论文笔记:Word2Vec的发展与应用
概述
看了一些Word2Vec的一些相关文章,筛选一下主要分为两类(感兴趣可以看原文)。一是有关于Word2Vec的发展,主要是以下4篇文章起到奠基性的作用
A Neural Probabilistic Language Model.2003 (NNLM)
Recurrent neural network based language model.2010 (RNNLM)
Distributed Representations of Words and Phrases and their Compositionality.2013 (Skip Gram Model and CBOW)
Efficient Estimation of Word Representations in Vector Space.2013 (Skip Gram Model and CBOW)
二是关于Word2Vec应用的一些文章,一些有趣的idea像是如下的文章
Linguistic Regularities in Continuous Space Word Representations.2013
Exploiting Similarities among Languages for Machine Translation.2013
Distributed Representations of Sentences and Documents.2014
Development
NNLM: A Neural Probabilistic Language Model.2003
这篇文章主要解决在此之前的自然语言模型是统计语言模型和基于统计语言模型n-gram模型的维度灾难问题。

统计语言模型的基本想法就是对于一句话,在给定前几个词的情况下,统计出现下一个词的概率。这样一句话的出现概率就是第一个词出现的概率 P(W1) 乘上在第一个词给定的情况下出现第二个词的概率 P(W2|W1) , 依此类推,一句话的概率就是上图第一行的联合条件概率乘积。
N-gram模型就是假设一个词出现的概率只考察前后该词前后n个词,以此来降低复杂度。
这些模型的问题就是复杂度非常高,例如:

上图的free parameters就是指前面语言模型的各个概率P. 统计语言模型就是要统计所有文本将所有概率P确定下来。
文章的作者要解决这一问题,采用distributed vectors来表示每一个词,一句话的上下文语境用训练好的vector的值和网络参数来表达。如下:

作者给出的网络结构如下:

如图,首先有一个全局的矩阵C,通过C将一个词w转换为向量C(w)。然后用这些向量作为一个三层神经网络的输入,最终训练出参数和所有词向量的矩阵C。
作者首次使用神经网络来表示自然语言模型,大大降低了计算复杂度(复杂度在后面统一比较)。作者实际上已经使用了词向量但是没有发现这些向量蕴含的语义和语法内容,只是用它来作为自然语言模型的工具。
RNNLM : Recurrent neural network based language model.2010
NNLM有一个问题就是对于一个词,训练的时候它的上下文只取该词前面的n个词,如果n过大,训练复杂度增大;n过小,覆盖的上下文不够。本文作者就利用RNN的特性来解决这一问题。
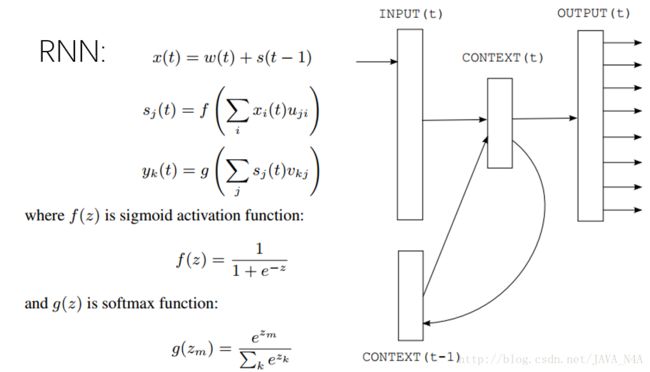
如上图,RNNLM中将隐藏层视为context层,每一次迭代中,输入由新的输入和前一次的context层共同组成。这样上下文的宽度n不用很大,也可以利用到距离当前词足够远的词带来的影响。
但是本文作者同样是没有注意到词向量蕴含的语义和语法内容
Skip Gram Model and CBOW
“Distributed Representations of Words and Phrases and their Compositionality”和“Efficient Estimation of Word Representations in Vector Space”两篇文章提出了Skip Gram Model and CBOW两个模型。
CBOW模型:
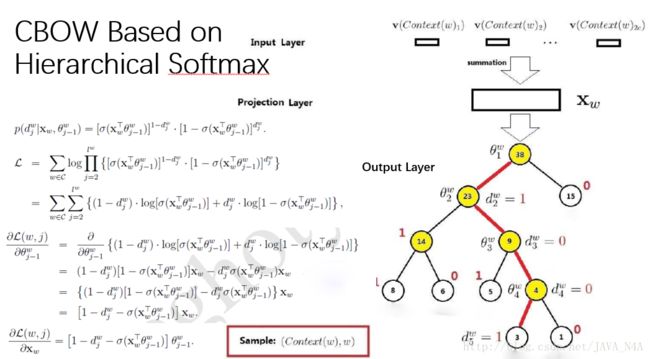
CBOW模型相比于前两个模型,去掉了隐藏层。输出不是线性的softmax,而是基于huffman树的softmax,这样首先使得输出层复杂度由N降到log(N),其次很好的应用了huffman树的聚类效果。
Skip Gram Model与CBOW类似,只是CBOW是由当前词的上下文来推导出当前词汇,而Skip Gram Model则是反过来。
这两个模型首先是降低了计算复杂度,如下图比较:

按照文章的说法
This makes the training extremely efficient: an optimized single-machine implementation can train on more than 100 billion words in one day
此外最重要的是,作者首次察觉到词向量蕴含了丰富的语法和语义的含义。比如
vec(“Madrid”) - vec(“Spain”) + vec(“France”) is closer to vec(“Paris”) .
文章中用了大量篇幅和实现表现词向量的良好特性
Application
然后还有些应用词向量的文章。
Exploiting Similarities among Languages for Machine Translation
文章的想法非常简单。在一种语言中一个词的词向量为 Xi ,另一种语言中其对应的词的词向量为 Zi ,作者做了一些实验发现这写词在各自的语言空间中的相对位置关系有一定的相似性,如下图:

所以作者认为,只要训练一个转移矩阵W,使得 Xi 经过变换 WXi 转换到与 Zi 接近的位置,再转换成对应的词,这样就完成了翻译,训练目标如下图:
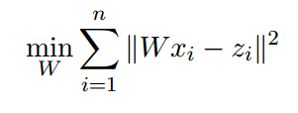
作者想法很新颖,但是模型结构非常简单,训练的过程中只考虑到词,没有融入整句话的语义概念。翻译的效果比不上之前的翻译模型,只是开阔了一种新的思路。
Distributed Representations of Sentences and Documents
这一篇文章进一步扩展词向量,提出一种方法来训练句子和文章的向量。

如图,作者的想法也非常简单,在原有的CBOW模型上,作者在输入层额外添加了一个paragraph vector。这个向量是由段落决定的,文章的每一段对应一个向量,在训练过程中,同一段落内部使用同一个向量。这一个向量就代表着该段落的context and semantic.
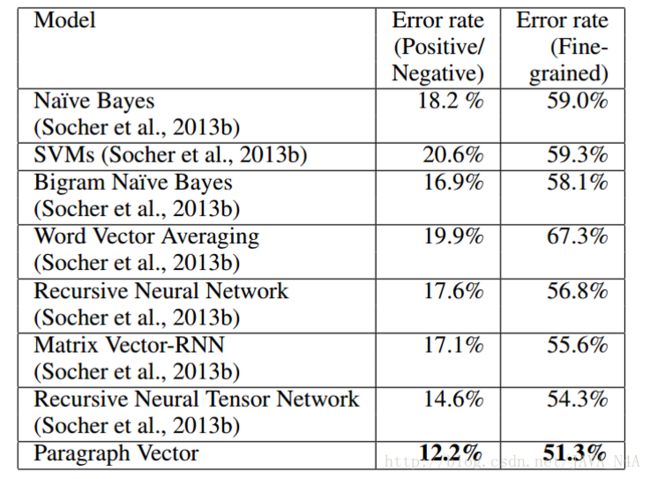
这是一个非常简单但是巧妙的想法,效果也相当不错。作者做了一个实验来来评估模型,实验是分析一段评论是positive or negative,数据集是Stanford Sentiment Treebank Dataset。实验结果如下,错误率要低于之前的模型。
这一篇训练sentence vector还可以应用到前一篇翻译的工作中,可以弥补其没有融入整句话的语义概念的不足之处。
附:PV_DM(based on CBOW)核心代码
这是自实现的一段PV_DM核心代码,参数还没有调好。不过实现过程中,对于论文中写的比较概括模糊的地方有了比较清晰的认识。
# -*- coding: utf-8 -*-
"""
Created on Tue 3/17 17:07:40 2017
@author: N4A
"""
import numpy as np
import json
import math
import datetime
import random
import doc_manager as dm #自实现,简单的文档读取工作
# super parameter
# window size
window = 5
# 学习率
start_alpha = 0.03
# 控制内积范围,超过范围的再加sigmoid很小,可以丢弃
MAX_EXP = 10
# 向量维度
layer_size = 100
# internal parameter
doc_num = 0
unit_num = 0
# 单元向量表
word_vec_table = {}
# 文档向量表
doc_vec_table = {}
# 参数表, 参数个数即内部节点个数为叶节点个数(unit_num)-1, 初始化为正态分布取值
para_table = {}
# 所有用户,相当于所有文章
docs = {}
# 所有地点,相当于所有单词
words_tree = {}
# the index of the doc in the doc_vec_table
doc_index = {}
# the index of the word in the word_vec_table
word_index = {}
# 开始时间
start_time = datetime.datetime.now()
# iteration time
train_num = 0
def init_data(doc_path, words_path):
if not(doc_path or words_path):
print('please fill doc_path and words_path')
exit()
global docs
global words_tree
# default 'data/movielen/handled/doc.txt'
docs = dm.read_handled_data(doc_path)
# default 'data/movielen/handled/tree.txt'
words_tree = dm.read_handled_data(words_path)
def init_basic_parameter(p_layer_size=layer_size, p_window_size=window,
p_learn_alpha=start_alpha, p_MAX_EXP=MAX_EXP):
global docs
global words_tree
if docs == {} or words_tree == {}:
print('Err: please init data with doc_path and words_path first')
exit()
global layer_size
global window
global MAX_EXP
global start_alpha
layer_size = p_layer_size
window = p_window_size
MAX_EXP = p_MAX_EXP
start_alpha = p_learn_alpha
global unit_num
global doc_num
unit_num = len(words_tree)
doc_num = len(docs)
global para_table
global doc_vec_table
global word_vec_table
# 单元向量表
word_vec_table = np.random.uniform(0, 1, layer_size * unit_num).reshape(unit_num, layer_size)
# 参数表, 参数个数即内部节点个数为叶节点个数(unit_num)-1, 初始化为正态分布取值
para_table = np.random.normal(0.0, 1, layer_size * (unit_num - 1)).reshape(unit_num - 1, layer_size)
# 文档向量表
doc_vec_table = np.random.uniform(0, 1, layer_size * doc_num).reshape(doc_num, layer_size)
# map from the key of words, docs to index of vector table
index = 0
for word in words_tree.keys():
word_index[word] = index
index += 1
index = 0
for doc in docs.keys():
doc_index[doc] = index
index += 1
def sigmoid(x):
return 1 / (1 + math.exp(-x))
def normalize(vec):
average, std = np.average(vec), np.std(vec)
return (vec - average) / std
# show message of the training process
def show_message():
def by_similar(word_s):
return word_s[1]
# check for similar
num = 0
words = ['will', 'to', 'like', 'good', 'eight', 'or', 'dog', 'movie']
for word in words:
if word not in words_tree:
continue
vec = word_vec_table[word_index[word]]
similar = []
for other in words_tree.keys():
other_vec = word_vec_table[word_index[other]]
similar.append((other, np.dot(vec, other_vec)))
similar_sorted = sorted(similar, key=by_similar, reverse=True)
print(word, ':', list(map(lambda x: x[0], similar_sorted[0:10])))
num += 1
if num > 10:
break
# 训练doc_key指定的文章
def DV_Enhanced_CBOW(doc_key):
sent = docs[doc_key][0].split('\t') # 文章(多篇文章只取第一篇),用户访问地点序列
sent_len = len(sent)
# start train
for pos in range(sent_len):
neul = np.zeros(layer_size) # 隐藏层
neule = np.zeros(layer_size) # 记录隐藏层累积变化量
word = sent[pos] # 地点id string
if word not in words_tree: # 不存在该词则忽略
continue
# 计算context向量和
# 先加上本段文章向量,与pos无关
neul += doc_vec_table[doc_index[doc_key]]
num = random.randint(0, window) # 随机起点,并不是严格从0开始
start = num
while start < 2 * window + 1:
cur_pos = pos - window + start
# 左右几个词不包含当前词
# or 现在位置超过范围,则跳过 , and ignore ''
if start == window or cur_pos < 0 or cur_pos >= sent_len or sent[cur_pos] == '':
start += 1
continue
# 计算context向量和
neul += word_vec_table[word_index[sent[cur_pos]]]
start += 1
# 利用霍夫曼树计算
word_in_tree = words_tree[word] # 当前地点
points = word_in_tree['points']
codes = word_in_tree['codes']
codes_len = len(codes)
for layer_index in range(codes_len):
# 计算内积
dot = np.dot(neul, para_table[points[layer_index]])
# 内积不在范围内直接丢弃
if dot > MAX_EXP or dot < -MAX_EXP:
continue
# simoid
dot = sigmoid(dot)
# 偏导数的公用部分*学习率alpha
g = (1 - codes[layer_index] - dot) * start_alpha
# 反向更新参数
# 先更新隐藏层
neule += g * para_table[points[layer_index]]
# 后更新参数
para_table[points[layer_index]] += g * neul
# normalize
para_table[points[layer_index]] = normalize(para_table[points[layer_index]])
# 更新doc vector
doc_vec_index = doc_index[doc_key]
doc_vec_table[doc_vec_index] += neule
# normalize
doc_vec_table[doc_vec_index] = normalize(doc_vec_table[doc_vec_index])
# 将更新传递到词向量
start = num
while start < 2 * window + 1:
cur_pos = pos - window + start
# 左右几个词不包含当前词
# or 现在位置超过范围,则跳过 and ignore ''
if start == window or cur_pos < 0 or cur_pos >= sent_len or sent[cur_pos] == '':
start += 1
continue
# 更新词向量
vec_index = word_index[sent[cur_pos]]
word_vec_table[vec_index] += neule
# 修正词向量,normalize
word_vec_table[vec_index] = normalize(word_vec_table[vec_index])
start += 1
# 输出现在的时间
global train_num
train_num += 1
if train_num % 500 == 0:
print('Iteration: ', train_num, ',time: ', (datetime.datetime.now() - start_time).seconds, 's')
show_message()
def ndarray_to_json(ndarr):
ret = []
for vec in ndarr:
ret.append(list(map(lambda x: float(x), list(vec))))
return json.dumps(ret)
# test
if __name__ == '__main__':
init_data('data/movielen/handled/doc.txt', 'data/movielen/handled/tree.txt')
init_basic_parameter(layer_size, window, start_alpha, MAX_EXP)
for iter_num in range(40):
for doc_key in docs.keys():
DV_Enhanced_CBOW(doc_key)
# output vec
word = open('data/movielen/vector/word_vec.txt', 'w')
doc = open('data/movielen/vector/doc_vec.txt', 'w')
word.write(ndarray_to_json(word_vec_table))
doc.write(ndarray_to_json(doc_vec_table))
word.close()
doc.close()