Flume内部原理与高可靠传输
Flume内部原理与高可靠传输
本篇介绍Flume内部启动原理特性与过程。
Flume简介
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera,但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
Flume的核心概念
Event:是Flume数据传输的基本单元。flume以事件的形式将数据从源头传送到最终的目的。Event由可选的hearders和载有数据的一个byte array构成。
Clinet:是一个将原始数据包装成events并且发送它们到一个或多个agent的实体。
Agent:一个Agent包含Sources, Channels, Sinks和其他组件,它利用这些组件将events从一个节点传输到另一个节点或最终目的。
Source:负责接收events或通过特殊机制产生events,并将events批量的放到一个或多个Channels。
Channel:位于Source和Sink之间,用于缓存进来的events,当Sink成功的将events发送到下一跳的channel或最终目的,events从Channel移除。
Sink:负责将events传输到下一跳或最终目的,成功完成后将events从channel移除。
其中Event是Flume数据传输的基本单元。flume以事件的形式将数据从源头传送到最终的目的。Event由可选的hearders和载有数据的一个byte array构成。
载有的数据对flume是不透明的。
Headers是容纳了key-value字符串对的无序集合,key在集合内是唯一的。
Headers可以在上下文路由中使用扩展。
Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source,比如上图中的Web Server生成。当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。

Flume的数据流细化一下则是首先Source捕捉到外部进来的Events,然后把Events提交给ChannelProcessor,ChannelProcessor先走一遍Interceptor(进行一些过滤处理),然后通过ChannelSelector引用对象获得Channel列表,使用事务方式把Events提交到Channel,因此Source的Events提交到Channel实际上是在ChannelProcessor中进行的;而Sink则通过SinkProcessor去Channel中获得Events并消费Events,整个过程就是一个生产者消费者模式。
高可靠传输实现原理
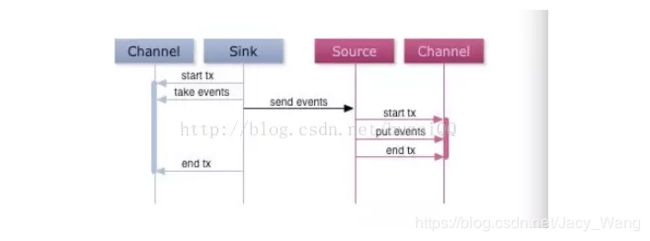
Flume使用事务的办法来保证event的可靠传递。Source和Sink分别被封装在事务中,这些事务由保存event的存储提供或者由 Channel提供。这就保证了event在数据流的点对点传输中是可靠的。在多级数据流中,如下图,上一级的Sink和下一级的Source都被包含在事务中,保证数据可靠地从一个Channel到另一个Channel转移
其次,数据流中 Channel的持久性。Flume中MemoryChannel是可能丢失数据的(当Agent死掉时),而FileChannel是持久性的,提供类似mysql的日志机制,保证数据不丢失。
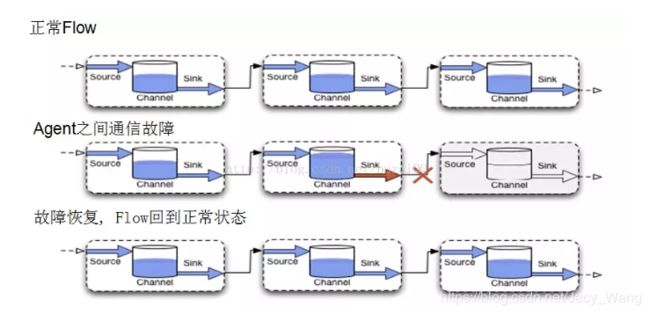
当一个正常的Flow运行时,每个Agent中的Channel中的Events数量是均衡(消费速度大于生产速度的情况),而一旦Agent直接出现故障,那么Channel就会暂时持有Events,直到故障恢复(MemoryChannel可能会丢失Events)。
Flume启动分析

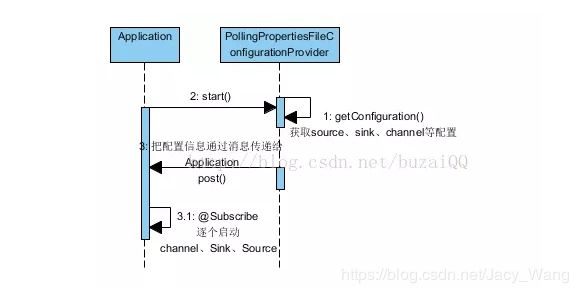
Flume的Agent启动是从Application的main函数开始的,首先把自己的实例注册到了EventBus,然后通过LifecycleAware模式(类似Tomcat的开始结束模式),创建PollingPropertiesFileConfigurationProvider对象并执行start()函数,在start()函数中,通过线程池启动了一个FileWatcherRunnable任务去不断的检查启动文件是否修改,第一次或者发现文件修改了的时候就去读取配置文件,并通过EvenBus的post()方法响应读取结果,而Application的主线程因为注册过EventBus,handleConfigurationEvent()函数获得post()事件消息后就会执行先stopAllComponents(),然后startAllComponents(conf),当执行startAllComponents函数的时候,就会启动channel、sink和source这三个核心组件,注意启动顺序是先channel,后sink,最后source,这次才不会有消息丢失问题发生。整个启动过程如图所示。
简化来说:
第一步:Application主线程启动,通过PollingPropertiesFileConfigurationProvider获取source、sink、channel等配置信息
第二步:PollingPropertiesFileConfigurationProvider把配置信息通过事件总线广播给Application主线程
第三步:Application主线程重新启动channel、sink和source
Source分析
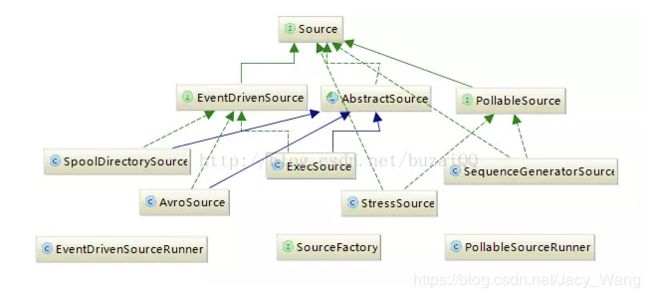
Source的继承关系类图如图所示,所有source均实现自source接口,接口方法只有两个:setChannelProcessor()和getChannelProcessor(),所以所有source具体的业务实现(比如把Events发送给Channel以及过程中的事务实现都是在ChannelProcessor中实现的)。

source又分为两种类型:EventDrivenSource和PollableSource,PollableSource主要用于接收外部驱动程序的Events,比如来自Kafka的消息等,而其他source基本都是实现于EventDrivenSource,这种source不需要外部的驱动程序pollEvents,而是有自己的事件监控获得Events,比如SpoolDirectorySource,它可以从磁盘中某个文件获取文件更新数据。
以SpoolDirectorySource为例,其创建启动过程如下:
第一步:Application主线程启动的时候,通过AbstractConfigurationProvider(前面提到的PollingPropertiesFileConfigurationProvider的父类)获取配置信息
第二步:当判断配置为SpoolDirectorySource时,则通过SourceFactory实例化一个SpoolDirectorySource
第三步:AbstractConfigurationProvider调用实例化的SpoolDirectorySource对象的configure()进行初始化配置
第四步:Application主线程通过SpoolDirectoryRunnable(SpoolDirectorySource的内部类)启动source并且500毫秒执行一次

注:Application.startAllComponents()启动source的时候其实最先启动的是SourceRunner,Flume有两类SourceRunner:EventDrivenSourceRunner和PollableSourceRunner,EventDrivenSourceRunner再启动具体类型的source。
Sink分析
Sink从Channel消费Event,然后进行转移到收集/聚合层或存储层,它的启动过程和source类似是从Application的main主线程开始的,通过AbstractConfigurationProvider获取配置信息,然后通过SinkFactory实例化具体Sink,然后调用sink实例的configure进行实例的初始化配置,最后通过SinkRunner启动Sink实例。
和Source不同的是SinkRunner不直接启动Sink实例,而是通过SinkProcessor异步启动的。

SinkProcessor主要有三种:
l DefaultSinkProcessor:默认实现,用于单个Sink的场景使用
l FailoverSinkProcessor:故障转移实现
l LoadBalanceSinkProcessor:用于实现Sink的负载均衡
其类的继承关系如图所示:
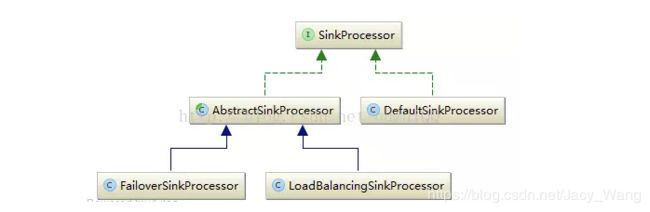
多个Sink可以构成一个SinkGroup。一个Sink Processor负责从一个指定的Sink Group中激活一个Sink。Sink Processor可以通过组中所有Sink实现负载均衡;也可以在一个Sink失败时转移到另一个。
• Flume通过Sink Processor实现负载均衡(Load Balancing)和故障转移(failover)
• 内建的SinkProcessors:
• Load Balancing Sink Processor – 使用RANDOM, ROUND_ROBIN或定制的选择算法
• Failover Sink Processor
• Default Sink Processor(单Sink)
所有的Sink都是采取轮询(polling)的方式从Channel上获取events。这个动作是通过SinkRunner激活的
• 负载均衡配置示例
a1.sinkgroups =g1
a1.sinkgroups.g1.sinks= k1 k2
a1.sinkgroups.g1.processor.type= load_balance
a1.sinkgroups.g1.processor.backoff= true
a1.sinkgroups.g1.processor.selector= random
• 失败重试配置示例
a1.sinkgroups =g1
a1.sinkgroups.g1.sinks= k1 k2
a1.sinkgroups.g1.processor.type= failover
a1.sinkgroups.g1.processor.priority.k1= 5
a1.sinkgroups.g1.processor.priority.k2= 10
a1.sinkgroups.g1.processor.maxpenalty= 10000
Flume拦截器
有的时候希望通过Flume将读取的文件再细分存储,比如讲source的数据按照业务类型分开存储,具体一点比如类似:将source中web、wap、media等的内容分开存储;比如丢弃或修改一些数据。这时可以考虑使用拦截器Interceptor。
flume通过拦截器实现修改和丢弃事件的功能。拦截器通过定义类继承org.apache.flume.interceptor.Interceptor接口来实现。用户可以通过该节点定义规则来修改或者丢弃事件。Flume支持链式拦截,通过在配置中指定构建的拦截器类的名称。在source的配置中,拦截器被指定为一个以空格为间隔的列表。拦截器按照指定的顺序调用。一个拦截器返回的事件列表被传递到链中的下一个拦截器。当一个拦截器要丢弃某些事件时,拦截器只需要在返回事件列表时不返回该事件即可。若拦截器要丢弃所有事件,则其返回一个空的事件列表即可。
先解释一下一个重要对象Event:event是flume传输的最小对象,从source获取数据后会先封装成event,然后将event发送到channel,sink从channel拿event消费。event由头(Map
Flume-NG自带拦截器有多种:
1、HostInterceptor:使用IP或者hostname拦截;
2、TimestampInterceptor:使用时间戳拦截;
3、RegexExtractorInterceptor:该拦截器提取正则表达式匹配组,通过使用指定的正则表达式并追加匹配组作为事件的header。它还支持可插拔的serializers用于在添加匹配组作为事件header之前格式化匹配组;
4、RegexFilteringInterceptor:该拦截器会选择性地过滤事件。通过以文本的方式解析事件主体,用配置好的规则表达式来匹配文本。提供的正则表达式可以用于包含事件或排除事件;这个和上面的那个区别是这个会按照正则表达式选择性的让event通过,上面那个是提取event.body符合正则的内容作为headers的value。
5、StaticInterceptor:可以自定义event的header的value。
这些类都在org.apache.flume.interceptor包下。
这些interceptor都比较简单我们选取HostInterceptor来讲解interceptor的原理,以及如何自己定制interceptor。
这些interceptor都实现了org.apache.flume.interceptor.Interceptor接口,该接口有四个方法以及一个内部接口:
1、public void initialize()运行前的初始化,一般不需要实现(上面的几个都没实现这个方法);
2、public Event intercept(Event event)处理单个event;
3、public List intercept(List events)批量处理event,实际上市循环调用上面的2;
4、public void close()可以做一些清理工作,上面几个也都没有实现这个方法;
5、 public interface Builder extends Configurable 构建Interceptor对象,外部使用这个Builder来获取Interceptor对象。
如果要自己定制,必须要完成上面的2,3,5。
下面,我们来看看org.apache.flume.interceptor.HostInterceptor,其全部代码如下:
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flume.interceptor;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.List;
import java.util.Map;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import static org.apache.flume.interceptor.HostInterceptor.Constants.*;
/**
* Simple Interceptor class that sets the host name or IP on all events
* that are intercepted.
* The host header is named host and its format is either the FQDN
* or IP of the host on which this interceptor is run.
*
*
* Properties:
*
* preserveExisting: Whether to preserve an existing value for 'host'
* (default is false)
*
* useIP: Whether to use IP address or fully-qualified hostname for 'host'
* header value (default is true)
*
* hostHeader: Specify the key to be used in the event header map for the
* host name. (default is "host")
*
* Sample config:
*
*
* agent.sources.r1.channels = c1
* agent.sources.r1.type = SEQ
* agent.sources.r1.interceptors = i1
* agent.sources.r1.interceptors.i1.type = host
* agent.sources.r1.interceptors.i1.preserveExisting = true
* agent.sources.r1.interceptors.i1.useIP = false
* agent.sources.r1.interceptors.i1.hostHeader = hostname
*
*
*/
public class HostInterceptor implements Interceptor {
private static final Logger logger = LoggerFactory
.getLogger(HostInterceptor.class);
private final boolean preserveExisting;
private final String header;
private String host = null;
/**
* Only {@link HostInterceptor.Builder} can build me
*/
private HostInterceptor(boolean preserveExisting,
boolean useIP, String header) {
this.preserveExisting = preserveExisting;
this.header = header;
InetAddress addr;
try {
addr = InetAddress.getLocalHost();
if (useIP) {
host = addr.getHostAddress();
} else {
host = addr.getCanonicalHostName();
}
} catch (UnknownHostException e) {
logger.warn("Could not get local host address. Exception follows.", e);
}
}
@Override
public void initialize() {
// no-op
}
/**
* Modifies events in-place.
*/
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
if (preserveExisting && headers.containsKey(header)) {
return event;
}
if(host != null) {
headers.put(header, host);
}
return event;
}
/**
* Delegates to {@link #intercept(Event)} in a loop.
* @param events
* @return
*/
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() {
// no-op
}
/**
* Builder which builds new instances of the HostInterceptor.
*/
public static class Builder implements Interceptor.Builder {
private boolean preserveExisting = PRESERVE_DFLT;
private boolean useIP = USE_IP_DFLT;
private String header = HOST;
@Override
public Interceptor build() {
return new HostInterceptor(preserveExisting, useIP, header);
}
@Override
public void configure(Context context) {
preserveExisting = context.getBoolean(PRESERVE, PRESERVE_DFLT);
useIP = context.getBoolean(USE_IP, USE_IP_DFLT);
header = context.getString(HOST_HEADER, HOST);
}
}
public static class Constants {
public static String HOST = "host";
public static String PRESERVE = "preserveExisting";
public static boolean PRESERVE_DFLT = false;
public static String USE_IP = "useIP";
public static boolean USE_IP_DFLT = true;
public static String HOST_HEADER = "hostHeader";
}
}
Constants类是参数类及默认的一些参数:
Builder类是构造HostInterceptor对象的,它会首先通过configure(Context context)方法获取配置文件中interceptor的参数,然后方法build()用来返回一个HostInterceptor对象:
1、preserveExisting表示如果event的header中包含有本interceptor指定的header,是否要保留这个header,true则保留;
2、useIP表示是否使用本机IP地址作为header的value,true则使用IP,默认是true;
3、header是event的headers的key,默认是host。
HostInterceptor:
1、构造函数除了赋值外,还有就是根据useIP获取IP或者hostname;
2、intercept(Event event)方法是设置event的header的地方,首先是获取headers对象,然后如果同时满足preserveExisting==true并且headers.containsKey(header)就直接返回event,否则设置headers:headers.put(header, host)。
3、intercept(List events)方法是循环调用上述2的方法。
显然其他几个Interceptor也就类似这样。在配置文件中配置source的interceptor时,如果是自己定制的interceptor,则需要对type参数赋值:完整类名+¥Builder,比如com.MyInterceptor$Builder即可。
这样设置好headers后,就可以在后续的流转中通过selector实现细分存储。