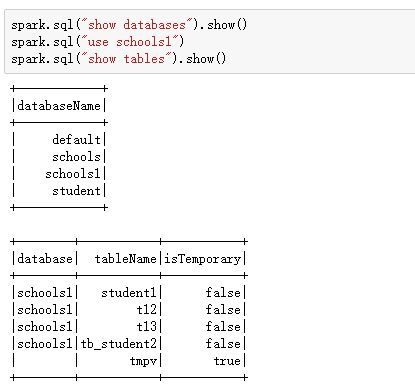
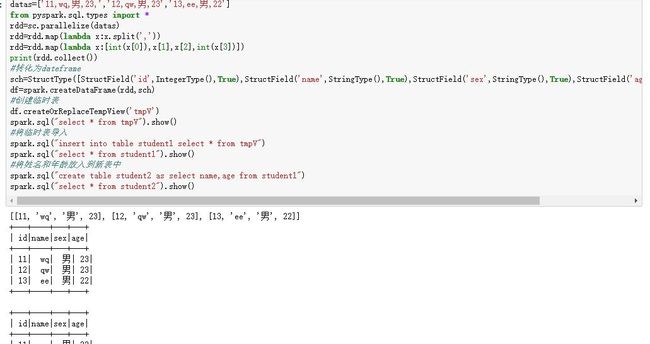
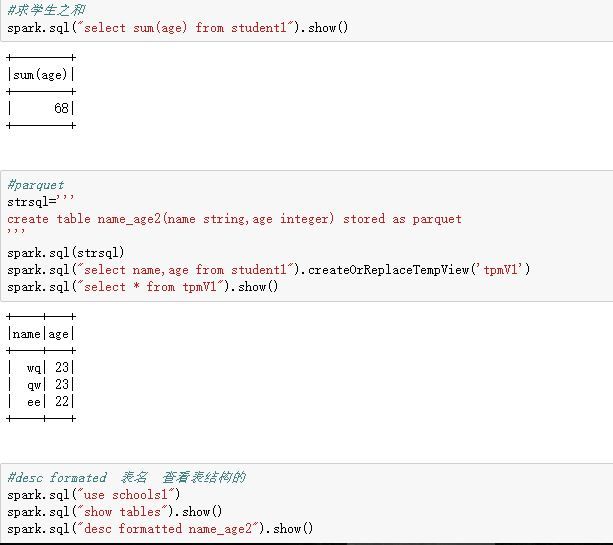
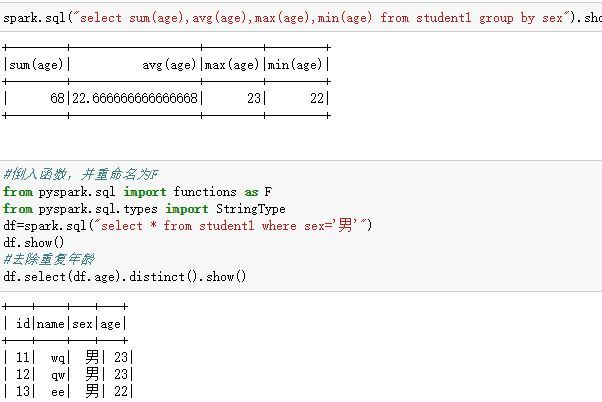
spark连接hive及pyspark函数
以下就是hive在spark里的用法
#导入时间
from pyspark.sql.functions import add_months
df = spark.createDataFrame([('2015-04-08',)], ['dt'])
df.select(add_months(df.dt, 1).alias('next_month')).collect()
#结果为[Row(next_month=datetime.date(2015, 5, 8))]#字符串拼接
from pyspark.sql.functions import concat, concat_ws
df = spark.createDataFrame([('abcd','123')], ['s', 'd'])
# 1.直接拼接
df.select(concat(df.s, df.d).alias('s')).show()
# abcd123
# 2.指定拼接符
df.select(concat_ws('-', df.s, df.d).alias('s')).show()
# 'abcd-123'from pyspark.sql.functions import collect_list
df2 = spark.createDataFrame([(2,), (5,), (5,)], ('age',))
df2.agg(collect_list('age')).collect()
#结果[Row(collect_list(age)=[2, 5, 5])]from pyspark.sql.functions import bround
spark.createDataFrame([(2.5,)], ['a']).select(bround('a', 0).alias('r')).collect()
#结果[Row(r=2.0)]
from pyspark.sql.functions import array_contains
df = spark.createDataFrame([(["a", "b", "c"],), ([],)], ['data'])
df.select(array_contains(df.data, "a")).collect()
#结果[Row(array_contains(data, a)=True), Row(array_contains(data, a)=False)]from pyspark.sql.functions import conv
df = spark.createDataFrame([(1,1)], ['n'])
df.select(conv(df.n, 2, 16).alias('hex')).collect()
#[Row(hex='1')]
from pyspark.sql.functions import concat_ws
df = spark.createDataFrame([('abcd','123')], ['s', 'd'])
df.select(concat_ws('-', df.s, df.d).alias('s')).collect()
#结果[Row(s='abcd-123')]
from pyspark.sql.functions import concat
df = spark.createDataFrame([('abcd','123')], ['s', 'd'])
df.select(concat(df.s, df.d).alias('s')).collect()
#结果[Row(s='abcd123')]
from pyspark.sql.functions import collect_set
df2 = spark.createDataFrame([(2,), (5,), (5,)], ('age',))
df2.agg(collect_set('age')).collect()
#结果[Row(collect_set(age)=[5, 2])]