升了。这里作者给出的解释为:基于iter的方法进行的扰动比较细微,而Photo Transform把这些细微的扰动给抵消了。因此就出现了准确率反而提高的结果。
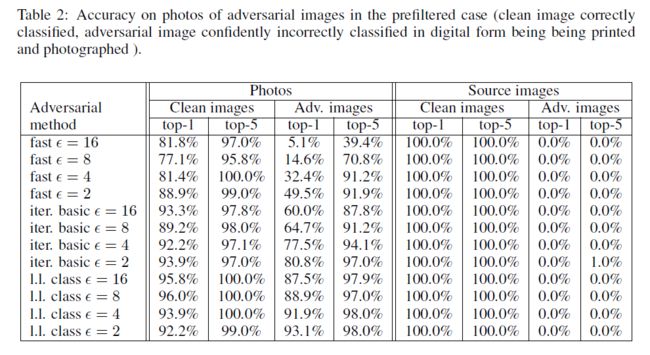
然后考虑人为选择的采样结果:(即在Clean image上正确分类,在Adversary image上错误分类的那些图片作为采样结果。)
如果觉得我有地方讲的不好的或者有错误的欢迎给我留言,谢谢大家阅读(点个赞我可是会很开心的哦)~