JSP页面请求响应过程中的编码解码
该片简要讲述:JSP页面传输过程中,浏览器与服务器的编码解码以及HTTP协议对URL进行的编码解码。
问题如下:
//所有的JSP页面的编码都是UTF-8的格式
//test1.jsp
<%@ page language="java" import="java.util.*,java.net.*" pageEncoding="UTF-8"%>
">链接
//test2.jsp
<%@ page language="java" import="java.util.*,java.net.*" pageEncoding="UTF-8"%>
<%
String name= URLDecoder.decode(request.getParameter("str"),"gb2312");
name =new String(name1.getBytes("ISO-8859-1"),"gb2312");
%>
<%=name %>
首先简要描述点击链接到页面显示过程:
点击链接 – 浏览器编码(HTTP URL 编码) – 服务器解码 – 构建返回数据体–服务器编码 – 浏览器解码。
POST请求不再多说,乱码主要发生在GET请求且URL后面追加了中文参数。
上述例子,过程应该是这样:
① 首先在页面中进行了URL编码:
结果如下:
链接
//这里手动进行URL编码,等效于浏览器对中文进行编码。
//因为参数在url上面,是GET请求,故而URL编码解码是浏览器和服务器的关系,与我们无关。
//如果不做设置,默认编码方式为是ISO-8859-1。
② 浏览器编码
点击查看浏览器端的编码。
-
因为GET请求,只有URL(参数附加于URL),故只对URL进行编码。
-
因为非直接在浏览器输入地址进行请求,而是点击文档内链接。故编码依据文档编码 —UTF-8
-
因为JSP页面手动指定了编码格式,且进行了URL编码。
③ HTTP传输
数据在网络中以报文的形式,二进制流的格式进行传输。服务器拿到的path之后需进行解析。这个过程默认编码方案为ISO-8859-1。
至此,是这样子的:ISO-8859-1(UTF-8(链接))。
④ 服务器解码
web服务器接收到客户端的请求后,会将其内容转给web容器来处理;
因为接到的请求path(url)是编码过的二进制流,所以在处理前会将其转换成ASCII码 。但是请求中可能还有部分参数和消息体的数据是经过编码的(例如中文字符被编码),这里就涉及到对请求内容和参数进行解码的问题。
Tomcat 默认对url 使用 ISO-8859-1解码。注意:ISO-8859-1 为单字节表示。
所以,无论你前面浏览器进行了什么编码,尘归尘,土归土,一切都还原到字节(不过这里的字节是由特定字符集转换而来的,即 第一个页面的GB2312)!!!
在这里,剥去了外面的ISO-8859-1,剩下UTF-8(链接)。
⑤ 过程描述
原URL---->GET时浏览器根据HTTP头的Content-Type的charset,POST根据(content="text/html; charset=utf-8")对URL进行编码或者利用JavaScript(如果JavaScript编码了则浏览器一看都是ASCII字符就不再编码)使用GBK或者UTF-8等编码对URL进行编码
---->ASCII字符 + %
---->以iso-8859-1编码方式转换为二进制
---->随请求头一起发送出去(GET没有请求实体, POST有)
---->服务器接收到经过iso-8859-1编码后的URL
---->服务器用iso-8859-1编码进行解码
---->得到值(这里得到URL中文参数的字节信息)
⑥ Tomcat 返回响应
构建数据体,设置响应类型和编码(UTF-8)。。。
ContentType : text/html;charset=UTF-8
该过程中会拿到请求传过来的参数:
方法一:
String name= URLDecoder.decode(request.getParameter("str"),"gb2312");
//此时name仍旧为乱码
name=new String(name2.getBytes("ISO-8859-1"));
//默认使用系统编码,可使用System.getProperty("file.encode");进行查看
Charset.defaultCharset()方法如下所示:
public static Charset defaultCharset() {
if (defaultCharset == null) {
synchronized (Charset.class) {
String csn = AccessController.doPrivileged(
new GetPropertyAction("file.encoding"));
Charset cs = lookup(csn);
if (cs != null)
defaultCharset = cs;
else
defaultCharset = forName("UTF-8");
}
}
return defaultCharset;
}
使用request.getParameter()获取的数据是被服务器误认为ISO-8859-1编码的,也就是说客户端发送过来的数据无论是UTF-8还是GBK,服务器都认为是ISO-8859-1,这就说明我们需要在使用request.getParameter()获取数据后,再转发成正确的编码。
如下所示,则正确解码:
String name=URLDecoder.decode("%D6%D0%B9%FA%C8%CB", "gb2312");
// name 中国人
注意,%D6%D0%B9%FA%C8%C直接使用gb2312解码可得到正确结果。但是如果使用request.getParameter获取str则会得到乱码ÖйúÈË。
那么,为什么不直接使用ISO-8859-1获取字节,然后再使用GBK或者gb2312解码呢?URLDecoder.decode(request.getParameter("str"),"gb2312");完全就是多余了。
ISO-8859-1向下兼容ASCII,并且HTTP通信过程中默认使用的就是ISO-8859-1编码。
方法二:
String name=new String(request.getParameter("str").getBytes("ISO-8859-1"),"GBK");
//GBK GB2312
//String name2 = new String(request.getParameter("str").getBytes("ISO-8859-1"),"UTF-8")
//name2 ���
其中方法一首先进行了URL解码,其次直接使用new String([]bytes,charset)进行构建字符串。
方法二则直接使用new String([]bytes,charset)进行构建字符串。
服务器拿到的是字节流,因为 Tomcat 默认对URL使用ISO-8859-1进行解码,所以可以直接直接使用new String([]bytes,charset)进行构建字符串!需要注意的是这里的charset需要与页面进行URL编码时候的编码集一致。
方法三,使用request.getQueryString();获取Query String。
既然参数在URL后面,那么就在Query Data里面可以使用request.getQueryString();方法获取,如下所示:
String queryData = request.getQueryString();
//queryData: str=%D6%D0%B9%FA%C8%CB
//截取str 值,再使用URLDecoder.decode()即可。
⑦ 浏览器解析响应
浏览器拿到响应信息,开始进行解析。
首先会获取解码类型:UTF-8
点击查看浏览器解析过程。浏览器解析HTML文档
【Tips】:
这里说明一下何为URL编码解码:
编码:
URLEncoder.encode("中国人","gbk")
**即:`%D6%D0%B9%FA%C8%CB`**
将字符串以特定的编码格式转化成application/x-www-form-urlencoded 格式
根据2005年发布的RFC3986“%编码”规范:
- 对URL中属于ASCII字符集的非保留字不做编码;
- 对URL中的保留字需要取其ASCII内码,然后加上“%”前缀将该字符进行替换(编码);
- 对于URL中的非ASCII字符需要取其Unicode内码,然后加上“%”前缀将该字符进行替换(编码)。
由于这种编码是采用“%”加上字符内码的方式,所以,有些地方也称其为“百分号编码”。
JAVA源码翻译:

解码则反之 。
点击查看Http协议中的编码解码
题外话 :
如果 第一个页面不进行URL编码呢?
链接-->
测试的谷歌浏览器:
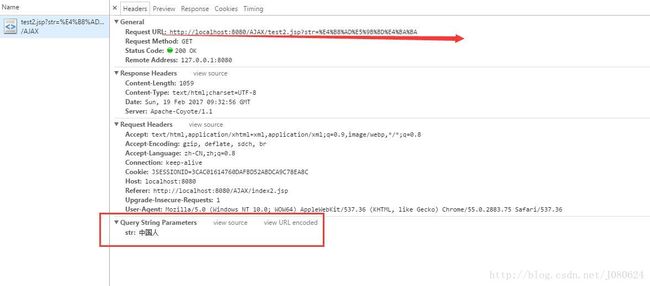
如上图所示,浏览器会自动根据页面编码(UTF-8)进行URL编码。
可直接使用上述方法二进行获取。
String name=new String(request.getParameter("str").getBytes("ISO-8859-1"),"UTF-8");
//注意页面编码为UTF-8
需要注意JSP页面中的Java代码<%=name %>,其实对应编译后的 out.print(name);故而不需要再加;。另外out变量声明的对象为JspWriter,其类继承示意图如下: