数据分析学习笔记
目录
一.介绍
二.代码实现
一.介绍
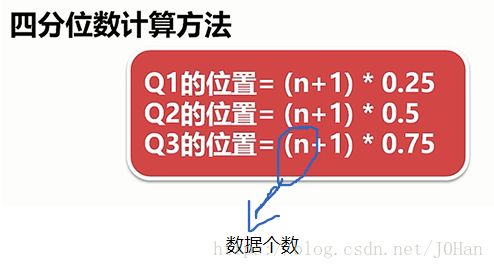
集中趋势:均值,中位数,众数,分位数(常用四分位数)
离中趋势:标准差,方差

数据分布:偏态与峰度

S为+:正偏 均值大 为负则反之
数据分布集中强度K越大顶越尖越小越平缓 正态分布的K=3

卡方分布:几个标准正态分布(均值为0方差为1)的平方和满足的分布 ---- 待补充
T分布:正态分布的一个随机变量除以一个服从卡方分布的变量----用来根据小样本来估计呈正态分布且方差未知的总体的均值。
F分布:构成两个服从卡方分布的随机变量的比值构成的(即就是两个卡方分布的商)---- 待补充
二.代码实现
# -*- coding:utf-8 -*-
# @Author: Han
import pandas as pd
import scipy.stats as ss
df = pd.read_csv("\Data\HR.csv")
# DataFrame 和 Series 两种数据结构
df.mean() # 求均值
df.median() # 中位数
df.quantile(q=0.25) # 四分位数根据参数q
df.mode() # 众数
df.std() # 离标准差
df.var() #方差
df.sum() #求和
df.skew() #偏态系数
df.kurt() #峰态系数
ss.norm() # 正态分布
ss.norm.stats(moments="mvsk") #
ss.norm.pdf(0.0) #指定横坐标返回竖坐标
ss.norm.ppf(0.9) #累计值 积分为0.9时 从-无穷大到返回值
ss.norm.cdf(2) #从-无穷积到2的累计概率
ss.norm.cdf(2)-ss.norm.cdf(-2)
ss.norm.rvs(size=10) #得到10个符合正态分布的数字
ss.chi2() #卡方分布
ss.t() # t分布
ss.f() # f分布
df.sample(n=10) # 按个数抽样
df.sample(frac=0.001) #按比例抽样重要的是学会查文档