探索weka实现中文文本分类
探索weka实现中文文本分类
总体思路:
主要流程:
1. 从网上搜寻中文文本分类数据集
2. 使用python-jieba库对所搜集的中文文本数据集进行分词操作,并存储为txt文本
3. 将txt通过excel转换成cvs文件
4. 在weka中进行数据预处理后进行分类学习并预测,比较各个参数以及函数对正确率的影响
主要实现流程
-
下载数据集,下载地址给出:链接:https://pan.baidu.com/s/1jyTis9z9D8FNU7khO7k0VA 密码:rgy5
-
使用python-jieba库进行分词操作:
下面给出代码:相关解释见注释
#!/usr/bin/python ####!!!编码要改成utf-8以支持中文 # -*- coding: utf-8 -*- #coding=utf-8 #所处理的文本目录结构如下 #data # -sports # -1.txt # -2.txt # -... # -campus # -female # -literature #共分为四个大类:运动+校园+女性+文学,每个文件夹下有几百个txt文件,下面的程序对某个文件夹进行分词并存储在相应的汇总txt文件中 from jieba import * import os.path import time #重文件描述符中读出文本并执行默认的精确切割,返回分词后的字符串 def jieba_cut(f): seg_list = cut(f.read()) return " ".join(seg_list).encode("utf-8") pathDir = os.listdir("./sport") #执行不同文件夹,这三个参数需要修改 target_file = open("./sport.txt","w") #执行不同文件夹,这三个参数需要修改 #对目标文件夹中的每个文件都进行分词操作 for afile in pathDir: f = open("./sport/"+afile, "r") #执行不同文件夹,这三个参数需要修改 text = jieba_cut(f)+"\n" target_file.write(text) print "done!"给出分词后txt文本样例:
Campus.txt
93 焦点 【 温州 再现 “ 黑 校车 ” 】 近日 , 温州 柳市 交警 中队 查获 2 辆 超载 学生 接送车 : 【 浙 CEY041 】 核载 19 人 , 却 坐 了 45 名 学生 , 属于 严重 超载 。 【 浙 CE6586 】 核载 19 人 , 却 坐 了 33 名 学生 。 这 两辆 校车 分别 属于 柳 市民 工子弟 学校 和 柳市 前进 希望 小学 两 所 学校 。 据悉 , “ 民办学校 ” 、 “ 黑校 ” 无证 校车 普遍 超载 。 $ LOTOzf $ 新闻晨报 【 北大 规定 校内 停止 售烟 , 教职工 不得 在 学生 前 吸烟 】 曹一 漫画 : 北大 带 了 个 好头 , 比 “ 烟草 院士 ” 那 档子 事儿 强多 了 。 支持 一下 。 吸烟 是 个人 选择 , 不 危害 公共 健康 , 躲 着 吸烟区 偷着乐 呵 也 蛮 好 的 。 可 这年头 叼 着 烟斗 装 “ 大师 ” 的 也 不少 , 若 无 真才实学 , 恐怕 也 装不像 。 $ LOTOzf $ 转发 微博 鞋带 : 最新 统计 显示 中国 留学生 一年 为 美国 经济 至少 贡献 了 44 亿美元 , 随着 留学 热 愈演愈烈 , 留学生 群体 成为 人们 关注 的 焦点 。 我国 留学生 出现 越来越 低龄 的 趋势 , 国内 高中 纷纷 开设 专门 的 出国 班 , 参加 “ 美国 高考 ” 的 中国 学生 也 大幅 增加 。 2010 年 高考 弃考 人数 接近 100 万 , 其中 因 出国 留学 而 选择 弃 考者 比例 达 211 。 原文 转发 原文 评论Sports.txt
【 进球 视频 : 朴智星 突破 赢 点球 潇洒 哥 罚进 戴帽 】 CC 英超 国际足球 http : url . cn / 0xrsz 收起 进球 视频 : 朴智星 突破 赢 点球 潇洒 哥 罚进 戴 ... $ LOTOzf $ 经过 5 天 75 场 激战 , 2011 年 世界 羽联 超级 赛 总决赛 于 18 日 在 柳州 落幕 。 5 个 单项 顶尖高手 间 的 对决 , 首次 尽遣 主力 的 东道主 中国 军团 创 历届 最好 成绩 , 夺得 除 男双 以外 的 4 枚 金牌 。 林丹 、 王仪涵 分别 加冕 男女 单打 冠军 。 王晓理 / 于洋 、 张楠 / 赵芸蕾 分别 夺取 女双 和 混双 冠军 。 柴飚 / 郭振东 获得 男双 银牌 ( 新浪 ) 大麦 娱乐 $ LOTOzf $ 我 明白 nba 为什么 炒作 科比 , 炒作 詹姆斯 , 甚至 炒作 姚明 。 但是 国内 的 这些 主持人 无端 的 炒作 这些 人 。 得到 什么 , 得到 nba 征服 中国 球迷 的 心 。 与 我 篮球 发展 何关 。 乔丹 之后 , nba 一直 没有 找到 能够 接替 他 的 人 。 $ LOTOzf $ NBAhttp : url . cn / 3eubFs NBA 的 视频 直播 , 有 兴趣 的 朋友 看看 $ LOTOzf $ 对 寒冷 说 不 冬天 的 球场 也 能 成为 挥洒 汗水 的 地方 “ 反季节 联赛 ” 吴悠 : : 2011 反季节 联赛 第一周 高清 图片 摄影师 : 阿樊 : 8 樊 喜儿 她 爸 : 反季节 联赛 首周 图片 集锦 , 四支 队伍 激情 撞色 转发 ( 43 ) 评论 ( 9 ) 12 月 12 日 12 : 15 来自 新浪 微博 还是 娄 老师 专业 娄一晨 : 今日 温网 对阵 : 20 : 00 中央 球场 索 德林 休伊特 , 李娜 利希茨基 ( 德国 ) , 曼纳里诺 ( 法国 ) 费德勒 。 1 号 球场 安德森 ( 南非 ) 德约 科维奇 。 2 号 球场 第 5 场 巴尔塔 哈 ( 英国 ) 彭帅 。 16 号 球场 第 2 场 郑洁 土居 美咲 ( 日本 ) 。 : 其中 李娜 的 比赛 时间 可能 与 中国国奥队 冲突 。 五星 体育 : : 9 纳达尔 斗士 神勇 、 费德勒 天王 不老 、 德约 科维奇 红星 闪耀 、 穆雷 主场 欲 谱 新篇 6 月 20 日 7 月 3 日 , 2011 温布尔 顿 网球 公开赛 , 五星 体育文本比较乱,下面在excel中处理成cvs文件,并去除无关痛痒的符号
-
txt转化cvs
方法有很多,在网上还可以搜索到相应的脚本。我使用的方式是通过excel分割符来实现转化,下面展示cvs文件样例:
汇总后的样本集共有3312例样本
text,label 科比 : 交易 奥多姆 我 不爽 谢天谢地 加索尔 没 走 http : url . cn / 1orJGW 有点 意思 真是 为 小牛 填瓦 虽然 奥多姆 有时候 有点 头脑发热 但是 真正 打球 认真 起来 的 能力 还是 足以 比肩 一流 球星 现在 小牛 这笔 交易 赚 了 现在 就 看 湖人 能否 得到 霍华德 或者 保罗 否则 他们 等于 帮 小牛 卫冕 增加 筹码 自己 却 一无所得 $ LOTOzf $,sports 旅游 卫视 本 周五 直播 2011 中国 - 亚太 对抗赛 中国队 梁文冲 领衔 12 名 顶尖 球员 迎战 亚太 队 ! 实力 选手 角逐 首届 东风 日产 杯 精彩 值得 期待 请 关注 旅游 卫视 直播 ! 12 月 16 日 - 18 日 每天 13 : 00 - 16 : 00 东风 日产 杯 中国 - 亚太 对抗 旅游 卫视 官方 微博 $ LOTOzf $,sports ... ... ... -
weka中进行预处理
a. 打开weka后,点击右上角的explorer
b. 在explorer中打开之前编辑好的cvs文件:
这里有可能出现几个问题:
-
文本没有进行逗号和引号的过滤,由于cvs中会使用到这两个符号作为划分,因此文本中不能带有这两个符号,可以使用excel替换功能即可
-
要保证数据是一个“矩形”,不能有数据空缺,在excel中,数据必须是完整举行,不能多一块少一块
-
weka不支持中文导致中文乱码,在windows中找到runweda.ini修改如图:

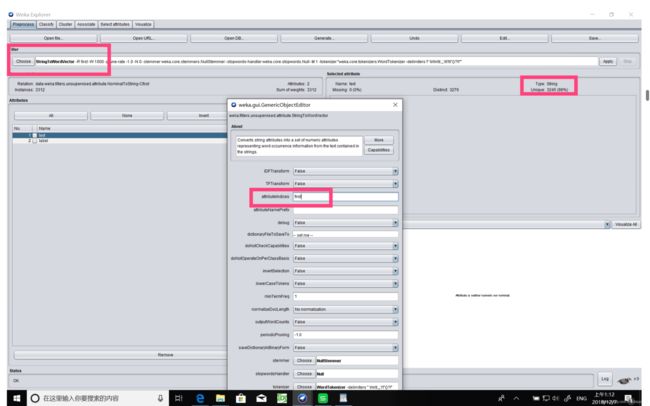
c. 刚打开的cvs文件其中我们所需处理的文本的类型为nominal,需要通过filter将其先转成string,再转化成word_vector(词向量)

weka自带的filter默认是没有string库的,需要手动在filter中添加上:
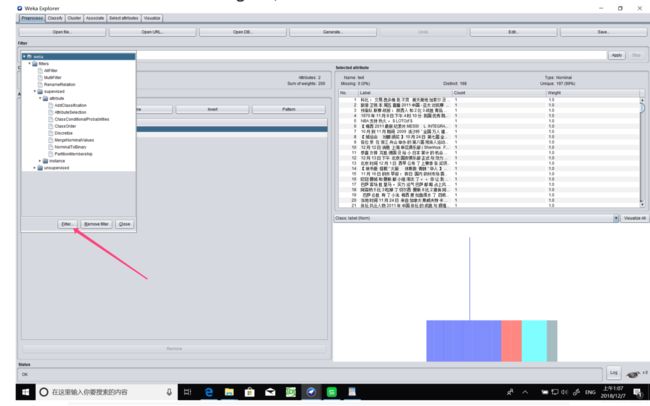
先在filter中添加上关于string的filter
然后在weka/filters/unsupervised/attribute/中找到nominaltostring,然后设置需要进行filter的attributes:
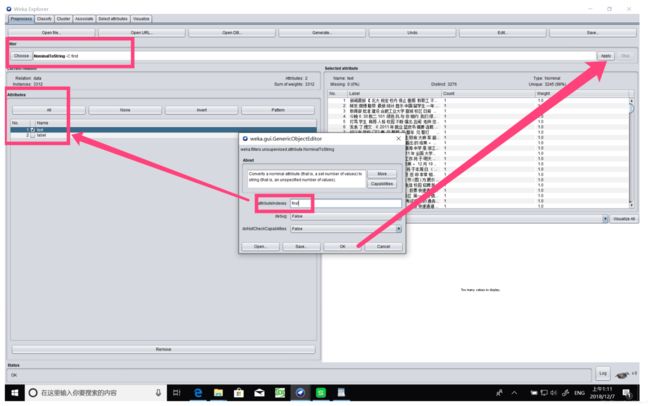 通过上述操作,文本类型已经变成了string,再进行filter操作,将其变成word_vector:
通过上述操作,文本类型已经变成了string,再进行filter操作,将其变成word_vector:
预处理最终效果为:
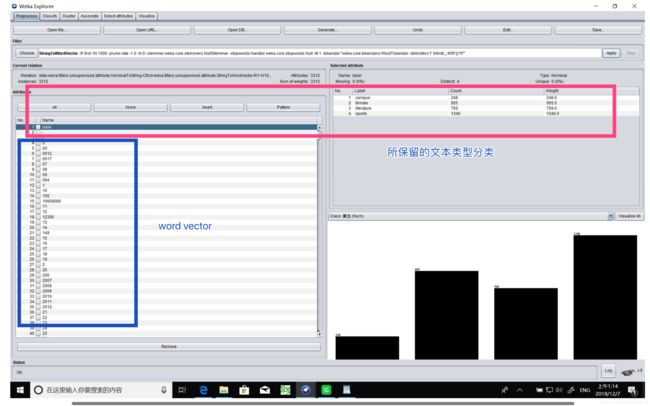
感觉这里的数字是没什么软用的。。其实可以过滤掉
进行文本分类并预测、评估正确率!
结果展示:(结果汇总及分析在后面)
试验方法:十折交叉验证英文名叫做10-fold cross-validation,用来测试算法准确性。是常用的测试方法。将数据集分成十分,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率(或差错率)。
bayesnet:
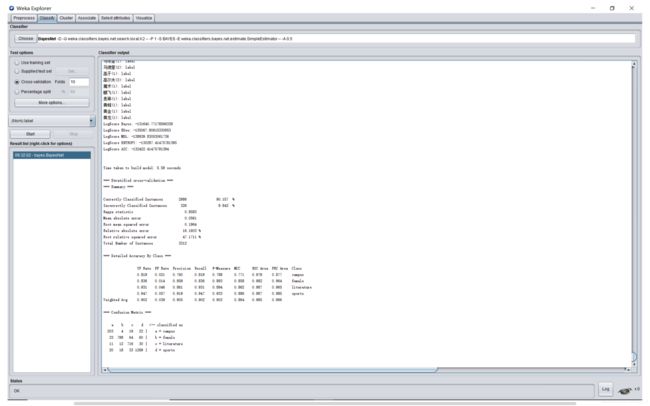
第一个就有不错的正确率喔
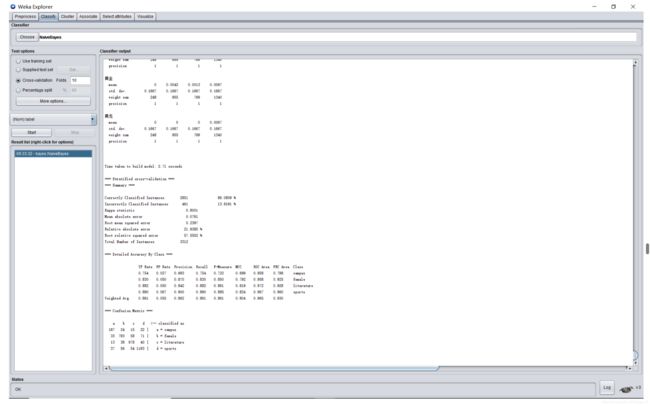
NaiveBayes:
SMO(SVM):
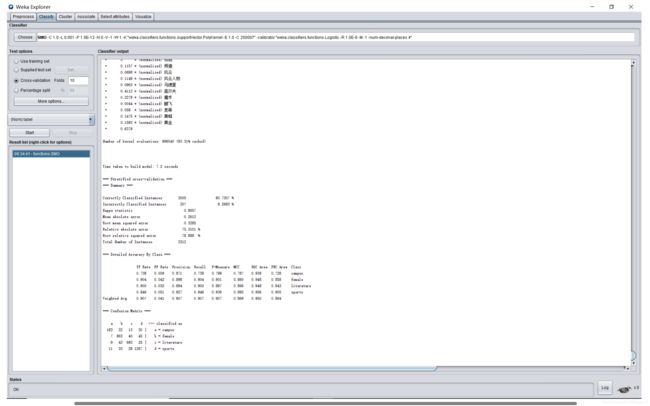
IBK(KNN)(k=1):
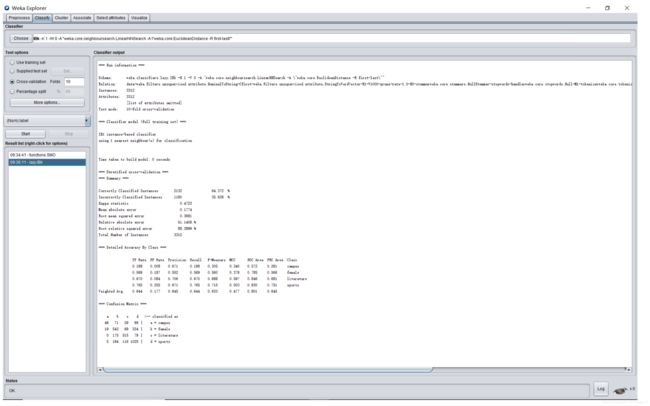
AdaBoostM1: 耗时久、准确度低

AttributeSelectedClassifier:耗时久、准确度低

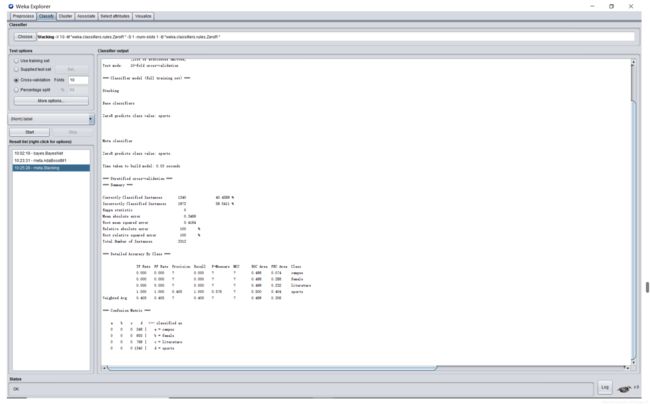
Stacking:
OneR:

ZeroR:
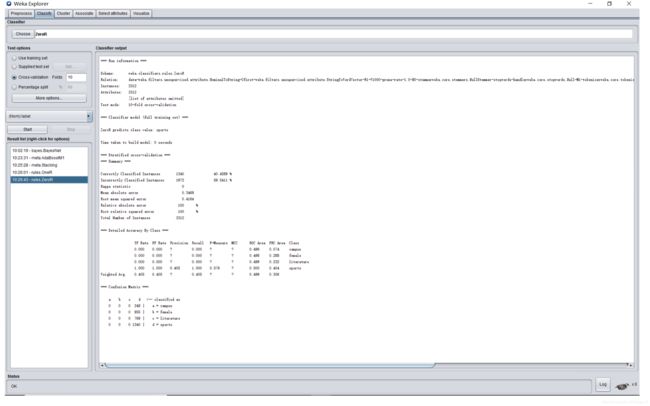
为什么ZeroR和Stacking的数据一模一样。。?有大神解疑吗
J48: 二叉决策树,耗时很久这个
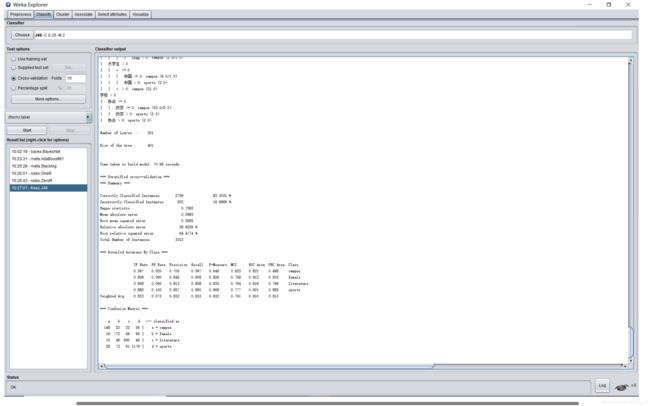
RandomForest:
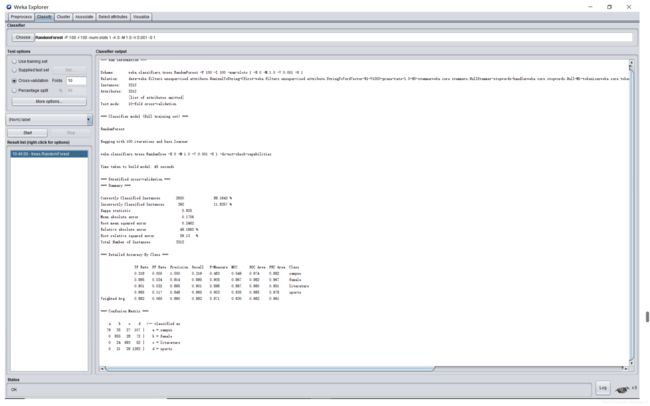
实验结果与分析
1. 数据集的66%作为训练集,33%作为测试集(也做了2:1的测试实验,比十折的实验快很多,把数据也放上来吧)
| Correctly Classified Percentage | kappa | Root mean squared error | Root relative squared error | |
|---|---|---|---|---|
| bayesnet | 88.45% | 0.8332 | 0.2133 | 51.23% |
| naivebayes | 85.35% | 0.7895 | 0.2446 | 58.76% |
| knn(k=1)(ibk in weka) | 62.70% | 0.4397 | 0.3932 | 94.44% |
| AdaBoostM1 | 51.07% | 0.2329 | 0.3885 | 93.31% |
| AttributeSelectedClassifier | 75.49% | 0.6339 | 0.2786 | 66.91% |
| Stacking | 40.68% | 0 | 0.4163 | 100% |
| OneR | 51.07% | 0.2333 | 0.4946 | 118.81% |
| ZeroR | 40.68% | 0 | 0.4163 | 100% |
| J48 | 83.13% | 0.7536 | 0.265 | 63.66% |
| RandomForest | 87.12% | 0.8086 | 0.2558 | 61% |
| SMO(SVM) | 89.70% | 0.85 | 0.3322 | 79.80% |
| 参数说明: | |
|---|---|
| Correctly Classified Percentage | 正确分类百分比 |
| kappa | 内部一致性系数(inter-rater,coefficient of internal consistency),是作为评价判断的一致性程度的重要指标。取值在0~1之间。Kappa≥0.75两者一致性较好;0.75>Kappa≥0.4两者一致性一般;Kappa<0.4两者一致性较差 |
| Root mean squared error | 标准差 |
| Root relative squared error | 把N次实验的绝对误差求和,然后除以实际值与均值之差的求和再开根号. 此值越小实验越准确. |
2. 十折交叉验证法,将数据集分成10份,其中9份作为训练集,1份作为测试集,进行10次实验后取平均值
| Correctly Classified Percentage | kappa | Root mean squared error | Root relative squared error | |
|---|---|---|---|---|
| bayesnet | 90.16% | 0.8583 | 0.1964 | 47.17% |
| naivebayes | 86.08% | 0.8001 | 0.2397 | 57.56% |
| knn(k=1)(ibk in weka) | 64.37% | 0.4723 | 0.3681 | 88.39% |
| AdaBoostM1 | 52.60% | 0.2575 | 0.3847 | 92.38% |
| AttributeSelectedClassifier | 77.32% | 0.6702 | 0.2789 | 66.98% |
| Stacking | 40.46% | 0 | 0.4164 | 100% |
| OneR | 52.60% | 0.2577 | 0.4868 | 116.91% |
| ZeroR | 40.46% | 0 | 0.4164 | 100% |
| J48 | 83.30% | 0.7582 | 0.2685 | 64.48% |
| RandomForest | 88.16% | 0.825 | 0.2462 | 59.13% |
| SMO(SVM) | 90.73% | 0.8657 | 0.3285 | 78.89% |
| 参数说明: | |
|---|---|
| Correctly Classified Percentage | 正确分类百分比 |
| kappa | 内部一致性系数(inter-rater,coefficient of internal consistency),是作为评价判断的一致性程度的重要指标。取值在0~1之间。Kappa≥0.75两者一致性较好;0.75>Kappa≥0.4两者一致性一般;Kappa<0.4两者一致性较差 |
| Root mean squared error | 标准差 |
| Root relative squared error | 把N次实验的绝对误差求和,然后除以实际值与均值之差的求和再开根号. 此值越小实验越准确. |
实验分析:
-
试验一与试验二的实验结果区别不大,以下以试验二的结果讨论。十折交叉验证法,用来测试算法准确性,是常用的测试方法。
-
在本实验中,综合来看,贝叶斯、决策二叉树、序列最小优化算法(英语:Sequential minimal optimization, SMO)的准确率都比较高,但贝叶斯算法在误差控制上具有明显的优势,SMO算法在算法执行速度上具有优势,但误差较大,决策二叉树方法的准确率、误差控制都不及SMO算法。
-
关于序列最小优化算法(英语:Sequential minimal optimization, SMO),上述实验数据的核函数为 POLY:多项式核函数(ploynomial kernel),下面探索不同的核函数对SMO结果的影响:
a. RBF:径向机核函数(radical basis function)
径向基函数 (Radial Basis Function 简称 RBF), 就是某种沿径向对称的标量函数。 通常定义为空间中任一点x到某
一中心xc之间欧氏距离的单调函数 ,可记作 k(||x-xc||), 其作用往往是局部的 , 即当x远离xc时函数取值很小。
最常用的径向基函数是高斯核函数 ,形式为 k(||x-xc||)=exp{- ||x-xc||2/(2*σ)2) } 其中x_c为核函数中心,σ为函数的宽度参数 , 控制了函数的径向作用范围。如果x和x_c很相近那么核函数值为1,如果x和x_c相差很大那么核函数值约等于0。由于这个函数类似于高斯分布,因此称为高斯核函数,也叫做径向基函数(Radial Basis Function 简称RBF)。它能够把原始特征映射到无穷维。
 b. Puk kernel
b. Puk kernel
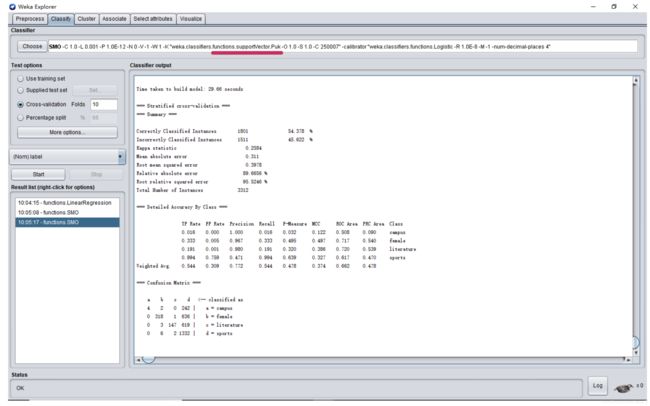 可以看到,不同的核函数对结果的影响十分巨大,经过比较,当核函数为 POLY:多项式核函数(ploynomial kernel),可以得到较高的准确率
可以看到,不同的核函数对结果的影响十分巨大,经过比较,当核函数为 POLY:多项式核函数(ploynomial kernel),可以得到较高的准确率
-
对于knn(k=1)(ibk in weka)分析:(不知道分析的对不对,如有错误请指正)
在Weka分类器中有一类Lazy Classifier分类器。相对对其它的Inductive Learning的算法来说,lazy Learning的方法在训练是仅仅是保存样本集的信息,直到测试样本到达是才进行分类决策。也就是说这个决策的模型是在测试样本到来以后才生成的。相对与其它的分类算法来说,这类的分类算法可以根据每个测试样本的样本信息来学习模型,这样的学习模型可能更好好的拟合局部的样本特性。
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量 很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。因此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。该方法 的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样 本点进行剪辑,事先去除对分类作用不大的样本。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
本次的训练样本中,由于每个类的样本容量不平均,导致knn的正确率下降。如下图,可以看到由于运动的样本数量很多,而校园的样本数量较少,导致校园样本的k个邻居中其他三类样本占大多数。随着k增加,样本分类产生错误的几率也随之增加,这是上面实验结果中k=1,2,3,4,5中k越大,准确度越低的原因。
-
关于naivebayes:
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法 [1] 。最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBM)。
和决策树模型相比,朴素贝叶斯分类器(Naive Bayes Classifier,或 NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响.
参考文献:
- https://blog.csdn.net/huang1024rui/article/details/51510611
- http://blog.sina.com.cn/s/blog_626896c10101iksv.html
- https://baike.baidu.com/item/朴素贝叶斯/4925905?fr=aladdin
- http://www.cnblogs.com/flippedkiki/p/7209076.html?utm_source=itdadao&utm_medium=referral